Se sua infraestrutura de TI estiver sendo executada na AWS, você provavelmente já ouviu falar do Amazon Relational Database Service (RDS), uma maneira fácil de configurar, operar e dimensionar um banco de dados relacional na nuvem. Ele fornece capacidade econômica e redimensionável enquanto automatiza tarefas de administração demoradas, como provisionamento de hardware, configuração de banco de dados, aplicação de patches e backups. Existem várias ofertas de mecanismos de banco de dados para RDS, como MySQL, MariaDB, PostgreSQL, Microsoft SQL Server e Oracle Server.
O ClusterControl 1.7.3 atua de maneira semelhante ao RDS, pois oferece suporte à implantação, gerenciamento, monitoramento e dimensionamento de cluster de banco de dados na plataforma AWS. Ele também suporta várias outras plataformas de nuvem, como Google Cloud Platform e Microsoft Azure. O ClusterControl entende a topologia do banco de dados e é capaz de realizar recuperação automática, gerenciamento de topologia e muitos outros recursos avançados para controlar seu banco de dados.
Nesta postagem do blog, vamos comparar os tempos de failover automático para Amazon Aurora, Amazon RDS for MySQL e uma configuração de Replicação MySQL implantada e gerenciada pelo ClusterControl. O tipo de failover que vamos fazer é a promoção do slave caso o master fique inativo. É aqui que o escravo mais atualizado assume a função de mestre no cluster para retomar o serviço de banco de dados.
Nosso teste de failover
Para medir o tempo de failover, vamos executar um teste simples de atualização de conexão do MySQL, com um loop para contar o status da instrução SQL que se conecta a um único ponto de extremidade do banco de dados. O script fica assim:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
O script Bash acima simplesmente se conecta a um host MySQL e executa uma atualização em uma única linha com um tempo limite de 1 segundo nos comandos do cliente Bash e mysql. Os parâmetros relacionados aos tempos limite são necessários para que possamos medir o tempo de inatividade em segundos corretamente, já que o padrão do cliente mysql é sempre reconectar até atingir o MySQL wait_timeout. Preenchemos um conjunto de dados de teste com o seguinte comando antecipadamente:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareO script informa se a consulta acima foi bem-sucedida (OK) ou falhou (Fail). As saídas de amostra são mostradas mais abaixo.
Failover com Amazon RDS para MySQL
Em nosso teste, usamos a oferta de RDS mais baixa com as seguintes especificações:
- Versão do MySQL:5.7.22
- vCPU:4
- RAM:16 GB
- Tipo de armazenamento:IOPS provisionado (SSD)
- IOPS:1.000
- Armazenamento:100 Gib
- Replicação Multi-AZ:Sim
Depois que o Amazon RDS provisionar sua instância de banco de dados, você poderá usar qualquer aplicativo ou utilitário cliente MySQL padrão para se conectar à instância. Na string de conexão, você especifica o endereço DNS do endpoint da instância de banco de dados como o parâmetro de host e especifica o número da porta do endpoint da instância de banco de dados como o parâmetro de porta.
De acordo com a página de documentação do Amazon RDS, no caso de uma interrupção planejada ou não planejada de sua instância de banco de dados, o Amazon RDS alterna automaticamente para uma réplica em espera em outra zona de disponibilidade se você tiver ativado o Multi-AZ. O tempo que leva para o failover ser concluído depende da atividade do banco de dados e de outras condições no momento em que a instância de banco de dados primária ficou indisponível. Os tempos de failover são normalmente de 60 a 120 segundos.
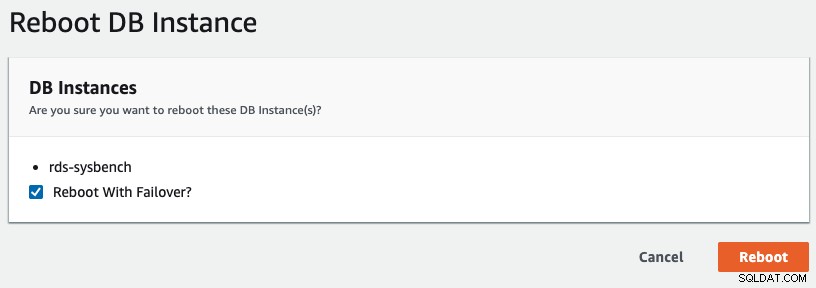
Para iniciar um failover multi-AZ no RDS, realizamos uma operação de reinicialização com "Reboot with Failover" marcado, conforme mostrado na captura de tela a seguir:
Segue o que está sendo observado pelo nosso aplicativo:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...O tempo de inatividade do MySQL, visto pelo lado do aplicativo, foi iniciado de 03:41:09 até 03:41:36, o que equivale a cerca de 27 segundos no total. Nos eventos do RDS, podemos ver que o failover multi-AZ aconteceu apenas 15 segundos após o tempo de inatividade real:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.Depois que a nova instância de banco de dados foi reiniciada por volta das 03:41:33, o serviço MySQL ficou acessível cerca de 3 segundos depois.
Failover com Amazon Aurora para MySQL
O Amazon Aurora pode ser considerado uma versão superior do RDS, com muitos recursos notáveis, como replicação mais rápida com armazenamento compartilhado, sem perda de dados durante o failover e até 64 TB de limite de armazenamento. O Amazon Aurora para MySQL é baseado no MySQL Edition de código aberto, mas não é de código aberto por si só; é um banco de dados proprietário e de código fechado. Funciona de maneira semelhante com a replicação do MySQL (um e apenas um mestre, com vários escravos) e o failover é tratado automaticamente pelo Amazon Aurora.
De acordo com as perguntas frequentes do Amazon Aurora, se você tiver uma réplica do Amazon Aurora, na mesma ou em uma zona de disponibilidade diferente, ao fazer failover, o Aurora inverte o registro de nome canônico (CNAME) da sua instância de banco de dados para apontar para a réplica íntegra, que está em turno é promovido para se tornar o novo primário. Do início ao fim, o failover geralmente é concluído em 30 segundos.
Se você não tiver uma réplica do Amazon Aurora (ou seja, instância única), o Aurora tentará primeiro criar uma nova instância de banco de dados na mesma zona de disponibilidade da instância original. Se não for possível, o Aurora tentará criar uma nova instância de banco de dados em uma zona de disponibilidade diferente. Do início ao fim, o failover normalmente é concluído em menos de 15 minutos.
Seu aplicativo deve tentar novamente as conexões de banco de dados em caso de perda de conexão.
Depois que o Amazon Aurora provisionar sua instância de banco de dados, você obterá dois endpoints, um para o gravador e outro para o leitor. O endpoint do leitor fornece suporte de balanceamento de carga para conexões somente leitura com o cluster de banco de dados. Os seguintes endpoints são retirados de nossa configuração de teste:
- escritor - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- leitor - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
Em nosso teste, usamos as seguintes especificações do Aurora:
- Tipo de instância:db.r5.large
- Versão do MySQL:5.7.12
- vCPU:2
- RAM:16 GB
- Replicação Multi-AZ:Sim
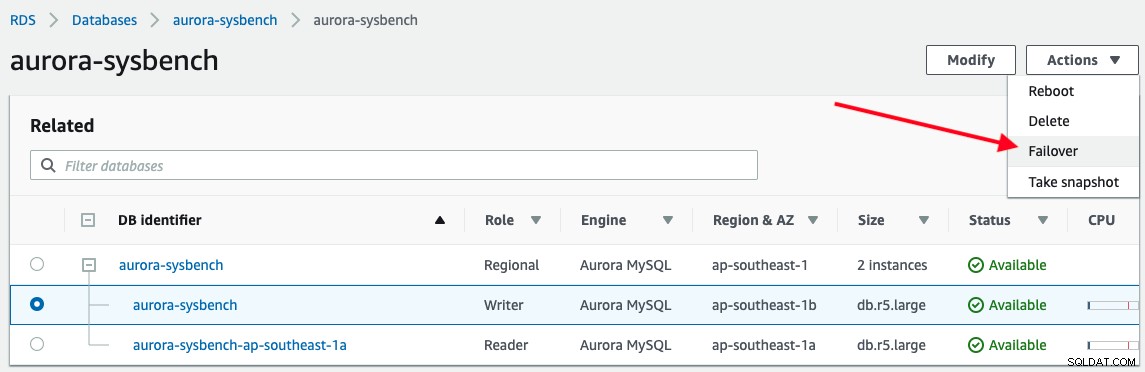
Para acionar um failover, basta escolher a instância do gravador -> Actions -> Failover, conforme mostrado na captura de tela a seguir:
A saída a seguir é relatada por nosso aplicativo durante a conexão com o endpoint do gravador do Aurora :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...O tempo de inatividade do banco de dados foi iniciado às 12:35:49 até 12:35:56 com um total de 7 segundos. Isso é bastante impressionante.
Observando o evento do banco de dados do console de gerenciamento do Aurora, apenas esses dois eventos aconteceram:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedNão leva muito tempo para Aurora promover um escravo para se tornar um mestre e rebaixar o mestre para se tornar um escravo. Observe que todas as réplicas do Aurora compartilham o mesmo volume subjacente com a instância primária e isso significa que a replicação pode ser executada em milissegundos, pois as atualizações feitas pela instância primária ficam instantaneamente disponíveis para todas as réplicas do Aurora. Portanto, ele tem um atraso de replicação mínimo (a Amazon afirmou ser de 100 milissegundos ou menos). Isso reduzirá bastante o tempo de verificação de integridade e melhorará significativamente o tempo de recuperação.
Failover com ClusterControl
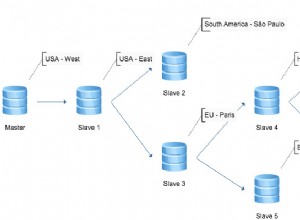
Neste exemplo, imitamos uma configuração semelhante com o Amazon RDS usando instâncias m5.xlarge, com um ProxySQL intermediário para automatizar o failover do aplicativo usando um único acesso ao endpoint, como o RDS. O diagrama a seguir ilustra nossa arquitetura:
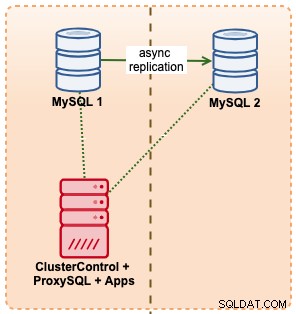
Como estamos tendo acesso direto às instâncias do banco de dados, acionaríamos um failover automático simplesmente matando o processo MySQL no mestre ativo:
$ kill -9 $(pidof mysqld)O comando acima acionou uma recuperação automática dentro do ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Do ponto de vista do nosso aplicativo de teste, o tempo de inatividade ocorreu no seguinte momento durante a conexão com a porta 6033 do host ProxySQL:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Observando os eventos do job de recuperação e a saída do nosso aplicativo, o nó do banco de dados MySQL ficou inativo 4 segundos antes do início do job de recuperação do cluster, das 11h08min28s às 11h08min39s, com tempo de inatividade total do MySQL de 11 segundos . Uma das coisas mais impressionantes do ClusterControl é que você pode acompanhar o progresso da recuperação sobre qual ação está sendo tomada e executada pelo ClusterControl durante o failover. Ele fornece um nível de transparência que você não poderá obter com nenhuma oferta de banco de dados de provedores de nuvem.
Para replicação MySQL/MariaDB/PostgreSQL, o ClusterControl permite que você tenha uma granulação mais refinada em seus bancos de dados com o suporte das seguintes configurações e parâmetros avançados:
- Gerenciamento de topologia de replicação mestre-mestre
- Gerenciamento de topologia de replicação de cadeia
- Visualizador de topologia
- Escravos da lista de permissões/listas negras serão promovidos como mestres
- Verificador de transações errôneas
- Eventos de pré/pós, sucesso/falha de failover/switchover gancho com script externo
- Reconstrução automática do escravo em caso de erro
- Redimensionar escravo do backup existente
Resumo do tempo de failover
Em termos de tempo de failover, o Amazon RDS Aurora for MySQL é o vencedor claro com 7 segundos , seguido por ClusterControl 11 segundos e Amazon RDS for MySQL com 27 segundos .
Observe que este é apenas um teste simples, com um cliente e uma transação por segundo para medir o tempo de recuperação mais rápido. Grandes transações ou um processo de recuperação demorado podem aumentar o tempo de failover, por exemplo, transações de longa execução podem levar muito tempo para serem revertidas ao desligar o MySQL.