O gerenciamento de memória no PostgreSQL é importante para melhorar o desempenho do servidor de banco de dados. O arquivo de configuração do PostgreSQL (postgres.conf) gerencia a configuração do servidor de banco de dados. Ele usa valores padrão dos parâmetros, mas podemos alterar esses valores para refletir melhor a carga de trabalho e o ambiente operacional.
Neste blog, abordaremos esses parâmetros relacionados à memória. Mas antes de começarmos, vamos dar uma olhada na arquitetura de memória no PostgreSQL.
Arquitetura de memória
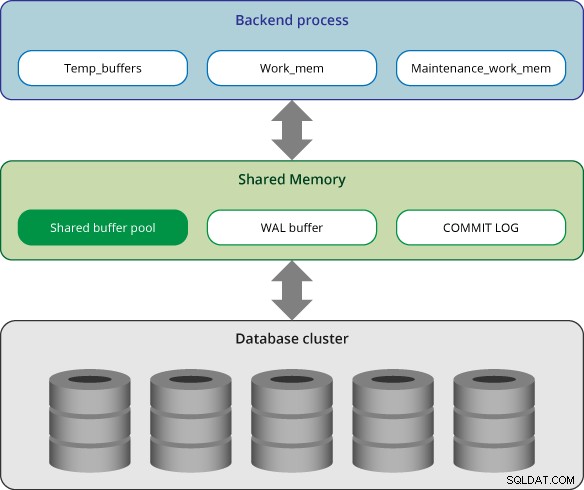
A memória no PostgreSQL pode ser classificada em duas categorias:
- Área de memória local:é alocada por cada processo de back-end para seu próprio uso.
- Área de memória compartilhada:é usada por todos os processos de um servidor PostgreSQL.
Área de memória local
No PostgreSQL, cada processo de backend aloca memória local para processamento de consultas; cada área é dividida em subáreas cujos tamanhos são fixos ou variáveis.
As subáreas são as seguintes.
Work_mem
O executor usa esta área para ordenar tuplas por operações ORDER BY e DISTINCT. Ele também o usa para unir tabelas por operações de junção de mesclagem e junção de hash.
Manutenção_trabalho_mem
Este parâmetro é utilizado para alguns tipos de operações de manutenção (VACUUM, REINDEX).
Temp_buffers
O executor utiliza esta área para armazenar tabelas temporárias.
Área de memória compartilhada
A área de memória compartilhada é alocada pelo servidor PostgreSQL quando ele é inicializado. Esta área está dividida em várias subáreas de tamanho fixo.
Pool de buffer compartilhado
O PostgreSQL carrega páginas dentro de tabelas e índices do armazenamento persistente para um buffer pool compartilhado e, em seguida, opera diretamente neles.
tampão WAL
O PostgreSQL suporta o mecanismo WAL (Write ahead log) para garantir que nenhum dado seja perdido após uma falha do servidor. Os dados WAL são realmente um log de transações no PostgreSQL e o buffer WAL é uma área de buffer dos dados WAL antes de gravá-los em um armazenamento persistente.
Registro de confirmação
O log de confirmação (CLOG) mantém os estados de todas as transações e faz parte do mecanismo de controle de simultaneidade. O log de confirmação é alocado para a memória compartilhada e usado durante todo o processamento da transação.
O PostgreSQL define os quatro estados de transação a seguir.
- IN_PROGRESS
- COMPROMETIDO
- ANULADO
- SUBCOMPROMETIDO
Ajustando os parâmetros de memória do PostgreSQL
Existem alguns parâmetros importantes que são recomendados para gerenciamento de memória no PostgreSQL. Você deve levar em conta o seguinte.
Shared_buffers
Este parâmetro designa a quantidade de memória usada para buffers de memória compartilhada. O parâmetro shared_buffers determina quanta memória é dedicada ao servidor para armazenar dados em cache. O valor padrão de shared_buffers é normalmente 128 megabytes (128 MB).
O valor padrão desse parâmetro é muito baixo porque em algumas plataformas, como versões mais antigas do Solaris e SGI, ter valores grandes requer uma ação invasiva, como recompilar o kernel. Mesmo nos sistemas Linux modernos, o kernel provavelmente não permitirá configurar shared_buffers para mais de 32 MB sem ajustar as configurações do kernel primeiro.
O mecanismo mudou no PostgreSQL 9.4 e posterior, então as configurações do kernel não precisarão ser ajustadas lá.
Se houver carga alta no servidor de banco de dados, definir um valor alto melhorará o desempenho.
Se você tiver um servidor de banco de dados dedicado com 1 GB ou mais de RAM, um valor inicial razoável para o parâmetro de configuração shared_buffer é 25% da memória em seu sistema.
Valor padrão de shared_buffers =128 MB. A mudança requer a reinicialização do servidor PostgreSQL.
A recomendação geral para definir os shared_buffers é a seguinte.
- Abaixo de 2 GB de memória, defina o valor de shared_buffers como 20% da memória total do sistema.
- Abaixo de 32 GB de memória, defina o valor de shared_buffers como 25% da memória total do sistema.
- Acima de 32 GB de memória, defina o valor de shared_buffers para 8 GB
Work_mem
Este parâmetro especifica a quantidade de memória a ser usada por operações de classificação interna e tabelas de hash antes de gravar em arquivos de disco temporários. Se muitas ordenações complexas estão acontecendo e você tem memória suficiente, então aumentar o parâmetro work_mem permite que o PostgreSQL faça ordenações maiores na memória que serão mais rápidas do que equivalentes baseados em disco.
Observe que, para uma consulta complexa, muitas operações de classificação ou hash podem ser executadas em paralelo. Cada operação terá permissão para usar tanta memória quanto esse valor especifica antes de começar a gravar dados nos arquivos temporários. Existe uma possibilidade de que várias sessões possam estar fazendo essas operações simultaneamente. Portanto, a memória total utilizada pode ser muitas vezes o valor do parâmetro work_mem.
Lembre-se disso ao escolher o valor certo. As operações de classificação são usadas para ORDER BY, DISTINCT e junções de mesclagem. As tabelas de hash são usadas em junções de hash, processamento baseado em hash de subconsultas IN e agregação baseada em hash.
O parâmetro log_temp_files pode ser usado para registrar ordenações, hashes e arquivos temporários que podem ser úteis para descobrir se as ordenações estão se espalhando para o disco em vez de caber na memória. Você pode verificar os tipos que se espalham para o disco usando os planos EXPLAIN ANALYZE. Por exemplo, na saída de EXPLAIN ANALYZE, se você vir a linha como:“Sort Method:external merge Disk:7528kB ”, um work_mem de pelo menos 8 MB manteria os dados intermediários na memória e melhoraria o tempo de resposta da consulta.
O valor padrão de work_mem =4 MB.
A recomendação geral para definir o work_mem é a seguinte.
- Comece com um valor baixo:32-64 MB
- Em seguida, procure as linhas de 'arquivo temporário' nos logs
- Definir como 2-3 vezes o maior arquivo temporário
manutenção _work_mem
Este parâmetro especifica a quantidade máxima de memória usada por operações de manutenção como VACUUM, CREATE INDEX e ALTER TABLE ADD FOREIGN KEY. Como apenas uma dessas operações pode ser executada por vez por uma sessão de banco de dados e uma instalação do PostgreSQL não possui muitas delas sendo executadas simultaneamente, é seguro definir o valor de maintenance_work_mem significativamente maior que work_mem.
Definir o valor maior pode melhorar o desempenho para limpar e restaurar dumps de banco de dados.
É necessário lembrar que quando o autovacuum é executado, até autovacuum_max_workers vezes essa memória pode ser alocada, portanto, tome cuidado para não definir o valor padrão muito alto.
O valor padrão de maintenance_work_mem =64 MB.
A recomendação geral para definir Maintenance_work_mem é a seguinte.
- Defina o valor de 10% da memória do sistema, até 1 GB
- Talvez você possa configurá-lo ainda mais se estiver com problemas de VACUUM
Effective_cache_size
O Effective_cache_size deve ser definido para uma estimativa de quanta memória está disponível para armazenamento em cache de disco pelo sistema operacional e no próprio banco de dados. Esta é uma diretriz para quanta memória você espera que esteja disponível no sistema operacional e nos caches de buffer do PostgreSQL, não uma alocação.
O planejador de consultas do PostgreSQL usa esse valor para descobrir se os planos que está considerando devem caber na RAM ou não. Se estiver definido muito baixo, os índices podem não ser usados para executar consultas da maneira que você esperaria. Como a maioria dos sistemas Unix são bastante agressivos ao armazenar em cache, pelo menos 50% da RAM disponível em um servidor de banco de dados dedicado estará cheio de dados armazenados em cache.
A recomendação geral para Effective_cache_size é a seguinte.
- Defina o valor para a quantidade de cache do sistema de arquivos disponível
- Se você não souber, defina o valor para 50% da memória total do sistema
O valor padrão de Effective_cache_size =4 GB.
Temp_buffers
Este parâmetro define o número máximo de buffers temporários usados por cada sessão do banco de dados. Os buffers locais de sessão são usados apenas para acesso a tabelas temporárias. A configuração desse parâmetro pode ser alterada em sessões individuais, mas somente antes do primeiro uso de tabelas temporárias na sessão.
O banco de dados PostgreSQL utiliza esta área de memória para armazenar as tabelas temporárias de cada sessão, estas serão apagadas quando a conexão for encerrada.
O valor padrão de temp_buffer =8 MB.
Conclusão
Compreender a arquitetura de memória e ajustar os parâmetros apropriados é importante para melhorar o desempenho. Isso é especialmente necessário para sistemas de alta carga de trabalho. Para obter dicas de ajuste de desempenho mais genéricas, consulte esta folha de dicas de desempenho para o PostgreSQL.