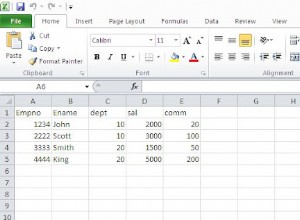
Você tem dois
LEFT JOINS :- A primeira junção à esquerda pode unir várias linhas de
solved. Digamos, 'jane' e 'luke' resolveram a tarefa. - A segunda entrada à esquerda só pode entrar em usuários chamados 'luke' ('luke' na condição de entrada!).
Você ainda recebe ambos rows, 'jane' simplesmente não é mostrado, a condição de junção a filtra, mas o
LEFT JOIN preserva a linha no resultado de qualquer maneira e acrescenta valores NULL. Você pode conseguir o que procura usando parênteses e um
[INNER] JOIN em vez do LEFT JOIN entre solved e users . O manual:
Use parênteses se necessário para determinar a ordem de aninhamento. Na ausência de parênteses,JOINs ninho da esquerda para a direita.
SELECT c.name AS cat_name, t.name AS task_name, u.name AS user_name
FROM task t
JOIN category c ON cat.id = t.category_id
LEFT JOIN
(solved s JOIN users u ON u.id = s.user_id AND u.name = 'luke') ON s.task_id = t.id
ORDER BY 1, 2, 3;
-
Usando o nome da tabelausersem vez da palavra reservadauser
-
Supondo queusers.nameé definido como único ou você pode ter vários usuários chamados 'luke'.
-
Se(task.id, users.id)emsolvedé definido comoUNIQUEouPRIMARY KEY, você não precisa deDISTINCTde forma alguma.
A consulta resultante não é apenas correta, mas também mais rápida.
Versão SqlAlchemy da consulta acima: (contribuição de @van)
Isso pressupõe que
Category , Task e User são classes mapeadas, enquanto solved é uma instância de Table (apenas uma tabela de associação, conforme mostrado no exemplo de código Many to Many):user_name = 'luke'
q = (session.query(Category.name, Task.name, User.name)
.select_from(Task)
.join(Category)
.outerjoin(
join(solved, User,
(solved.c.user_id == User.id) & (User.name == user_name),
))
.order_by(Category.name, Task.name, User.name)
)