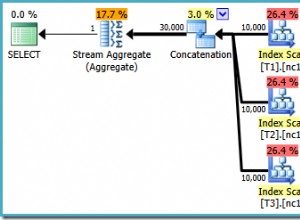
Assumindo pelo menos o Postgres 9.3.
Índice
Primeiro, um índice de várias colunas ajudará:
CREATE INDEX observations_special_idx
ON observations(station_id, created_at DESC, id)
created_at DESC é um ajuste um pouco melhor, mas o índice ainda seria escaneado para trás quase na mesma velocidade sem DESC . Assumindo
created_at está definido NOT NULL , senão considere DESC NULLS LAST no índice e inquerir:- PostgreSQL classifica por datetime asc, null primeiro?
A última coluna
id só é útil se você obtiver uma varredura somente de índice, o que provavelmente não funcionará se você adicionar muitas novas linhas constantemente. Nesse caso, remova id do índice. Consulta mais simples (ainda lenta)
Simplifique sua consulta, a subseleção interna não ajuda:
SELECT id
FROM (
SELECT station_id, id, created_at
, row_number() OVER (PARTITION BY station_id
ORDER BY created_at DESC) AS rn
FROM observations
) s
WHERE rn <= #{n} -- your limit here
ORDER BY station_id, created_at DESC;
Deve ser um pouco mais rápido, mas ainda lento.
Consulta rápida
- Supondo que você tenha relativamente poucos estações e relativamente muitos observações por estação.
- Assumindo também
station_idid definido comoNOT NULL.
Ser realmente rápido, você precisa do equivalente a uma varredura de índice solto (não implementado no Postgres, ainda). Resposta relacionada:
- Otimize a consulta GROUP BY para recuperar o registro mais recente por usuário
Se você tiver uma tabela separada de
stations (o que parece provável), você pode emular isso com JOIN LATERAL (Postgres 9.3+):SELECT o.id
FROM stations s
CROSS JOIN LATERAL (
SELECT o.id
FROM observations o
WHERE o.station_id = s.station_id -- lateral reference
ORDER BY o.created_at DESC
LIMIT #{n} -- your limit here
) o
ORDER BY s.station_id, o.created_at DESC;
Se você não tiver uma tabela de
stations , a próxima melhor coisa seria criar e manter um. Possivelmente, adicione uma referência de chave estrangeira para impor a integridade relacional. Se isso não for uma opção, você pode destilar essa mesa na hora. As opções simples seriam:
SELECT DISTINCT station_id FROM observations;
SELECT station_id FROM observations GROUP BY 1;Mas qualquer um deles precisaria de uma varredura sequencial e seria lento. Faça o Postgres usar o índice acima (ou qualquer índice btree com
station_id como coluna principal) com um CTE recursivo :WITH RECURSIVE stations AS (
( -- extra pair of parentheses ...
SELECT station_id
FROM observations
ORDER BY station_id
LIMIT 1
) -- ... is required!
UNION ALL
SELECT (SELECT o.station_id
FROM observations o
WHERE o.station_id > s.station_id
ORDER BY o.station_id
LIMIT 1)
FROM stations s
WHERE s.station_id IS NOT NULL -- serves as break condition
)
SELECT station_id
FROM stations
WHERE station_id IS NOT NULL; -- remove dangling row with NULL
Use isso como substituição imediata para as
stations tabela na consulta simples acima:WITH RECURSIVE stations AS (
(
SELECT station_id
FROM observations
ORDER BY station_id
LIMIT 1
)
UNION ALL
SELECT (SELECT o.station_id
FROM observations o
WHERE o.station_id > s.station_id
ORDER BY o.station_id
LIMIT 1)
FROM stations s
WHERE s.station_id IS NOT NULL
)
SELECT o.id
FROM stations s
CROSS JOIN LATERAL (
SELECT o.id, o.created_at
FROM observations o
WHERE o.station_id = s.station_id
ORDER BY o.created_at DESC
LIMIT #{n} -- your limit here
) o
WHERE s.station_id IS NOT NULL
ORDER BY s.station_id, o.created_at DESC;
Isso ainda deve ser mais rápido do que você tinha em ordens de magnitude .
SQL Fiddle aqui (9.6)
db<>fiddle aqui