Inspirado pelo comentário de @Frank, fiz alguns testes e adaptei minha consulta de acordo. Isso deve ser 1) correto e 2) o mais rápido possível:
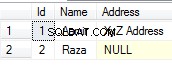
SELECT u.login, u.id, u.first_name
FROM pref_users u
WHERE u.login > u.logout
AND u.login >= now()::date + interval '1h'
ORDER BY u.login;
Como não há timestamps futuros em sua tabela (suponho), você não precisa de limite superior.
date_trunc('day', now()) é quase o mesmo que now()::date (ou algumas outras alternativas detalhadas abaixo), apenas que retorna timestamp em vez de uma date . Ambos resultam em um timestamp de qualquer forma depois de adicionar um interval . As expressões abaixo têm um desempenho ligeiramente diferente. Eles produzem resultados sutilmente diferentes porque
localtimestamp retorna o tipo de dados timestamp enquanto now() retorna timestamp with time zone . Mas quando convertido para date , ambos são convertidos para o mesmo local data e um timestamp [without time zone] presume-se que também esteja no fuso horário local. Então, quando comparado ao timestamp with time zone correspondente todos eles resultam no mesmo timestamp UTC internamente. Mais detalhes sobre o tratamento de fuso horário nesta pergunta relacionada. Melhor de cinco. Testado com PostgreSQL 9.0. Repetido com 9.1.5:resultados consistentes com margem de erro de 1%.
SELECT localtimestamp::date + interval '1h' -- Total runtime: 351.688 ms
, current_date + interval '1h' -- Total runtime: 338.975 ms
, date_trunc('day', now()) + interval '1h' -- Total runtime: 333.032 ms
, now()::date + interval '1h' -- Total runtime: 278.269 ms
FROM generate_series (1, 100000)
now()::date é obviamente um pouco mais rápido que CURRENT_DATE .