Bem, analisar a disseminação do coronavírus SARS-CoV-2 não era meu caso de uso dos sonhos . Mas com base nas respostas ao artigo Tracking Coronavirus COVID-19 Near Real Time with SAP HANA XSA de Ferry Djaja, decidi adicionar meus dois groszy também.
[Atualizado em 20-03-30 com os links alterados para os dados de origem; e a nova saída do mapa com base na nova granularidade de dados. Obrigado Douglas Maltby pelo seu comentário!]
Em sua postagem no blog, Ferry usou JavaScript no SAP HANA XSA para extrair os dados de arquivos CSV atualizados diariamente pela Johns Hopkins University.
Gostaria de mostrar como você pode puxar e carregar esses arquivos no SAP HANA usando apenas algumas linhas de código graças ao SAP HANA Python Client API for Machine Learning (
hana_ml pacote).
Algumas pessoas ficaram confusas com a visualização no mapa no final - observe que este artigo se concentra no caso de uso técnico conectando diferentes componentes, não em fazer uma análise profunda de dados de coronavírus.
Obter ambiente Python, por exemplo Jupyter
Vou usar o Jupyter no contêiner do Docker para isso. Por favor, dê uma olhada no meu post anterior Entendendo os containers (parte 05):arquivos compartilhados entre o host e os containers se você não estiver familiarizado com como iniciá-lo. Além disso, você pode fazer as mesmas etapas abaixo de qualquer outro ambiente Python.
Então, eu tenho meu contêiner
myjupyter01 encontro. Estou conectado à interface do usuário do Jupyter conforme descrito no blog anterior. Instalar hana_ml
A imagem do Jupyter que usei do registro do Docker Hub foi
jupyter/minimal-notebook . Ele já contém alguns pacotes populares de processamento de dados, como pandas . Mas, além disso, preciso instalar o
hana_ml , que — em sua versão atual 1.0.8 — está disponível no repositório PyPI:https://pypi.org/project/hana-ml/. O comando para executar a instalação é
python -m pip install hana_ml , mas como estou executando-o no notebook Jupyter com o kernel Python3, preciso executá-lo com ! no inicio:!python -m pip install hana_ml
Obviamente, esta etapa de instalação deve ser feita apenas uma vez. Não há necessidade de executá-lo novamente no mesmo contêiner, por exemplo ao recarregar os arquivos mais recentes.
Usar pandas para importar arquivos com dados
Vamos importar os mesmos três arquivos (
confirmed , deaths , recovered ) de https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series como Ferry usou em seu exemplo. import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')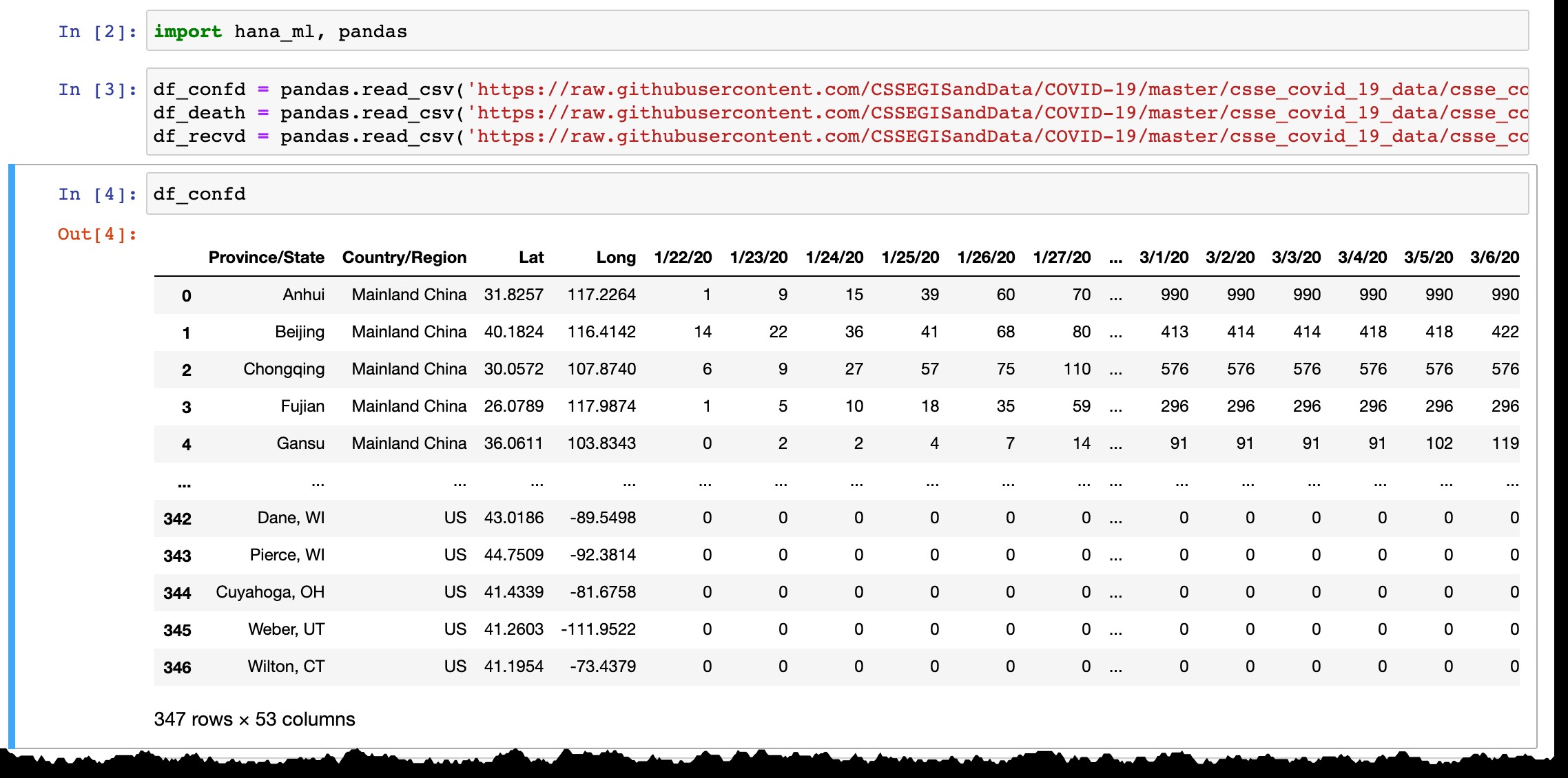
Como você pode ver na visualização do dataframe do Pandas, ele lista apenas países ou províncias com casos confirmados e todos os dias a nova coluna é adicionada com os dados mais recentes do dia anterior. As linhas são adicionadas quando o(s) primeiro(s) caso(s) é(ão) confirmado(s) na nova região.
Usar pandas para reformatar o quadro de dados
Antes de persistir os dados no SAP HANA, vamos:
- Remova todas as colunas de data, exceto a última,
- Renomeie a última coluna da data real (como o
3/10/20de hoje paraConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']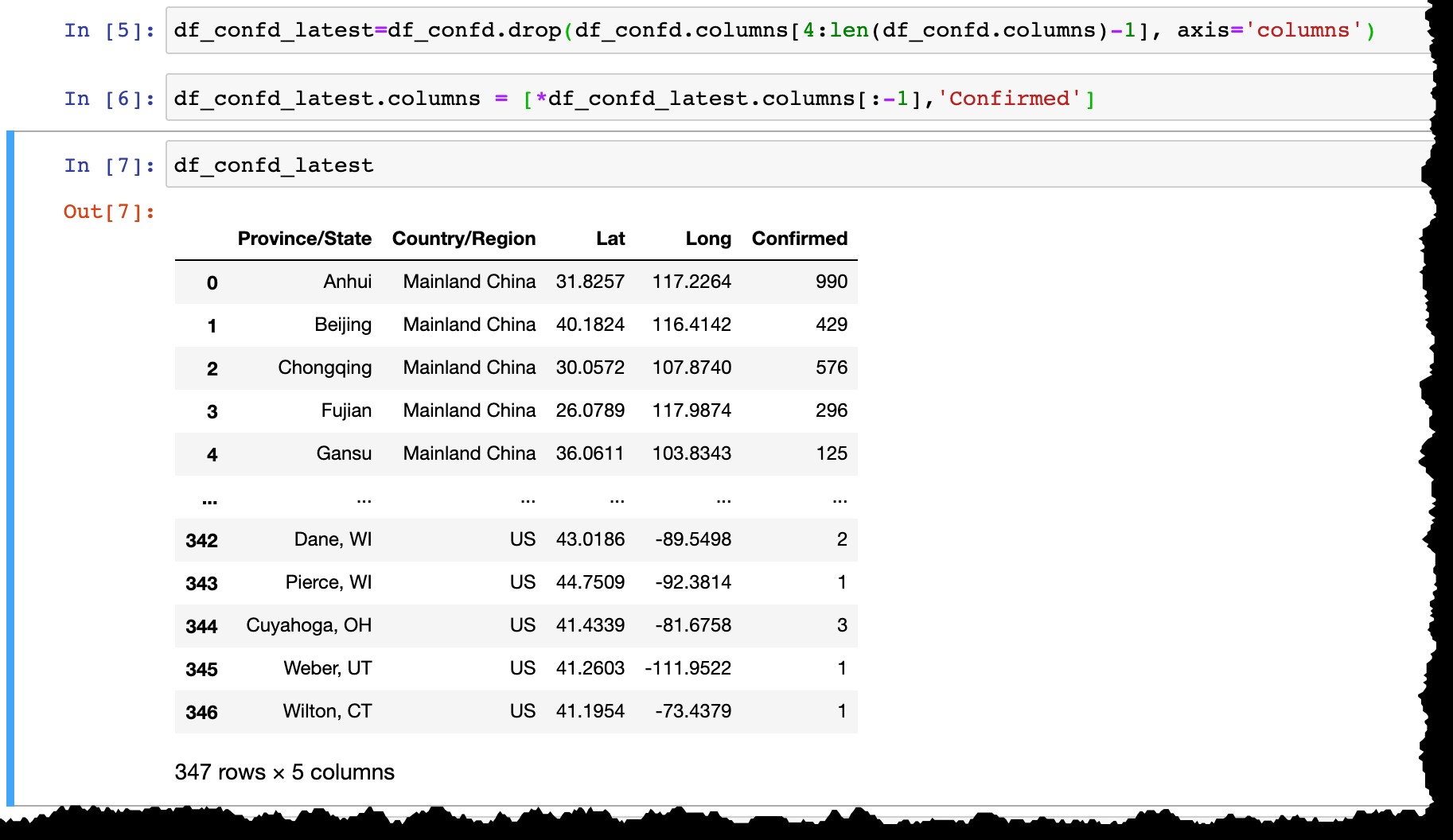
Usar hana_ml para persistir dados na tabela SAP HANA
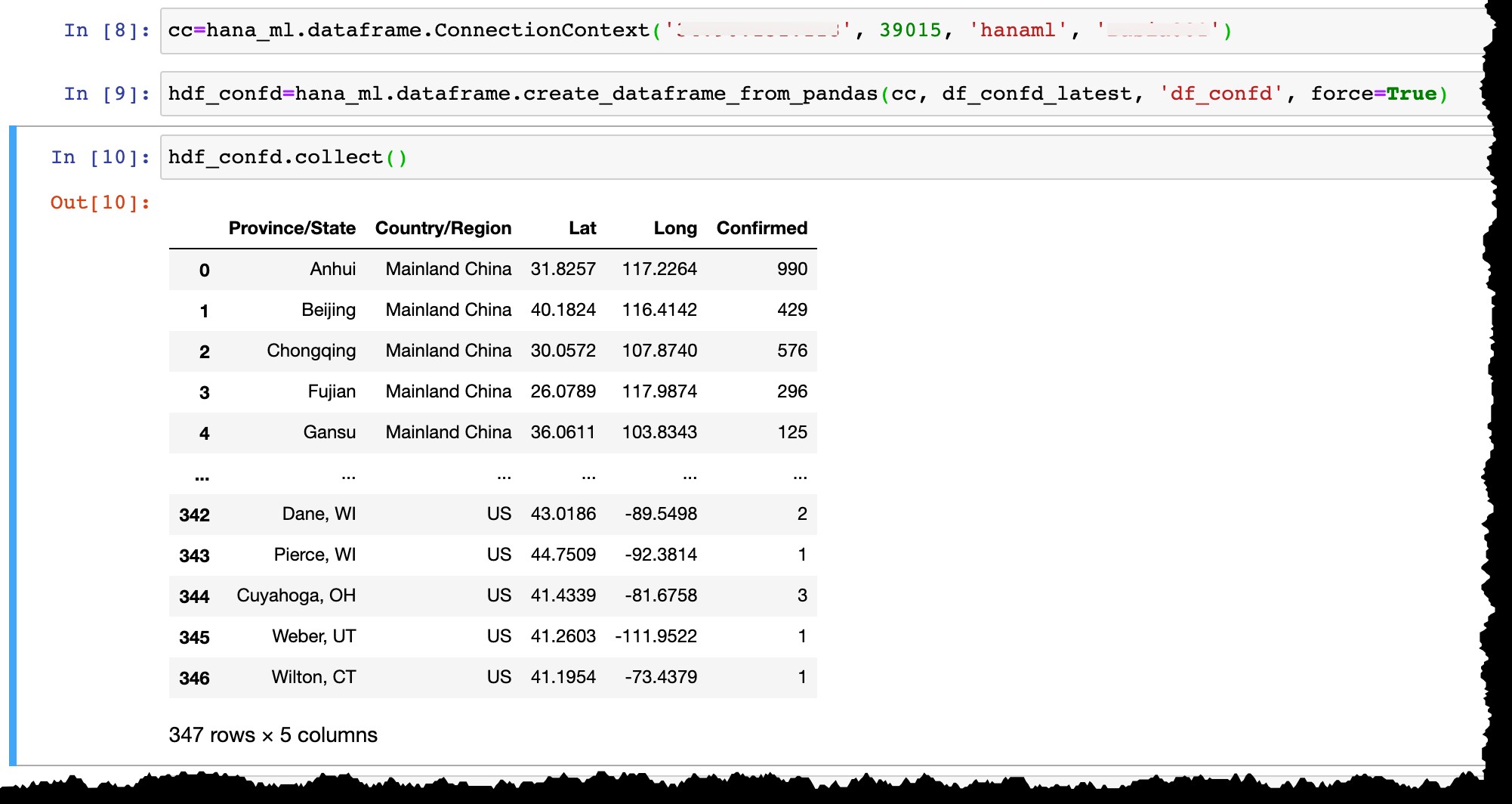
Agora deixe-me conectar à minha instância do SAP HANA Express com o usuário
hanaml que já existe lá... cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')…e converta o dataframe do Pandas
df_confd_latest em um dataframe HANA hdf_confd . hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Depois que o dataframe HANA é criado:
- Uma tabela de coluna física é criada no HANA e os dados do dataframe do Pandas são inseridos lá,
- frame de dados HANA
hdf_confdem Python não armazena nenhum dado em seu laptop, mas apenas aponta para uma tabelaHANAML.df_confdna memória do servidor SAP HANA, e todas as operações Python no dataframe HANA são fisicamente executadas no banco de dados HANA sem mover dados entre o servidor e um cliente, - Para exibir o resultado de qualquer operação, precisamos aplicar
collect()método para converter o dataframe HANA em Pandas (e, como resultado, trazer dados do servidor db HANA para o cliente local).
Use o DBeaver para verificar dados no SAP HANA…
Você deve se lembrar de mim já usando DBeaver — a ferramenta de banco de dados gratuita que suporta SAP HANA — no meu post anterior “GeoArt com SAP HANA e DBeaver“.
Estou usando agora novamente e, de fato, posso encontrar a tabela
df_confd no esquema HANAML com todos os dados do dataframe de origem do Pandas. 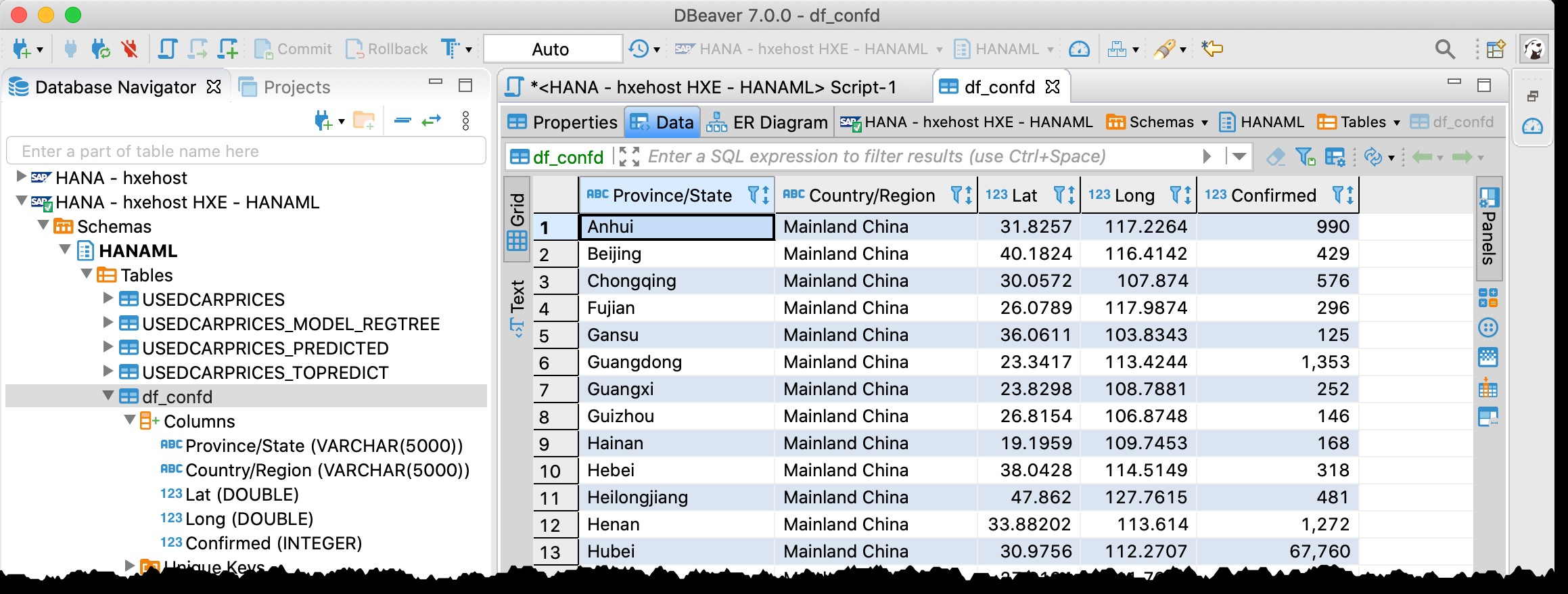
…e faça uma visualização espacial
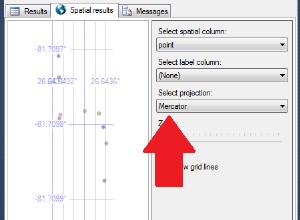
Como a tabela contém colunas de latitude e longitude, posso visualizar os países/estados afetados diretamente do DBeaver com o seguinte SQL usando a visualização de dados espaciais.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";Eu precisava mudar a projeção do mapa para
EPSG:4326 para obter esses pontos no mapa. E o DBeaver me mostra o restante dos dados do registro quando clico em qualquer ponto. 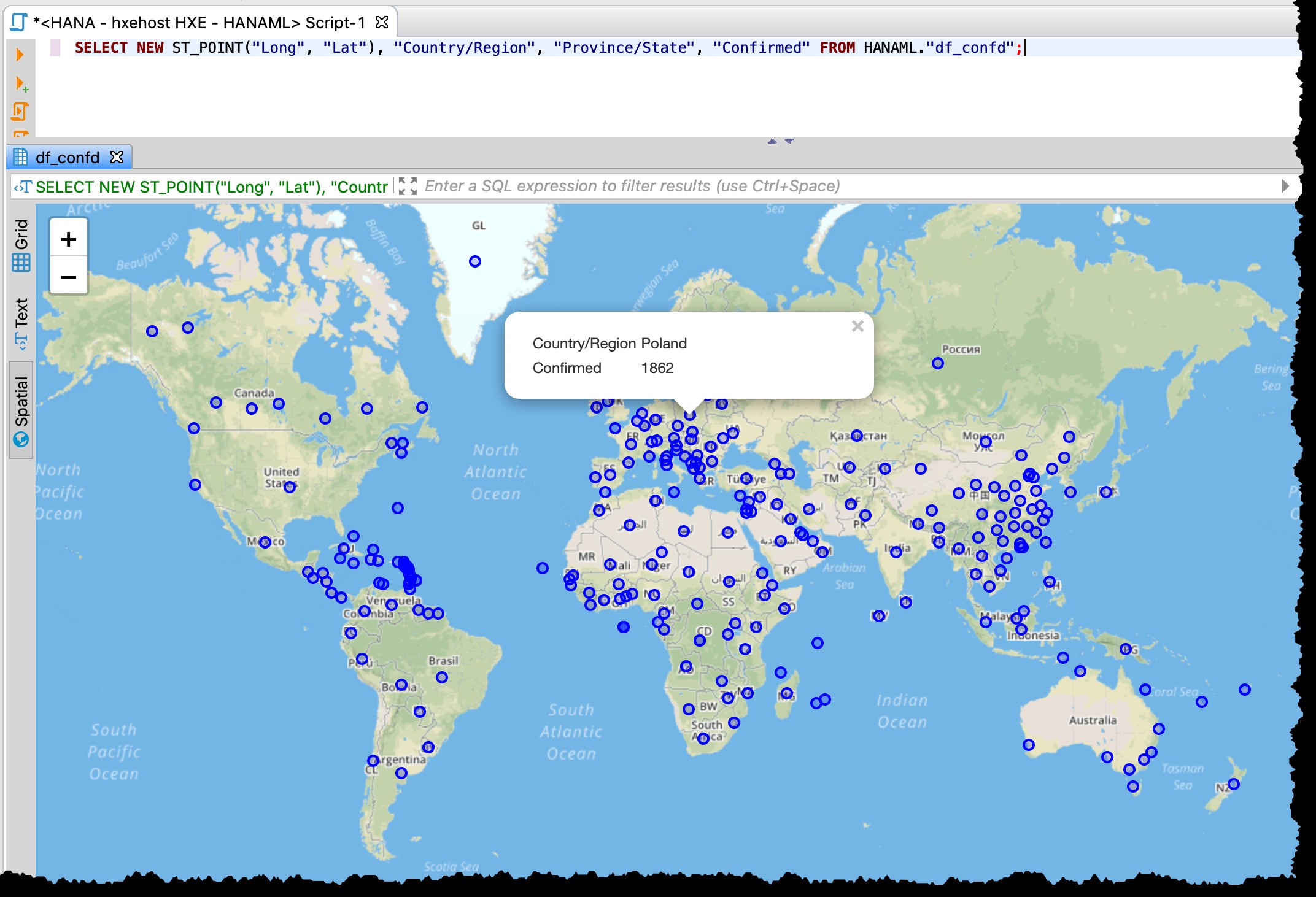
[Abaixo é a captura de tela antiga de 2020-03-11, que demonstra também a granularidade diferente de, por exemplo, dados dos EUA usados na época]
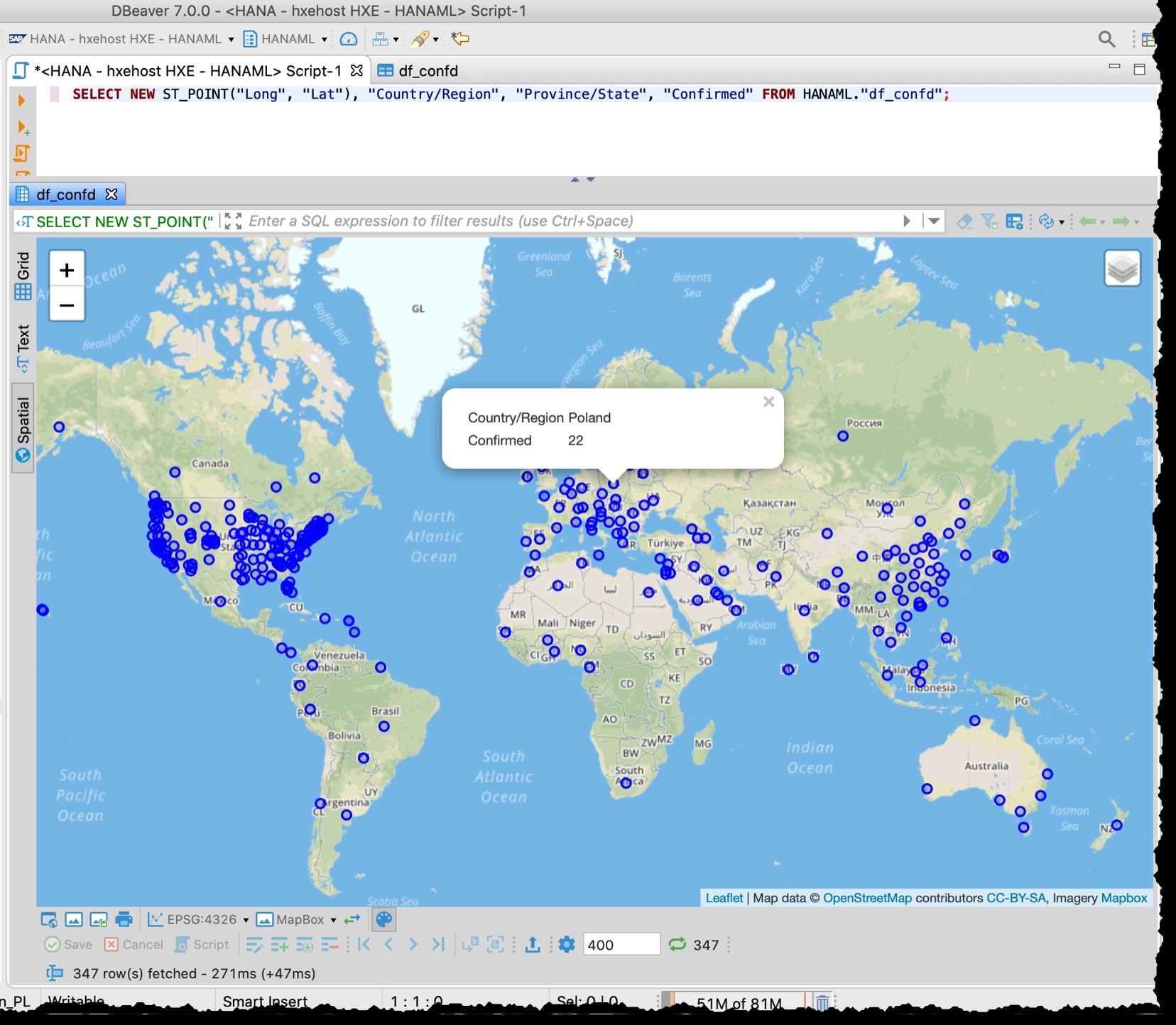
A visualização espacial do DBeaver não é uma ferramenta de exploração visual geoespacial completa. No entanto, é bom o suficiente para ver os países/regiões afetados (dependendo da granularidade nos arquivos de origem).
Se você estiver interessado em saber mais sobre hana_ml …
… então eu definitivamente recomendo verificar Tutorial prático:aprendizado de máquina push-down para SAP HANA com Python por Andreas Forster.
O HANA ML faz parte do novo tópico “Advanced Analytics with SAP HANA” para eventos do CodeJam. Infelizmente, por causa da situação do coronavírus, tivemos que cancelar o primeiro organizado por Jakob Flaman em Berna este mês. Outro é organizado por Ewelina Pękała no dia 27 de maio em Katowice:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Espero que a situação se normalize a essa altura, e não precisaremos cancelar este também.