Avaliar qual padrão de arquitetura de streaming é o melhor para seu caso de uso é uma pré-condição para uma implantação de produção bem-sucedida.
O ecossistema Apache Hadoop tornou-se a plataforma preferida para empresas que buscam processar e entender dados em grande escala em tempo real. Tecnologias como Apache Kafka, Apache Flume, Apache Spark, Apache Storm e Apache Samza estão cada vez mais expandindo o que é possível. Muitas vezes, é tentador agrupar casos de uso de streaming em larga escala, mas, na realidade, eles tendem a se dividir em alguns padrões de arquitetura diferentes, com diferentes componentes do ecossistema mais adequados para diferentes problemas.
Nesta postagem, descreverei os quatro principais padrões de streaming que encontramos com clientes que executam hubs de dados corporativos em produção e explicarei como implementar esses padrões arquiteturalmente no Hadoop.
Padrões de transmissão
Os quatro padrões básicos de streaming (geralmente usados em conjunto) são:
- Ingestão de stream: Envolve a persistência de baixa latência de eventos para HDFS, Apache HBase e Apache Solr.
- Processamento de eventos em tempo quase real (NRT) com contexto externo: Realiza ações como alertar, sinalizar, transformar e filtrar eventos à medida que eles chegam. Ações podem ser tomadas com base em critérios sofisticados, como modelos de detecção de anomalias. Casos de uso comuns, como detecção e recomendação de fraudes NRT, geralmente exigem latências baixas abaixo de 100 milissegundos.
- Processamento Particionado de Evento NRT: Semelhante ao processamento de eventos NRT, mas derivando benefícios do particionamento dos dados, como armazenar informações externas mais relevantes na memória. Esse padrão também requer latências de processamento abaixo de 100 milissegundos.
- Topologia complexa para agregações ou ML: O santo graal do processamento de fluxo:obtém respostas em tempo real dos dados com um conjunto de operações complexo e flexível. Aqui, como os resultados geralmente dependem de cálculos em janelas e exigem dados mais ativos, o foco muda de latência ultrabaixa para funcionalidade e precisão.
Nas seções a seguir, abordaremos as maneiras recomendadas para implementar esses padrões de maneira testada, comprovada e sustentável.
Ingestão de streaming
Tradicionalmente, o Flume tem sido o sistema recomendado para ingestão de streaming. Sua grande biblioteca de fontes e sumidouros cobrem todas as bases do que consumir e onde escrever. (Para obter detalhes sobre como configurar e gerenciar o Flume, Usando o Flume , o livro da O'Reilly Media do engenheiro de software Cloudera/membro do Flume PMC Hari Shreedharan, é um ótimo recurso.)
No ano passado, o Kafka também se tornou popular por causa de recursos poderosos, como reprodução e replicação. Por causa da sobreposição entre os objetivos de Flume e Kafka, o relacionamento deles é muitas vezes confuso. Como eles se encaixam? A resposta é simples:Kafka é um pipe semelhante à abstração do Canal do Flume, embora seja um pipe melhor por causa de seu suporte aos recursos mencionados acima. Uma abordagem comum é usar o Flume para a fonte e o coletor e o Kafka para o tubo entre eles.
O diagrama abaixo ilustra como o Kafka pode servir como fonte de dados upstream para o Flume, o destino downstream do Flume ou o canal Flume.
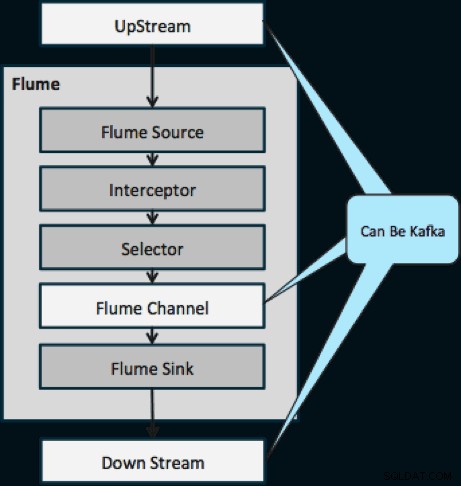
O design ilustrado abaixo é massivamente escalável, robusto para batalhas, monitorado centralmente por meio do Cloudera Manager, tolerante a falhas e suporta reprodução.
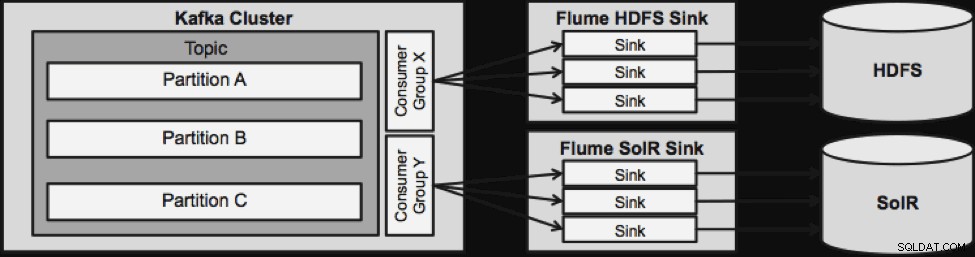
Uma coisa a ser observada antes de irmos para a próxima arquitetura de streaming é como esse design lida com falhas. Os Flume Sinks são retirados de um Kafka Consumer Group. O grupo Consumer acompanha o deslocamento do tópico com a ajuda do Apache ZooKeeper. Se um Flume Sink for perdido, o Kafka Consumer redistribuirá a carga para os sinks restantes. Quando o Flume Sink voltar a funcionar, o grupo Consumer será redistribuído novamente.
Processamento de eventos NRT com contexto externo
Para reiterar, um caso de uso comum para esse padrão é observar os eventos que chegam e tomar decisões imediatas, seja para transformar os dados ou realizar algum tipo de ação externa. A lógica de decisão geralmente depende de perfis ou metadados externos. Uma maneira fácil e escalável de implementar essa abordagem é adicionar um interceptor Source ou Sink Flume à sua arquitetura Kafka/Flume. Com um ajuste modesto, não é difícil atingir latências em milissegundos baixos.
Os Flume Interceptors recebem eventos ou lotes de eventos e permitem que o código do usuário modifique ou execute ações com base neles. O código do usuário pode interagir com a memória local ou um sistema de armazenamento externo como o HBase para obter informações de perfil necessárias para decisões. O HBase geralmente pode nos fornecer nossas informações em cerca de 4 a 25 milissegundos, dependendo da rede, design do esquema e configuração. Você também pode configurar o HBase de forma que ele nunca fique inativo ou interrompido, mesmo em caso de falha.
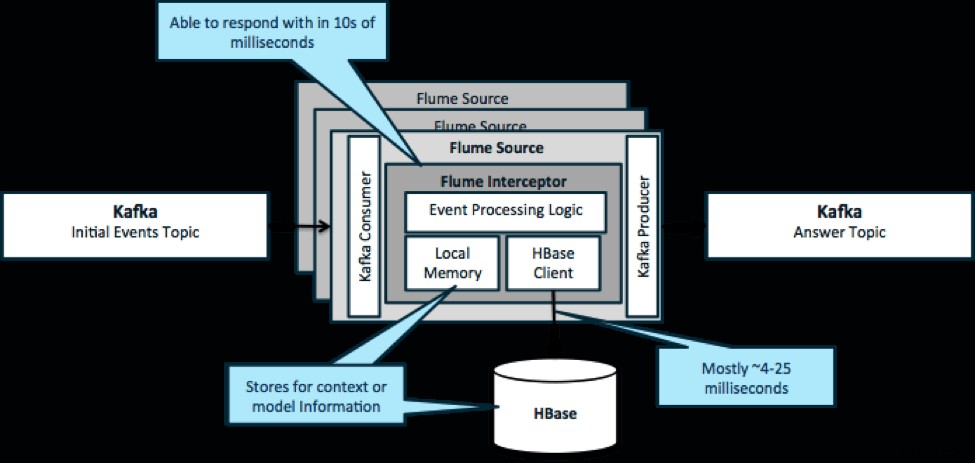
A implementação não requer quase nenhuma codificação além da lógica específica do aplicativo no interceptor. O Cloudera Manager oferece uma interface de usuário intuitiva para implantar essa lógica por meio de parcelas, bem como conectar, configurar e monitorar os serviços.
Processamento de eventos particionados NRT com contexto externo
Na arquitetura ilustrada abaixo (solução não particionada), você precisaria chamar frequentemente o HBase porque o contexto externo relevante para eventos específicos não cabe na memória local nos interceptores Flume.
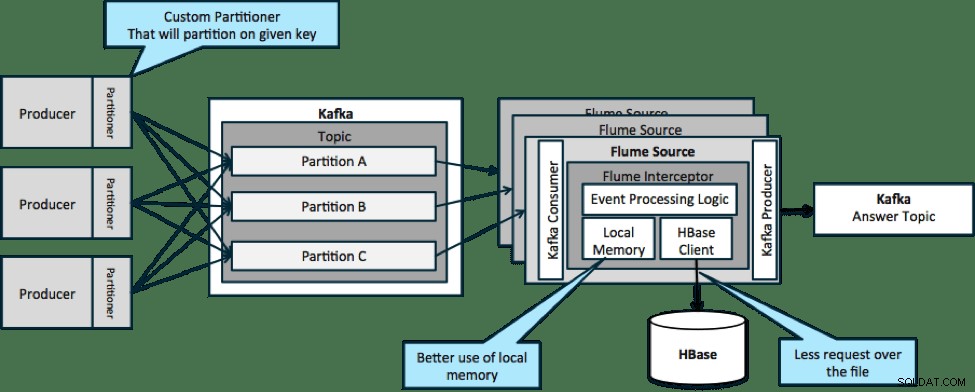
No entanto, se você definir uma chave para particionar seus dados, poderá corresponder os dados de entrada ao subconjunto dos dados de contexto relevantes a eles. Se você particionar os dados 10 vezes, você só precisará manter 1/10 dos perfis na memória. O HBase é rápido, mas a memória local é mais rápida. Kafka permite que você defina um particionador personalizado que ele usa para dividir seus dados.
Observe que o Flume não é estritamente necessário aqui; a solução raiz aqui apenas um consumidor Kafka. Portanto, você pode usar apenas um consumidor no YARN ou um aplicativo MapReduce somente de mapa.
Topologia complexa para agregações ou ML
Até este ponto, temos explorado operações em nível de evento. No entanto, às vezes você precisa de operações mais complexas, como contagens, médias, sessionalização ou criação de modelos de aprendizado de máquina que operam em lotes de dados. Nesse caso, o Spark Streaming é a ferramenta ideal por vários motivos:
- É fácil de desenvolver em comparação com outras ferramentas. As APIs ricas e concisas do Spark facilitam a criação de topologias complexas.
- Código semelhante para streaming e processamento em lote. Com algumas alterações, o código para pequenos lotes em tempo real pode ser usado para lotes enormes offline. Além de reduzir o tamanho do código, essa abordagem reduz o tempo necessário para testes e integração.
- Há um mecanismo a ser conhecido. Há um custo para treinar a equipe sobre as peculiaridades e os aspectos internos dos mecanismos de processamento distribuído. A padronização no Spark consolida esse custo para streaming e lote.
- Micro-lote ajuda a dimensionar de forma confiável. O reconhecimento em nível de lote permite mais rendimento e permite soluções sem o medo de um envio duplo. O micro-lote também ajuda no envio de alterações para HDFS ou HBase em termos de desempenho em escala.
- A integração do ecossistema do Hadoop está incorporada. O Spark tem integração profunda com HDFS, HBase e Kafka.
- Sem risco de perda de dados. Graças ao WAL e ao Kafka, o Spark Streaming evita a perda de dados em caso de falha.
- É fácil depurar e executar. Você pode depurar e percorrer seu código Spark Streaming em um IDE local sem um cluster. Além disso, o código se parece com um código de programação funcional normal, então não leva muito tempo para um desenvolvedor Java ou Scala dar o salto. (Python também é suportado.)
- O streaming é nativo com estado. No Spark Streaming, o estado é um cidadão de primeira classe, o que significa que é fácil escrever aplicativos de streaming com estado que sejam resilientes a falhas de nó.
- Como padrão de fato, o Spark está recebendo investimentos de longo prazo de todo o ecossistema.
No momento da redação deste artigo, havia aproximadamente 700 confirmações para o Spark como um todo nos últimos 30 dias, em comparação com outras estruturas de streaming, como Storm, com 15 confirmações durante o mesmo período. - Você tem acesso a bibliotecas de ML.
O MLlib do Spark está se tornando muito popular e sua funcionalidade só aumentará. - Você pode usar SQL quando necessário.
Com o Spark SQL, você pode adicionar lógica SQL ao seu aplicativo de streaming para reduzir a complexidade do código.
Conclusão
Há muito poder no streaming e vários padrões possíveis, mas, como você aprendeu neste post, você pode fazer coisas realmente poderosas com codificação mínima se souber qual padrão combina melhor com seu caso de uso.
Ted Malaska é arquiteto de soluções na Cloudera, colaborador do Spark, Flume e HBase e coautor do livro O'Reilly, Arquitetura de aplicativos Hadoop.



