Já que você está usando spring. Você pode usar
MultipartFile para obter o arquivo em seu controlador e, em seguida, use Binary de org.bson para armazenar o arquivo no MongoDB, se o tamanho da sua imagem for <16 MB (se o tamanho da imagem for> 16 MB, você pode usar GridFs
). Você precisa adicionar apenas uma dependência ao seu projeto -
spring-data-mongoDB Vamos dar um exemplo de uma coleção User que se parece com isso:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Aqui você pode ver
Binary image que representa seu arquivo de imagem. Agora crie um repositório para esta coleção de usuários usando
MongoRepository public interface UserRepository extends MongoRepository<User, String>{
}
Crie um controlador para fins de demonstração. Use o arquivo
@RequestParam MultipartFile file para obter o arquivo para o seu controlador, obtenha bytes do arquivo e defina-o como objeto de usuário user.setImage(new Binary(file.getBytes())); exemplo completo está abaixo:@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Inicie o servidor e atinja o ponto final, conforme mostrado na captura de tela abaixo do carteiro
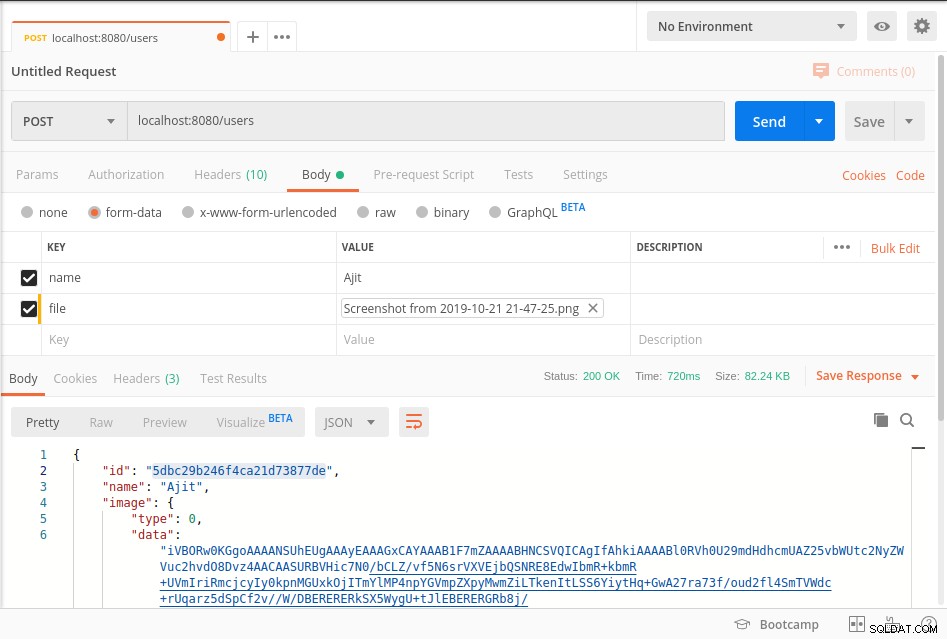
Seus dados são armazenados em mongoDb em
BinData formato e para obter os dados do banco de dados, consulte getImage método do código acima. EDITAR:
O questionador está usando
tess4j biblioteca para extrair texto de imagem e doOCR é um método nesta biblioteca. Eu segui estas etapas para extrair o texto da imagem no meu aplicativo de inicialização de primavera. -
Instale otesseract-ocrem seu sistema:
sudo apt-get install tesseract-ocr
-
Baixeeng.traineddatadados de treinamento de https://github.com/tesseract-ocr/tessdata e mova-o para a pasta raiz do projeto.
-
Adicione a dependência abaixo ao seu projeto:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Adicione o código abaixo ao projeto existente:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}