A manutenção é algo que uma equipe de operação não pode evitar. Os servidores precisam acompanhar o software, hardware e tecnologia mais recentes para garantir que os sistemas sejam estáveis e funcionem com o menor risco possível, ao mesmo tempo em que fazem uso de recursos mais recentes para melhorar o desempenho geral.
Sem dúvida, há uma longa lista de tarefas de manutenção que devem ser executadas pelos administradores de sistema, especialmente quando se trata de sistemas críticos. Algumas das tarefas devem ser realizadas em intervalos regulares, como diariamente, semanalmente, mensalmente e anualmente. Algumas precisam ser feitas imediatamente, com urgência. No entanto, qualquer operação de manutenção não deve levar a outro problema maior, e qualquer manutenção deve ser tratada com cuidado redobrado para evitar qualquer interrupção no negócio.
Obter estado questionável e alarmes falsos é comum enquanto a manutenção está em andamento. Isso é esperado porque durante o período de manutenção, o servidor não funcionará como deveria até que a tarefa de manutenção seja concluída. O ClusterControl, a plataforma de gerenciamento e monitoramento com tudo incluído para seus bancos de dados de código aberto, pode ser configurado para entender essas circunstâncias e simplificar suas rotinas de manutenção, sem sacrificar os recursos de monitoramento e automação que oferece.
Modo de manutenção
O ClusterControl introduziu o modo de manutenção na versão 1.4.0, onde você pode colocar um nó individual em manutenção que impede o ClusterControl de disparar alarmes e enviar notificações pela duração especificada. O modo de manutenção pode ser configurado a partir da interface do usuário do ClusterControl e também usando a ferramenta CLI do ClusterControl chamada "s9s". Na interface do usuário, basta acessar Nós -> escolher um nó -> Ações do nó -> Agendar modo de manutenção :
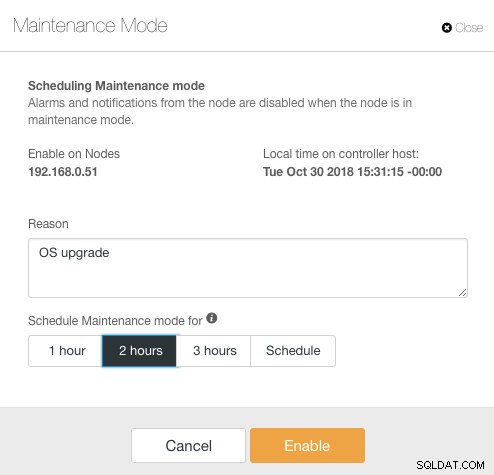
Aqui, pode-se definir o período de manutenção para um tempo pré-definido ou programá-lo de acordo. Você também pode anotar o motivo do agendamento da atualização, útil para fins de auditoria. Você deverá ver a seguinte notificação quando o modo de manutenção estiver ativo:
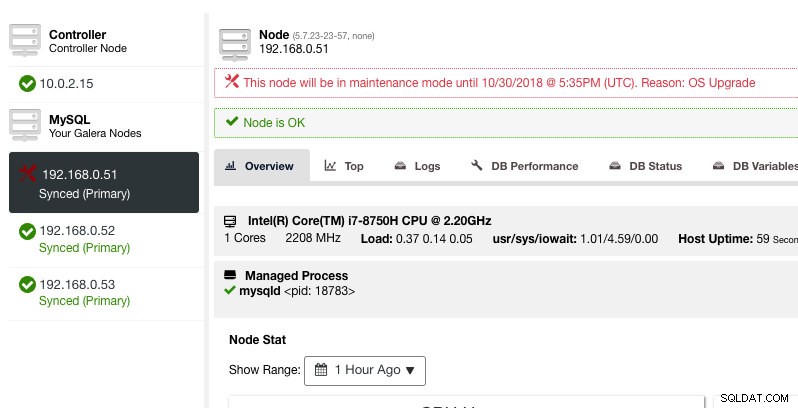
O ClusterControl não degradará o nó, portanto, o estado do nó permanece como está, a menos que você execute qualquer ação que altere o estado. Os alarmes e notificações para este nó serão reativados assim que o período de manutenção terminar, ou o operador desativá-lo explicitamente acessando Node Actions -> Disable Maintenance Mode .
Observe que, se a recuperação automática de nó estiver habilitada, o ClusterControl sempre recuperará um nó, independentemente do status do modo de manutenção. Não se esqueça de desabilitar a recuperação de nós para evitar que o ClusterControl interfira em suas tarefas de manutenção, isso pode ser feito na barra de resumo superior.
O modo de manutenção também pode ser configurado via CLI ClusterControl ou "s9s". Você pode usar o comando "s9s maintenance" para listar e manipular os períodos de manutenção. A seguinte linha de comando agenda uma janela de manutenção de uma hora para o nó 192.168.1.121 amanhã:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Para obter mais detalhes e exemplos, consulte a documentação de manutenção do s9s.
Modo de manutenção em todo o cluster
No momento da redação deste artigo, a configuração do modo de manutenção deve ser configurada por nó gerenciado. Para manutenção em todo o cluster, é necessário repetir o processo de agendamento para cada nó gerenciado do cluster. Isso pode ser impraticável se você tiver um número alto de nós em seu cluster ou se o intervalo de manutenção for muito curto entre duas tarefas.
Felizmente, o ClusterControl CLI (também conhecido como s9s) pode ser usado como uma solução alternativa para superar essa limitação. Você pode usar "nós s9s" para listar e manipular os nós gerenciados em um cluster. Essa lista pode ser iterada para agendar um modo de manutenção em todo o cluster em um determinado momento usando o comando "s9s Maintenance".
Vejamos um exemplo para entender isso melhor. Considere o seguinte cluster Percona XtraDB de três nós que temos:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4O cluster tem um total de 4 nós - 3 nós de banco de dados com um nó ClusterControl. A primeira coluna, STAT, mostra a função e o status do nó. O primeiro caractere é a função do nó - "c" significa controlador e "g" significa nó do banco de dados Galera. Suponha que queremos agendar apenas os nós do banco de dados para manutenção, podemos filtrar a saída para obter o nome do host ou endereço IP onde o STAT relatado tem "g" no início:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Com uma iteração simples, podemos agendar uma janela de manutenção em todo o cluster para cada nó no cluster. O comando a seguir itera a criação de manutenção com base em todos os endereços IP encontrados no cluster usando um loop for, em que planejamos iniciar a operação de manutenção no mesmo horário amanhã e terminar uma hora depois:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bVocê deverá ver uma impressão de 3 UUIDs, a string exclusiva que identifica cada período de manutenção. Podemos então verificar com o seguinte comando:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3A partir da saída acima, obtivemos uma lista de tempos de manutenção agendados para cada nó do banco de dados. Durante o horário agendado, o ClusterControl não disparará alarmes nem enviará notificação se encontrar irregularidades no cluster.
Iteração do modo de manutenção
Algumas rotinas de manutenção devem ser feitas em intervalos regulares, por exemplo, backups, tarefas de limpeza e limpeza. Durante o tempo de manutenção, esperamos que o servidor se comporte de maneira diferente. No entanto, qualquer falha de serviço, inacessibilidade temporária ou alta carga certamente causaria estragos em nosso sistema de monitoramento. Para intervalos de manutenção frequentes e de intervalo curto, isso pode ser muito irritante e pular os alarmes falsos levantados pode proporcionar um sono melhor durante a noite.
No entanto, habilitar o modo de manutenção também pode expor o servidor a um risco maior, pois o monitoramento rigoroso é ignorado durante o período de tempo. Portanto, provavelmente é uma boa ideia entender a natureza da operação de manutenção que gostaríamos de realizar antes de ativar o modo de manutenção. A lista de verificação a seguir deve nos ajudar a determinar nossa política de modo de manutenção:
- Nós afetados - Quais nós estão envolvidos na manutenção?
- Consequências - O que acontece com o nó quando a operação de manutenção está em andamento? Será inacessível, carregado ou reiniciado?
- Duração - Quanto tempo a operação de manutenção leva para ser concluída?
- Frequência - Com que frequência a operação de manutenção deve ser executada?
Vamos colocá-lo em um caso de uso. Considere que temos um cluster Percona XtraDB de três nós com um nó ClusterControl. Suponhamos que todos os nossos servidores estejam sendo executados em máquinas virtuais e a política de backup de VM exige que todas as VMs sejam submetidas a backup todos os dias a partir da 1h, um nó por vez. Durante esta operação de backup, o nó será congelado por cerca de 10 minutos no máximo e o nó que está sendo gerenciado e monitorado pelo ClusterControl ficará inacessível até que o backup termine. Do ponto de vista do Galera Cluster, essa operação não desativa o cluster inteiro, pois o cluster permanece em quorum e o componente primário não é afetado.
Com base na natureza da tarefa de manutenção, podemos resumi-la da seguinte forma:
- Nós afetados - Todos os nós do cluster ID 1 (3 nós de banco de dados e 1 nó ClusterControl).
- Consequência - A VM cujo backup está sendo feito ficará inacessível até a conclusão.
- Duração - Cada operação de backup de VM leva cerca de 5 a 10 minutos para ser concluída.
- Frequência - O backup da VM está programado para ser executado diariamente, a partir da 1h no primeiro nó.
Podemos então apresentar um plano de execução para agendar nosso modo de manutenção:
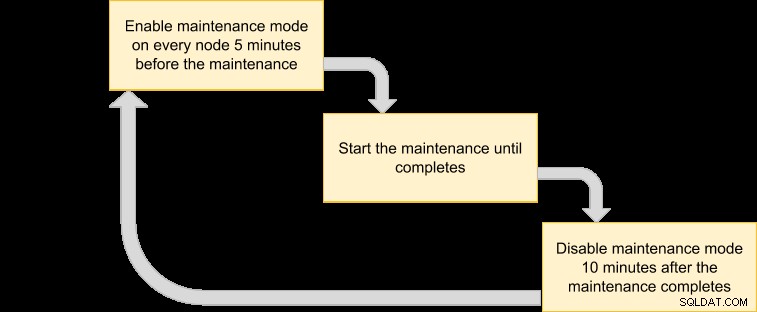
Como queremos que o backup de todos os nós do cluster seja feito pelo gerenciador de VM, basta listar os nós para o ID de cluster correspondente:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53A saída acima pode ser usada para agendar a manutenção em todo o cluster. Por exemplo, se você executar o seguinte comando, o ClusterControl ativará o modo de manutenção para todos os nós sob o ID de cluster 1 a partir de agora até os próximos 50 minutos:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneUsando o comando acima, podemos convertê-lo em um arquivo de execução colocando-o em um script. Crie um arquivo:
$ vim /usr/local/bin/enable_maintenance_modeE adicione as seguintes linhas:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneSalve-o e verifique se a permissão do arquivo é executável:
$ chmod 755 /usr/local/bin/enable_maintenance_modeEm seguida, use o cron para agendar a execução do script de 5 minutos à 1h diariamente, logo antes da operação de backup da VM começar à 1h:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeRecarregue o daemon cron para garantir que nosso script esteja na fila:
$ systemctl reload crond # or service crond reloadÉ isso. Agora podemos realizar nossa operação de manutenção diária sem sermos incomodados por falsos alarmes e notificação por e-mail até que a manutenção seja concluída.
Recurso de manutenção de bônus - Ignorando a recuperação do nó
Com a recuperação automática habilitada, o ClusterControl é inteligente o suficiente para detectar uma falha de nó e tentará recuperar um nó com falha após um período de carência de 30 segundos, independentemente do status do modo de manutenção. Você sabia que o ClusterControl pode ser configurado para ignorar deliberadamente a recuperação de um nó específico? Isso pode ser muito útil quando você precisa realizar uma manutenção urgente sem saber o prazo e o resultado da manutenção.
Por exemplo, imagine que ocorreu uma corrupção do sistema de arquivos e a verificação e o reparo do sistema de arquivos são necessários após uma reinicialização forçada. É difícil determinar com antecedência quanto tempo seria necessário para concluir esta operação. Assim, podemos simplesmente usar um arquivo sinalizador para sinalizar ao ClusterControl para pular a recuperação do nó.
Em primeiro lugar, adicione a seguinte linha dentro do /etc/cmon.d/cmon_X.cnf (onde X é o ID do cluster) no nó ClusterControl:
node_recovery_lock_file=/root/do_not_recoverEm seguida, reinicie o serviço cmon para carregar a alteração:
$ systemctl restart cmon # service cmon restartPor fim, certifique-se de que o arquivo especificado esteja presente no nó que desejamos pular para a recuperação do ClusterControl:
$ touch /root/do_not_recoverIndependentemente do status do modo de recuperação e manutenção automática, o ClusterControl só recuperará o nó quando esse arquivo sinalizador não existir. O administrador é então responsável por criar e remover o arquivo no nó do banco de dados.
É isso, pessoal. Boa manutenção!



