SCUMM (Severalnines ClusterControl Unified Monitoring &Management) é uma solução baseada em agente com agentes instalados nos nós do banco de dados. Ele fornece um conjunto de painéis de monitoramento, que têm o Prometheus como armazenamento de dados com sua linguagem de consulta elástica e modelo de dados multidimensional. O Prometheus extrai dados de métricas de exportadores em execução nos hosts de banco de dados.
A arquitetura ClusterControl SCUMM foi introduzida com a versão 1.7.0, estendendo a funcionalidade de monitoramento para MySQL, Galera Cluster, PostgreSQL e ProxySQL.
O novo ClusterControl 1.7.1 adiciona monitoramento de alta resolução para sistemas MongoDB.
 Lista de painéis do ClusterControl MongoDB
Lista de painéis do ClusterControl MongoDB Neste artigo, descreveremos os dois principais painéis para ambientes MongoDB. Servidor MongoDB e conjunto de réplicas MongoDB.
Painel e lista de métricas
A lista de painéis e suas métricas:
| Servidor MongoDB | |
|---|---|
| Nome Nome do ReplSet Tempo de atividade do servidor OpsCounters Conexões WT - Tickets simultâneos (leitura) WT - tickets simultâneos (gravação) WT - Cache Bloqueio Global Declarações |
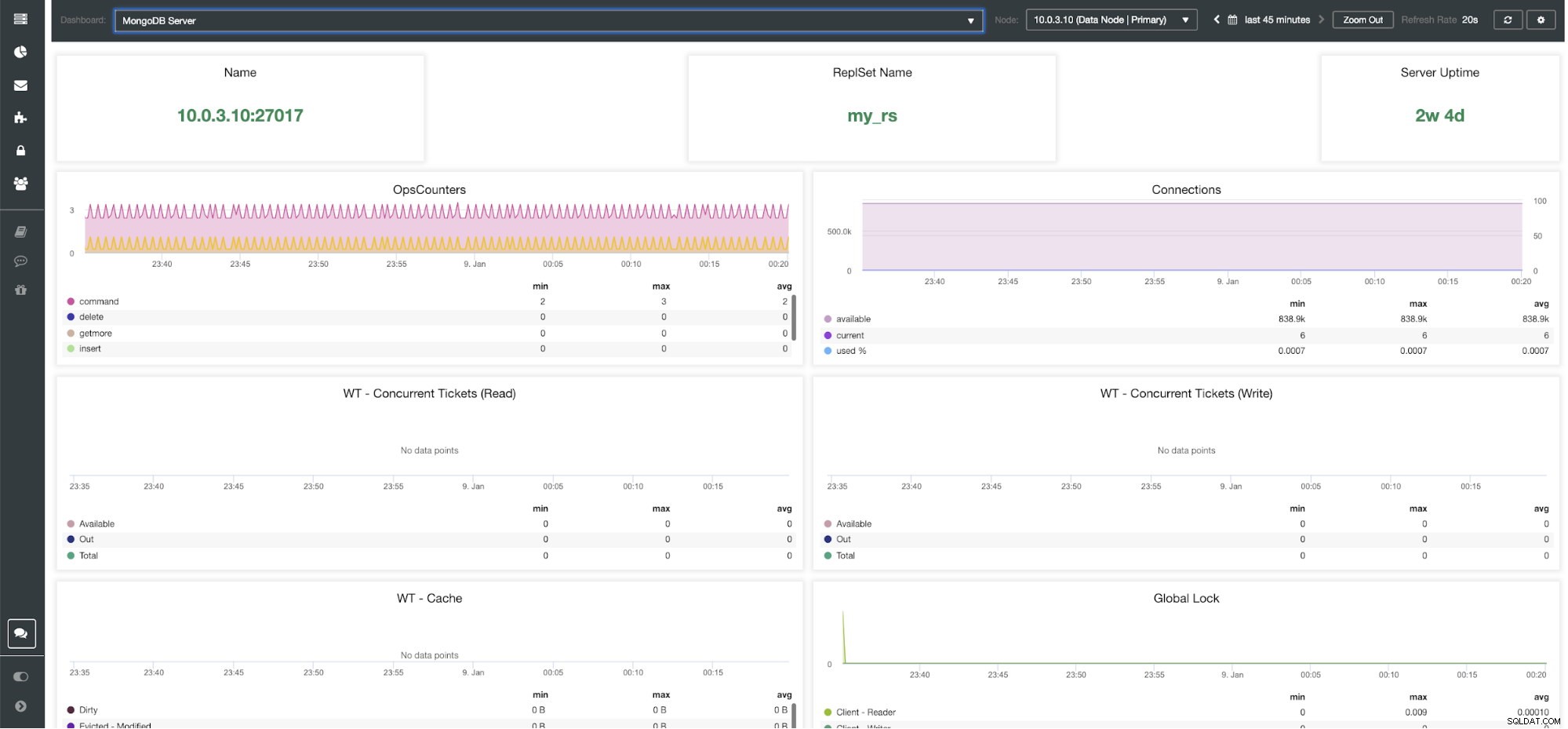 ClusterControl MongoDB Server Dashboard
ClusterControl MongoDB Server Dashboard| MongoDB ReplicaSet | |
|---|---|
| Tamanho do ReplSet Nome do ReplSet PRIMARY Versão do Servidor Conjuntos de Réplicas e Membros Janela Oplog por ReplSet Headroom de Replicação Total de PRIMÁRIO / SECUNDÁRIO on-line por ReplSet Cursores abertos por ReplSet ReplSet - Cursores esgotados por conjunto Máximo atraso de replicação por ReplSet Tamanho de Oplog OpsCounters Tempo de ping para membros do conjunto de réplicas de PRIMARY(s) |
 ClusterControl MongoDB ReplicaSet Dashboard
ClusterControl MongoDB ReplicaSet Dashboard Os sistemas de banco de dados dependem muito dos recursos do sistema operacional, portanto, você também pode encontrar dois painéis adicionais para Visão geral do sistema e Visão geral do cluster do seu ambiente MongoDB.
| Visão geral do sistema | |
|---|---|
| Tempo de atividade do servidor Núcleos de CPU RAM total Média de carga Uso de CPU Uso de RAM Uso de espaço em disco Uso de rede Disk IOPS Disk IO Util % Disk Throughput |
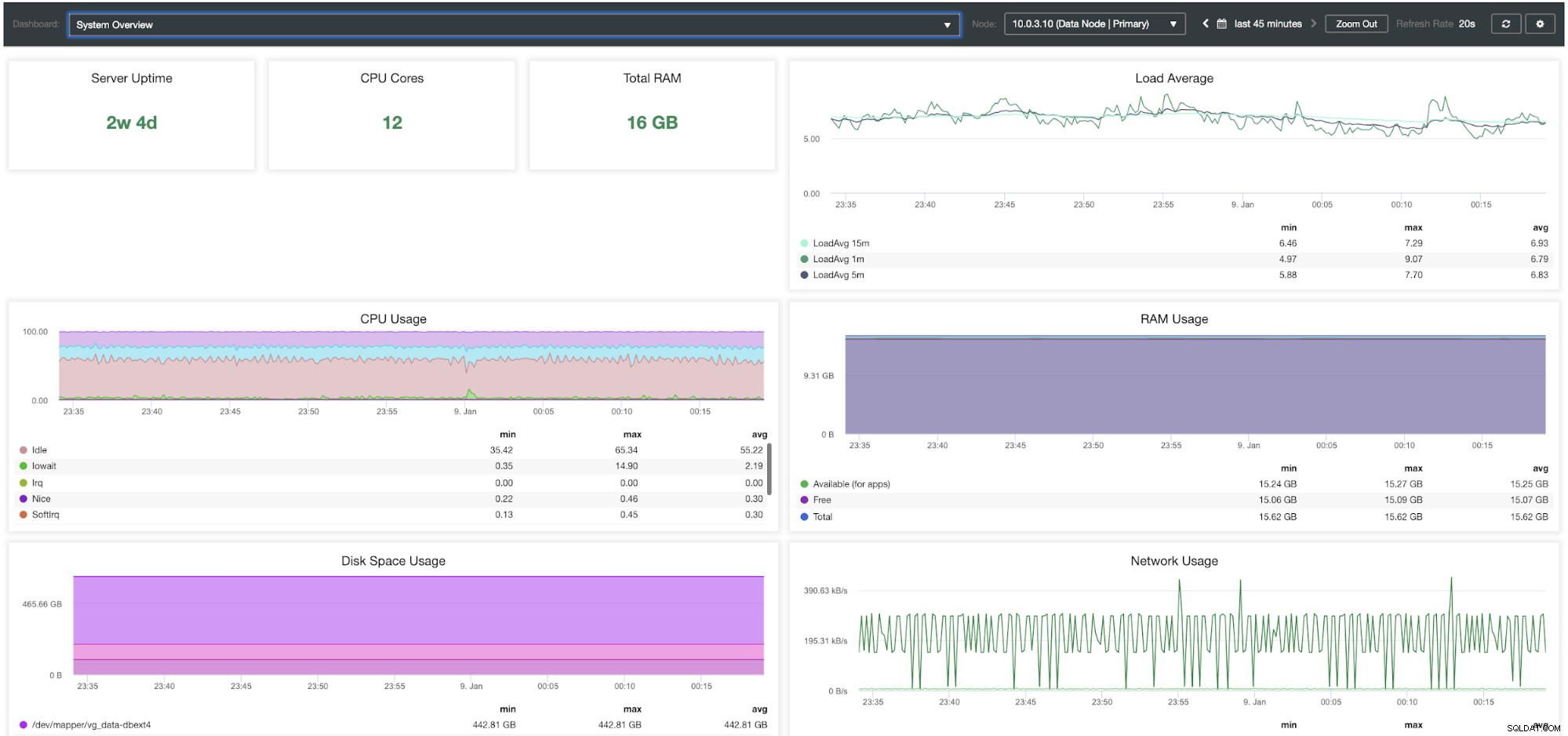 Painel de visão geral do sistema de controle de cluster
Painel de visão geral do sistema de controle de cluster| Visão geral do cluster | |
|---|---|
| Carga média 1m Carga média 5m Carga média 15m Memória disponível para aplicativos Rede TX Rede RX Leitura de disco IOPS Gravação de disco IOPS Gravação de disco + Leitura de IOPS |
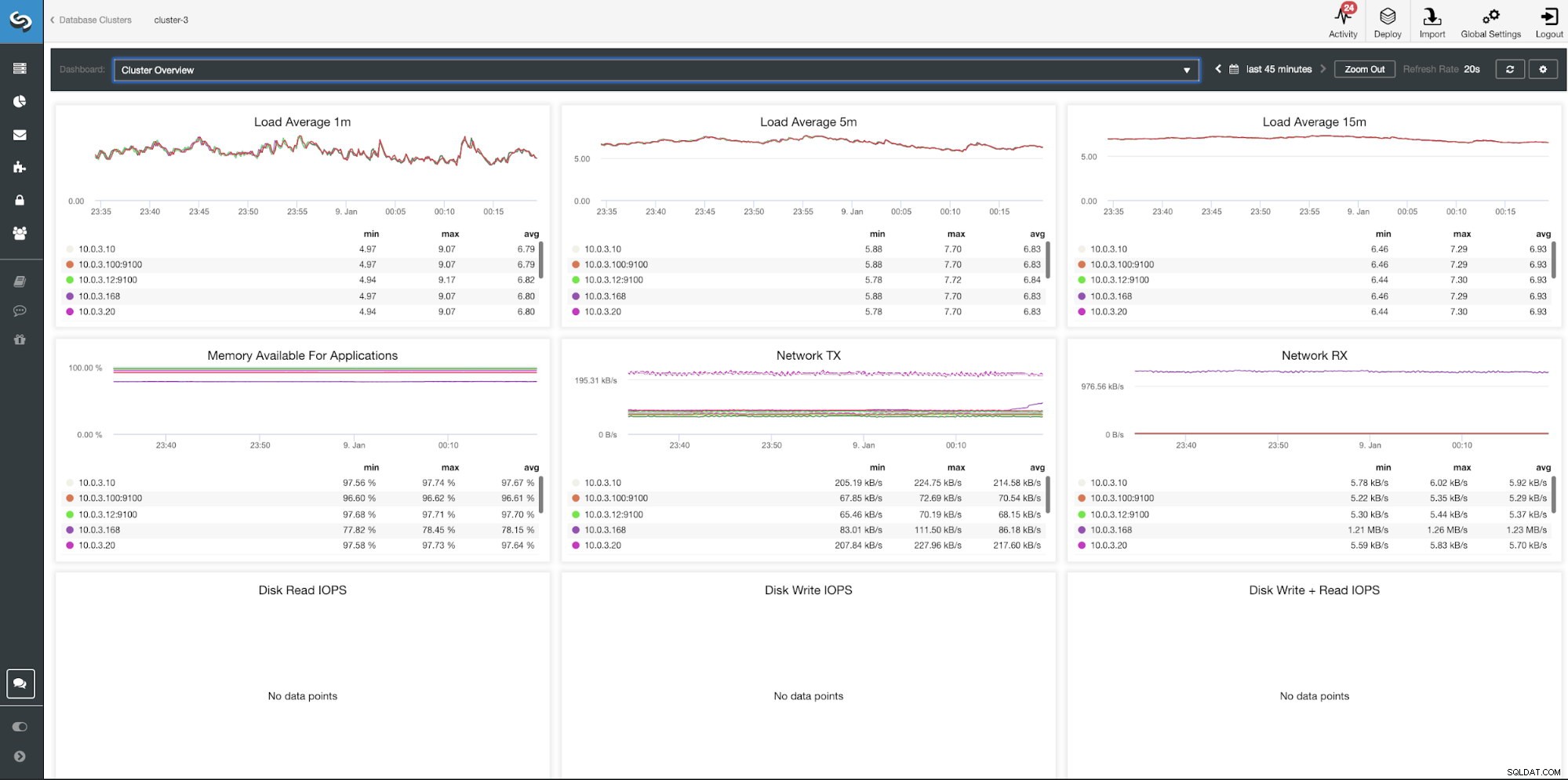 Painel de visão geral do cluster ClusterControl
Painel de visão geral do cluster ClusterControl Painel do servidor MongoDB
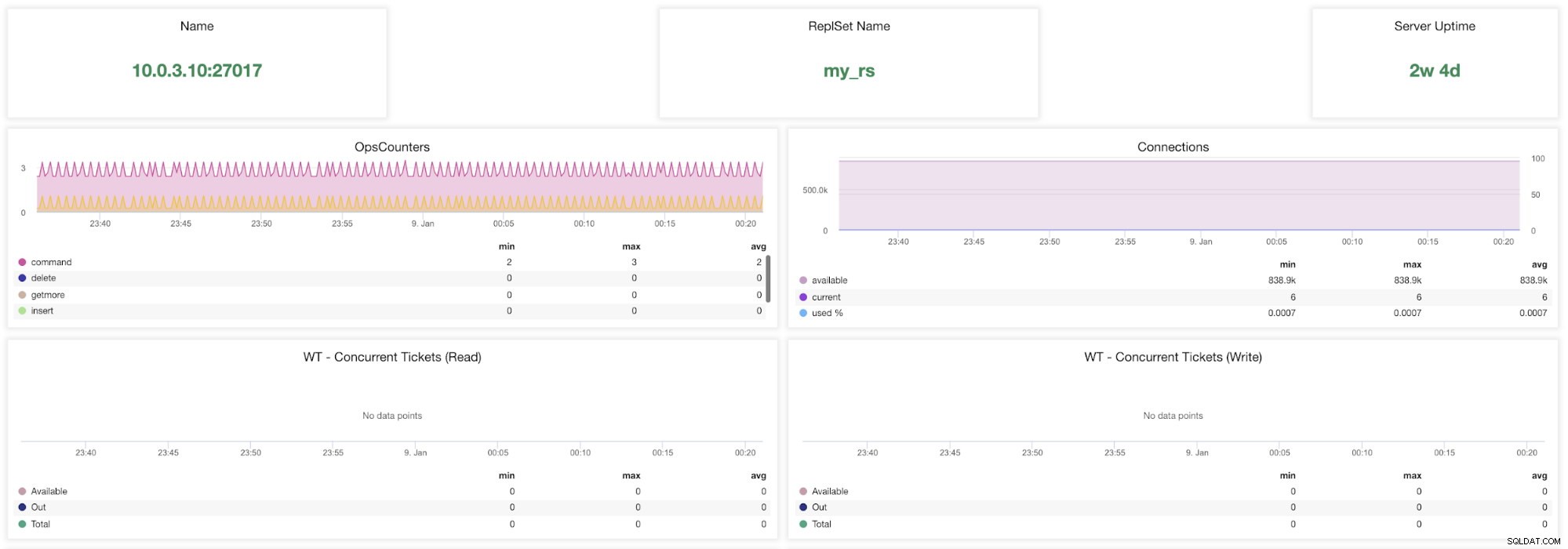 Métricas do MongoDB do ClusterControl
Métricas do MongoDB do ClusterControl Nome - Endereço do servidor e a porta.
Nome do RepsSet - Apresenta o nome do conjunto de réplicas ao qual o servidor pertence.
Tempo de atividade do servidor - Tempo desde a última reinicialização do servidor.
Counters de operações - Número de solicitações recebidas durante o período de tempo selecionado dividido pelo tipo de operação. Essas contagens incluem todas as operações recebidas, incluindo aquelas que não foram bem-sucedidas.
Conexões - Este gráfico mostra uma das métricas mais importantes a serem observadas - o número de conexões recebidas durante o período selecionado, incluindo solicitações malsucedidas. Cargas de tráfego anormais podem levar a problemas de desempenho. Se o MongoDB estiver com poucas conexões, talvez ele não consiga lidar com as solicitações recebidas em tempo hábil.
WT - Ingressos simultâneos (Leitura) / WT - Ingressos simultâneos (Gravação) Esses dois gráficos mostram tickets de leitura e gravação que controlam a simultaneidade no WiredTiger (WT). Os tickets WT controlam quantas operações de leitura e gravação podem ser executadas no mecanismo de armazenamento ao mesmo tempo. Quando os tíquetes de leitura e gravação disponíveis caem para zero, o número de operações em execução simultâneas é igual aos valores de leitura/gravação configurados. Isso significa que qualquer outra operação deve esperar até que um dos threads em execução termine seu trabalho no mecanismo de armazenamento antes de ser executado.
 Métricas do MongoDB do ClusterControl
Métricas do MongoDB do ClusterControl WT - Cache (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - O tamanho do cache é o botão mais importante para o WiredTiger. Por padrão, o MongoDB 3.x reserva 50% (60% em 3.2) da memória disponível para seu cache de dados.
Bloqueio Global (Cliente-Leitura, Cliente - Gravação, Fila Atual - Leitor, Fila Atual - Gravador) - Padrões de design de esquema ruins ou solicitações de leitura e gravação pesadas de muitos clientes podem causar bloqueios extensivos. Quando isso ocorre, é necessário manter a consistência e evitar conflitos de gravação.
Para conseguir isso, o MongoDB usa o bloqueio de multigranularidade, que permite que as operações de bloqueio ocorram em diferentes níveis, como global, banco de dados ou nível de coleção .
Declarações (msg, regular, rollovers, user) - Este gráfico mostra o número de declarações que são geradas a cada segundo. Valores altos e desvios de tendências devem ser revistos.
Painel de conjunto de réplicas do MongoDB
As métricas mostradas neste painel importam apenas se você usar um conjunto de réplicas.
 Métricas do ClusterControl MongoDB ReplicaSet
Métricas do ClusterControl MongoDB ReplicaSet Tamanho do conjunto de réplicas - O número de membros no conjunto de réplicas. A implantação do conjunto de réplicas padrão para o sistema de produção é um conjunto de réplicas de três membros. De um modo geral, é recomendado que um conjunto de réplicas tenha um número ímpar de membros votantes. A tolerância a falhas para um conjunto de réplicas é o número de membros que podem ficar indisponíveis e ainda deixar membros suficientes no conjunto para eleger um primário. A tolerância a falhas para três membros é um, para cinco é dois etc.
Nome do RepSet - É o nome atribuído no arquivo de configuração do MongoDB. O nome refere-se ao valor /etc/mongod.conf replSet.
PRIMÁRIO - O nó primário recebe todas as operações de gravação e registra todas as outras alterações em seu conjunto de dados em seu log de operações. O valor é identificar o IP e a porta do seu nó primário no cluster do conjunto de réplicas do MongoDB.
Versão do servidor - Identifique a versão do servidor. A versão 1.7.1 do ClusterControl é compatível com as versões 3.2/3.4/3.6/4.0 do MongoDB.
Conjuntos de réplicas e membros (min, max, avg) - Este gráfico pode ajudá-lo a identificar membros ativos durante o período de tempo. Você pode rastrear os números mínimo, máximo e médio de nós primários e secundários e como esses números mudaram ao longo do tempo. Qualquer desvio pode afetar a tolerância a falhas e a disponibilidade do cluster.
Janela de oplog por ReplSet - A janela de replicação é uma métrica essencial a ser observada. O oplog do MongoDB é uma coleção única que foi limitada em um tamanho (predefinido). Ele pode ser descrito como a diferença entre o primeiro e o último timestamp no oplog.rs. É a quantidade de tempo que um secundário pode ficar offline antes que a sincronização inicial seja necessária para sincronizar a instância. Essas métricas informam quanto tempo resta antes que nossa próxima transação seja retirada do oplog.
 Métricas do ClusterControl MongoDB ReplicaSet
Métricas do ClusterControl MongoDB ReplicaSet Espaço de replicação - Este gráfico apresenta a diferença entre a janela de oplog do primário e o atraso de replicação dos nós secundários. O oplog do MongoDB é limitado em tamanho e se o nó ficar muito atrasado, ele não poderá alcançá-lo. Se isso acontecer, a sincronização completa será emitida e esta é uma operação cara que deve ser evitada o tempo todo.
Total de PRIMÁRIO/SECUNDÁRIO online por ReplSet - Número total de nós de cluster durante o período de tempo.
Cursores abertos por ReplSet (fixado, tempo limite, total) - Uma solicitação de leitura vem com um cursor que é um ponteiro para o conjunto de dados do resultado. Ele permanecerá aberto no servidor e, portanto, consumirá memória, a menos que seja encerrado pela configuração padrão do MongoDB. Você deve identificar os cursores não ativos e cortá-los para economizar na memória.
ReplSet - Cursores de tempo limite por conjuntosMax Replication Lag per ReplSet - O atraso de replicação é muito importante para ficar de olho se você estiver dimensionando as leituras adicionando mais secundários. O MongoDB só usará esses secundários se eles não ficarem muito para trás. Se o secundário tiver atraso de replicação, você corre o risco de fornecer dados obsoletos que já foram substituídos no primário.
OplogSize - Certas cargas de trabalho podem exigir um tamanho de oplog maior. Atualizações para vários documentos de uma vez, exclusões equivalem à mesma quantidade de dados que uma inserção ou o número significativo de atualizações in-loco.
OpsConters - Este gráfico mostra o número de execuções de consultas.
Tempo de ping para membro do conjunto de réplicas do principal - Isso permite descobrir membros do conjunto de réplicas que estão inativos ou inacessíveis a partir do nó primário.
Observações finais
O novo recurso de painel do MongoDB ClusterControl 1.7.1 está disponível gratuitamente no Community Edition. As equipes de operações de banco de dados podem lucrar com isso usando os gráficos de alta resolução, especialmente ao realizar suas rotinas diárias como análises de causa raiz e planejamento de capacidade.
É apenas uma questão de um clique para implantar novos agentes de monitoramento. O ClusterControl instala os agentes do Prometheus, configura as métricas e mantém o acesso à configuração dos exportadores do Prometheus por meio de sua GUI, para que você possa gerenciar melhor a configuração dos parâmetros, como sinalizadores do coletor para os exportadores (Prometheus).
Ao monitorar adequadamente o número de solicitações de leitura e gravação, você pode evitar a sobrecarga de recursos, encontrar rapidamente a origem de possíveis sobrecargas e saber quando aumentar.



