Como você gostaria de mesclar o processo "top" para todos os seus 5 nós de banco de dados e classificar pelo uso da CPU com apenas um comando de uma linha? Sim, você leu certo! Que tal exibir gráficos interativos na interface do terminal? Apresentamos o cliente CLI para ClusterControl chamado s9s há cerca de um ano e tem sido um ótimo complemento para a interface da web. Também é de código aberto..
Nesta postagem do blog, mostraremos como você pode monitorar seus bancos de dados usando seu terminal e a CLI do s9s.
Introdução ao s9s, a CLI do ClusterControl
ClusterControl CLI (ou s9s ou s9s CLI), é um projeto de código aberto e pacote opcional introduzido com o ClusterControl versão 1.4.1. É uma ferramenta de linha de comando para interagir, controlar e gerenciar sua infraestrutura de banco de dados usando o ClusterControl. O projeto de linha de comando s9s é de código aberto e pode ser encontrado no GitHub.
A partir da versão 1.4.1, o script do instalador instalará automaticamente o pacote (s9s-tools) no nó ClusterControl.
Alguns pré-requisitos. Para executar a CLI do s9s-tools, o seguinte deve ser verdadeiro:
- Um ClusterControl Controller (cmon) em execução.
- cliente s9s, instale como um pacote separado.
- A porta 9501 deve ser acessível pelo cliente s9s.
A instalação da CLI do s9s é simples se você a instalar no próprio host do ClusterControl Controller:$ rm
$ rm -Rf ~/.s9s
$ wget https://repo.severalnines.com/s9s-tools/install-s9s-tools.sh
$ ./install-s9s-tools.shVocê pode instalar s9s-tools fora do servidor ClusterControl (sua estação de trabalho laptop ou bastion host), desde que a interface RPC (TLS) do ClusterControl Controller esteja exposta à rede pública (padrão 127.0.0.1:9501). Você pode encontrar mais detalhes sobre como configurar isso na página de documentação.
Para verificar se você pode se conectar à interface RPC do ClusterControl corretamente, você deve obter a resposta OK ao executar o seguinte comando:
$ s9s cluster --ping
PING OK 2.000 msComo nota lateral, observe também as limitações ao usar esta ferramenta.
Exemplo de implantação
Nossa implantação de exemplo consiste em 8 nós em 3 clusters:
- Replicação de streaming do PostgreSQL - 1 mestre, 2 escravos
- Replicação MySQL - 1 mestre, 1 escravo
- Conjunto de réplicas do MongoDB - 1 nó principal e 2 nós secundários
Todos os clusters de banco de dados foram implantados pelo ClusterControl usando o assistente de implantação "Deploy Database Cluster" e, do ponto de vista da interface do usuário, é isso que veríamos no painel do cluster:
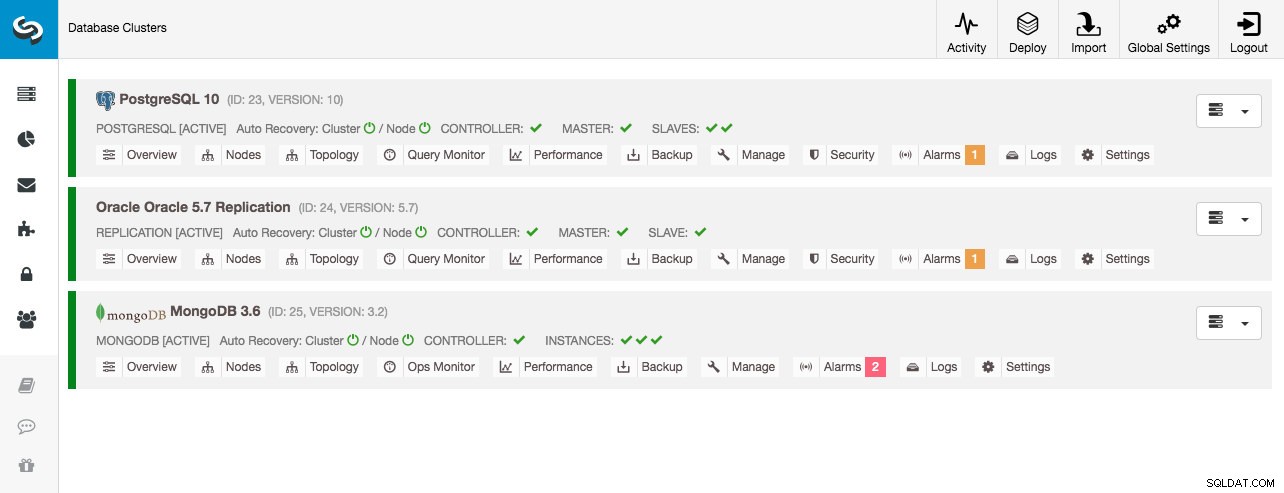
Monitoramento de cluster
Vamos começar listando os clusters:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
23 STARTED postgresql_single system admins PostgreSQL 10 All nodes are operational.
24 STARTED replication system admins Oracle 5.7 Replication All nodes are operational.
25 STARTED mongodb system admins MongoDB 3.6 All nodes are operational.Vemos os mesmos clusters que a interface do usuário. Podemos obter mais detalhes sobre o cluster específico usando o sinalizador --stat. Vários clusters e nós também podem ser monitorados dessa maneira, as opções de linha de comando podem até usar curingas nos nomes de nó e cluster:
$ s9s cluster --stat *Replication
Oracle 5.7 Replication Name: Oracle 5.7 Replication Owner: system/admins
ID: 24 State: STARTED
Type: REPLICATION Vendor: oracle 5.7
Status: All nodes are operational.
Alarms: 0 crit 1 warn
Jobs: 0 abort 0 defnd 0 dequd 0 faild 7 finsd 0 runng
Config: '/etc/cmon.d/cmon_24.cnf'
LogFile: '/var/log/cmon_24.log'
HOSTNAME CPU MEMORY SWAP DISK NICs
10.0.0.104 1 6% 992M 120M 0B 0B 19G 13G 10K/s 54K/s
10.0.0.168 1 6% 992M 116M 0B 0B 19G 13G 11K/s 66K/s
10.0.0.156 2 39% 3.6G 2.4G 0B 0B 19G 3.3G 338K/s 79K/sA saída acima fornece um resumo de nossa replicação MySQL junto com o status do cluster, estado, fornecedor, arquivo de configuração e assim por diante. Abaixo, você pode ver a lista de nós que se enquadram nesse ID de cluster com uma visão resumida dos recursos do sistema para cada host, como número de CPUs, memória total, uso de memória, disco de troca e interfaces de rede. Todas as informações mostradas são recuperadas do banco de dados CMON, não diretamente dos nós reais.
Você também pode obter uma visão resumida de todos os bancos de dados em todos os clusters:
$ s9s cluster --list-databases --long
SIZE #TBL #ROWS OWNER GROUP CLUSTER DATABASE
7,340,032 0 0 system admins PostgreSQL 10 postgres
7,340,032 0 0 system admins PostgreSQL 10 template1
7,340,032 0 0 system admins PostgreSQL 10 template0
765,460,480 24 2,399,611 system admins PostgreSQL 10 sbtest
0 101 - system admins Oracle 5.7 Replication sys
Total: 5 databases, 789,577,728, 125 tables.A última linha resume que temos um total de 5 bancos de dados com 125 tabelas, 4 delas estão em nosso cluster PostgreSQL.
Para obter um exemplo completo de uso nas opções de linha de comando do cluster s9s, confira a documentação do cluster s9s.
Monitoramento de nós
Para monitoramento de nós, a CLI do s9s possui recursos semelhantes com a opção de cluster. Para obter uma visão resumida de todos os nós, você pode simplesmente fazer:
$ s9s node --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.6.2.2662 23 PostgreSQL 10 10.0.0.156 9500 Up and running
poM- 10.4 23 PostgreSQL 10 10.0.0.44 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.58 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.60 5432 Up and running
soS- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.104 3306 Up and running.
coC- 1.6.2.2662 24 Oracle 5.7 Replication 10.0.0.156 9500 Up and running
soM- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.168 3306 Up and running.
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.125 27017 Up and Running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.131 27017 Up and Running
coC- 1.6.2.2662 25 MongoDB 3.6 10.0.0.156 9500 Up and running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.35 27017 Up and Running
Total: 11A coluna mais à esquerda especifica o tipo do nó. Para esta implantação, "c" representa o ClusterControl Controller, 'p" para PostgreSQL, "m" para MongoDB, "e" para Memcached e s para nós MySQL genéricos. O próximo é o status do host - "o" para online, " l" para off-line, "f" para nós com falha e assim por diante. O próximo é o papel do nó no cluster. Pode ser M para mestre, S para escravo, C para controlador e - para todo o resto. As colunas restantes são bastante auto-explicativas.
Você pode obter toda a lista olhando a página man deste componente:
$ man s9s-nodeA partir daí, podemos pular para estatísticas mais detalhadas para todos os nós com o sinalizador --stats:
$ s9s node --stat --cluster-id=24
10.0.0.104:3306
Name: 10.0.0.104 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.104 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: slave
OS: centos 7.0.1406 core Access: read-only
VM ID: -
Version: 5.7.23-log
Message: Up and running.
LastSeen: Just now SSH: 0 fail(s)
Connect: y Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 16592 Uptime: 01:44:38
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.168:3306
Name: 10.0.0.168 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.168 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: master
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 5.7.23-log
Message: Up and running.
Slaves: 10.0.0.104:3306
LastSeen: Just now SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 975 Uptime: 01:52:53
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.156:9500
Name: 10.0.0.156 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.156 Port: 9500
Alias: - Owner: system/admins
Class: CmonHost Type: controller
Status: CmonHostOnline Role: controller
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 1.6.2.2662
Message: Up and running
LastSeen: 28 seconds ago SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: n SuperReadOnly: n
Pid: 12746 Uptime: 01:10:05
Config: ''
LogFile: '/var/log/cmon_24.log'
PidFile: ''
DataDir: ''Imprimir gráficos com o cliente s9s também pode ser muito informativo. Isso apresenta os dados que o controlador coletou em vários gráficos. Existem quase 30 gráficos suportados por esta ferramenta conforme listado aqui e o s9s-node enumera todos eles. O seguinte mostra o histograma de carga do servidor de todos os nós para o cluster ID 1 conforme coletado pelo CMON, diretamente do seu terminal:
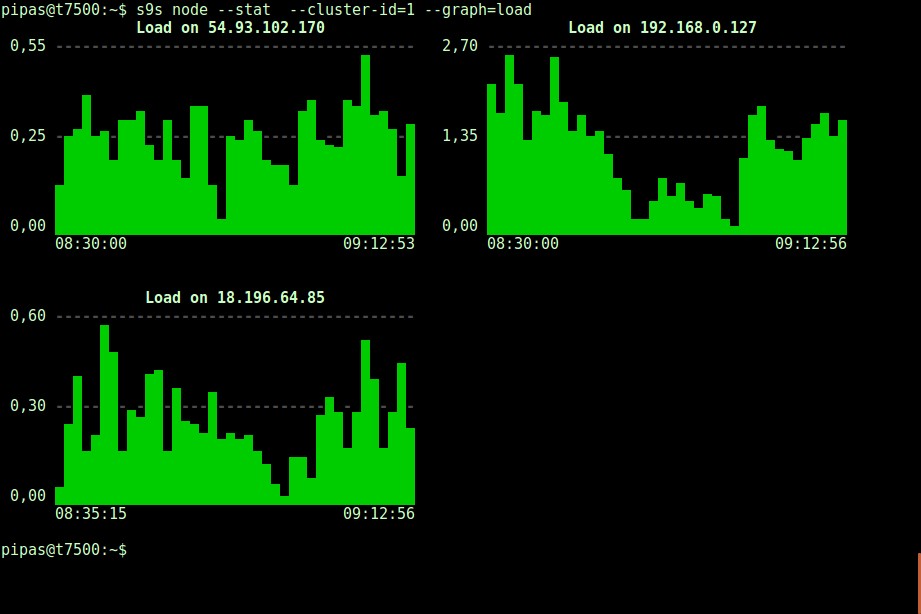
É possível definir a data e hora de início e fim. Pode-se visualizar períodos curtos (como a última hora) ou períodos mais longos (como uma semana ou um mês). Veja a seguir um exemplo de visualização da utilização do disco na última hora:
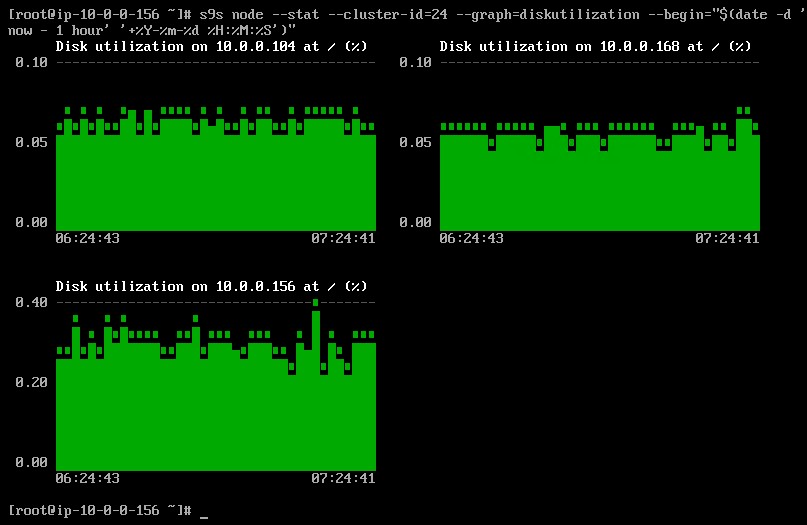
Usando a opção --density, uma visualização diferente pode ser impressa para cada gráfico. Este gráfico de densidade mostra não a série temporal, mas a frequência com que os valores fornecidos foram vistos (o eixo X representa o valor da densidade):
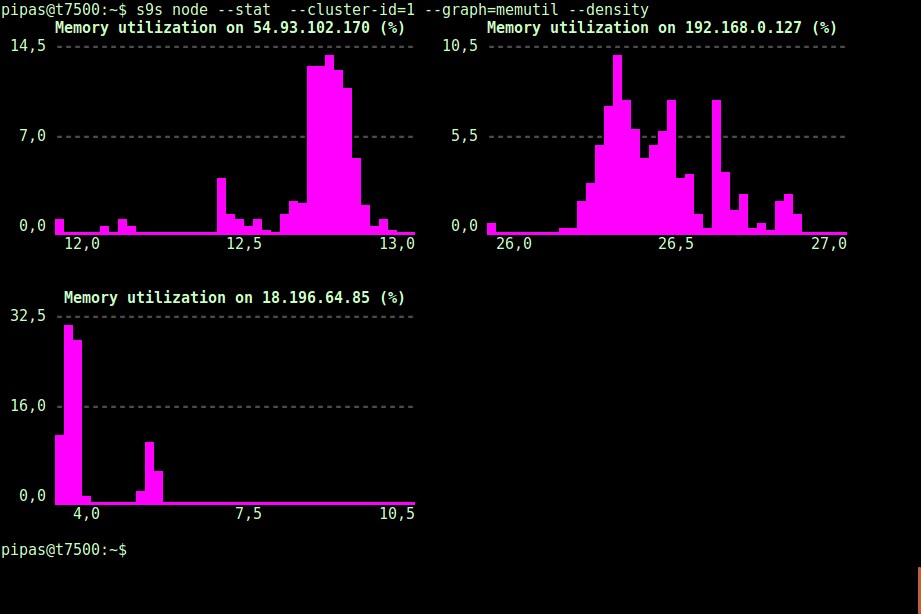
Se o terminal não suportar caracteres Unicode, a opção --only-ascii pode desativá-los:
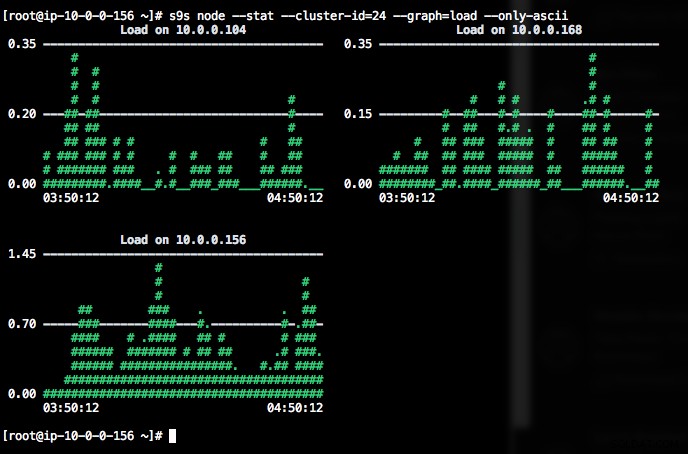
Os gráficos têm cores, onde valores perigosamente altos, por exemplo, são mostrados em vermelho. A lista de nós pode ser filtrada com a opção --nodes, onde você pode especificar os nomes dos nós ou usar curingas, se conveniente.
Monitoramento de Processo
Outra coisa legal sobre o s9s CLI é que ele fornece uma lista de processos de todo o cluster - um “topo” para todos os nós, todos os processos mesclados em um. O comando a seguir executa o comando "top" em todos os nós do banco de dados para o cluster ID 24, classificado pelo maior consumo de CPU e atualizado continuamente:
$ s9s process --top --cluster-id=24
Oracle 5.7 Replication - 04:39:17 All nodes are operational.
3 hosts, 4 cores, 10.6 us, 4.2 sy, 84.6 id, 0.1 wa, 0.3 st,
GiB Mem : 5.5 total, 1.7 free, 2.6 used, 0.1 buffers, 1.1 cached
GiB Swap: 0 total, 0 used, 0 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
12746 root 10.0.0.156 20 1359348 58976 S 25.25 1.56 cmon
1587 apache 10.0.0.156 20 462572 21632 S 1.38 0.57 httpd
390 root 10.0.0.156 20 4356 584 S 1.32 0.02 rngd
975 mysql 10.0.0.168 20 1144260 71936 S 1.11 7.08 mysqld
16592 mysql 10.0.0.104 20 1144808 75976 S 1.11 7.48 mysqld
22983 root 10.0.0.104 20 127368 5308 S 0.92 0.52 sshd
22548 root 10.0.0.168 20 127368 5304 S 0.83 0.52 sshd
1632 mysql 10.0.0.156 20 3578232 1803336 S 0.50 47.65 mysqld
470 proxysql 10.0.0.156 20 167956 35300 S 0.44 0.93 proxysql
338 root 10.0.0.104 20 4304 600 S 0.37 0.06 rngd
351 root 10.0.0.168 20 4304 600 R 0.28 0.06 rngd
24 root 10.0.0.156 20 0 0 S 0.19 0.00 rcu_sched
785 root 10.0.0.156 20 454112 11092 S 0.13 0.29 httpd
26 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/1
25 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/0
22498 root 10.0.0.168 20 127368 5200 S 0.09 0.51 sshd
14538 root 10.0.0.104 20 0 0 S 0.09 0.00 kworker/0:1
22933 root 10.0.0.104 20 127368 5200 S 0.09 0.51 sshd
28295 root 10.0.0.156 20 127452 5016 S 0.06 0.13 sshd
2238 root 10.0.0.156 20 197520 10444 S 0.06 0.28 vc-agent-007
419 root 10.0.0.156 20 34764 1660 S 0.06 0.04 systemd-logind
1 root 10.0.0.156 20 47628 3560 S 0.06 0.09 systemd
27992 proxysql 10.0.0.156 20 11688 872 S 0.00 0.02 proxysql_galera
28036 proxysql 10.0.0.156 20 11688 876 S 0.00 0.02 proxysql_galeraHá também um sinalizador --list que retorna um resultado semelhante sem atualização contínua (semelhante ao comando "ps"):
$ s9s process --list --cluster-id=25Monitoramento de Trabalho
Jobs são tarefas executadas pelo controlador em segundo plano, para que o aplicativo cliente não precise esperar até que todo o trabalho seja concluído. O ClusterControl executa tarefas de gerenciamento atribuindo um ID para cada tarefa e permite que o agendador interno decida se dois ou mais trabalhos podem ser executados em paralelo. Por exemplo, mais de uma implantação de cluster pode ser executada simultaneamente, bem como outras operações de longa duração, como backup e upload automático de backups para armazenamento em nuvem.
Em qualquer operação de gerenciamento, seria útil se pudéssemos monitorar o progresso e o status de um trabalho específico, como, por exemplo, dimensionar um novo escravo para nossa replicação do MySQL. O comando a seguir adiciona um novo escravo, 10.0.0.77 para dimensionar nossa replicação MySQL:
$ s9s cluster --add-node --nodes="10.0.0.77" --cluster-id=24
Job with ID 66992 registered.Podemos então monitorar o jobID 66992 usando a opção de trabalho:
$ s9s job --log --job-id=66992
addNode: Verifying job parameters.
10.0.0.77:3306: Adding host to cluster.
10.0.0.77:3306: Testing SSH to host.
10.0.0.77:3306: Installing node.
10.0.0.77:3306: Setup new node (installSoftware = true).
10.0.0.77:3306: Setting SELinux in permissive mode.
10.0.0.77:3306: Disabling firewall.
10.0.0.77:3306: Setting vm.swappiness = 1
10.0.0.77:3306: Installing software.
10.0.0.77:3306: Setting up repositories.
10.0.0.77:3306: Installing helper packages.
10.0.0.77: Upgrading nss.
10.0.0.77: Upgrading ca-certificates.
10.0.0.77: Installing socat.
...
10.0.0.77: Installing pigz.
10.0.0.77: Installing bzip2.
10.0.0.77: Installing iproute2.
10.0.0.77: Installing tar.
10.0.0.77: Installing openssl.
10.0.0.77: Upgrading openssl openssl-libs.
10.0.0.77: Finished with helper packages.
10.0.0.77:3306: Verifying helper packages (checking if socat is installed successfully).
10.0.0.77:3306: Uninstalling existing MySQL packages.
10.0.0.77:3306: Installing replication software, vendor oracle, version 5.7.
10.0.0.77:3306: Installing software.
...Ou podemos usar o sinalizador --wait e obter um spinner com barra de progresso:
$ s9s job --wait --job-id=66992
Add Node to Cluster
- Job 66992 RUNNING [ █] ---% Add New Node to ClusterÉ isso para o suplemento de monitoramento de hoje. Esperamos que você experimente a CLI e obtenha valor dela. Agrupamento feliz



