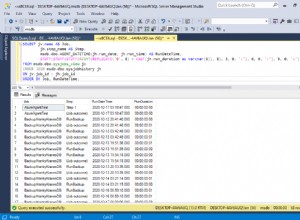
Esse tipo de requisito (onde você precisa do máximo ou mínimo por uma coluna, agrupado por outra, mas precisa de todos os dados da linha máxima ou mínima) é basicamente o que funções analíticas são para. Eu usei
row_number - se os empates forem possíveis, você precisa esclarecer a atribuição (veja meu comentário na sua pergunta) e, dependendo dos detalhes, outra função analítica pode ser mais apropriada - talvez rank() . with
my_table ( id, name, ref, dt, frm ) as (
select 10, 'Ant' , 100, date '2017-02-02', 'David' from dual union all
select 10, 'Ant' , 300, date '2016-01-01', 'David' from dual union all
select 2, 'Cat' , 90, date '2017-09-09', 'David' from dual union all
select 2, 'Cat' , 500, date '2016-02-03', 'David' from dual union all
select 3, 'Bird', 150, date '2017-06-28', 'David' from dual
)
-- End of simulated table (for testing purposes only, not part of the solution).
-- SQL query begins BELOW THIS LINE.
select id, name, ref, dt, frm
from (
select id, name, ref, dt, frm,
row_number() over (partition by id order by ref desc, dt desc) as rn
from my_table
)
where rn = 1
order by dt desc
;
ID NAME REF DT FRM
-- ---- --- ---------- -----
3 Bird 150 2017-06-28 David
2 Cat 500 2016-02-03 David
10 Ant 300 2016-01-01 David