Eu estava brincando com o Result Cache outro dia... eu sei... esse não é um recurso novo e está disponível há algum tempo. Infelizmente, pode demorar um pouco para chegar às coisas, eu acho.
No meu teste simples, tive uma consulta que exibiu esse comportamento:
select
max(det.invoice_date)
from
invoices i
join
invoice_detail det
on i.dept_id=det.dept_id
call count cpu elapsed disk query current rows
------- ------ ------- -------- ---------- ---------- --------- ---------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 2.77 6.66 75521 75583 0 1
------- ------ ------- -------- ---------- ---------- ---------- ---------
total 4 2.77 6.67 75521 75583 0 1
75.000 leituras de disco para retornar 1 linha. Ai! Agora execute isso através do Cache de Resultados e obtenha alguns números muito bons. 🙂
select
/*+ result_cache */
max(det.invoice_date)
from
invoices i
join
invoice_detail det
on i.dept_id=det.dept_id
call count cpu elapsed disk query current rows
------- ------ ------ --------- ---------- ---------- ---------- ---------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 0 0 1
------- ------ ------ --------- ---------- ---------- ---------- ---------
total 4 0.00 0.00 0 0 0 1
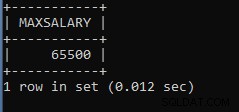
Ainda 1 linha retornou, mas zero leituras de disco, zero blocos atuais e basicamente zero tempo decorrido. Legal!
O Result Cache funciona melhor ao retornar um pequeno número de linhas em tabelas que não são alteradas com frequência. As operações DML nas tabelas subjacentes invalidarão a entrada do Cache de Resultados e o trabalho precisará ser executado novamente antes de ser armazenado no Cache de Resultados.
Em breve, quando tiver uma chance, descobrirei o impacto das variáveis de vinculação nas consultas que usam o Cache de Resultados.