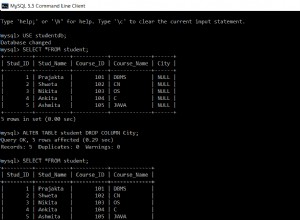
Supondo que o desempenho máximo seja o objetivo, o ideal é escolher
SUBSTR(my_field,1,6) e crie um índice baseado em função para dar suporte à consulta. CREATE INDEX my_substr_idx
ON my_table( substr( my_field,1,6 ) );
Como outros apontam,
SUBSTR(my_field,1,6) não seria capaz de usar um índice regular em MY_FIELD . A versão LIKE pode usar o índice, mas as estimativas de cardinalidade do otimizador nesse caso são geralmente bastante ruins, então é bem provável que não use um índice quando for útil ou use um índice quando uma varredura de tabela for preferível. Indexar a expressão real dará ao otimizador muito mais informações para trabalhar, portanto, é muito mais provável que ele escolha o índice corretamente. Alguém mais inteligente do que eu pode sugerir uma maneira de usar estatísticas em colunas virtuais em 11g para fornecer ao otimizador melhores informações para a consulta LIKE. Se 6 for uma variável (ou seja, você às vezes deseja pesquisar os primeiros 6 caracteres e às vezes deseja pesquisar um número diferente), provavelmente não poderá criar um índice baseado em função para oferecer suporte a essa consulta. Nesse caso, você provavelmente está melhor com os caprichos das decisões do otimizador com a formulação LIKE.