Um desenvolvedor Oracle que costuma usar expressões regulares no código mais cedo ou mais tarde pode enfrentar um fenômeno que é realmente místico. Pesquisas de longo prazo pela raiz do problema podem levar à perda de peso, apetite e provocar vários tipos de distúrbios psicossomáticos – tudo isso pode ser evitado com a ajuda da função regexp_replace. Pode ter até 6 argumentos:
REGEXP_REPLACE (
- source_string,
- modelo,
- substituting_string,
- a posição inicial da pesquisa de correspondência com um modelo (padrão 1),
- uma posição de ocorrência do modelo em uma string de origem (por padrão, 0 é igual a todas as ocorrências),
- modificador (até agora é um azarão)
)
Retorna a source_string modificada na qual todas as ocorrências do template são substituídas pelo valor passado no parâmetro substituting_string. Muitas vezes é usada uma versão curta da função, onde são especificados os 3 primeiros argumentos, o que é suficiente para resolver muitos problemas. Eu vou fazer o mesmo. Suponha que precisamos mascarar todos os caracteres de string com asteriscos na string ‘MASK:lowercase’. Para especificar o intervalo de caracteres minúsculos, o padrão ‘[a-z]‘ deve ser adequado.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Expectativa
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Realidade
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Se este evento não foi reproduzido em seu banco de dados, você está com sorte até agora. Mas com mais frequência você começa a cavar no código, converte strings de um conjunto de caracteres para outro e, eventualmente, chega o desespero.
Definindo um problema
A questão surge - o que há de tão especial na letra 'A' que ela não foi substituída porque o restante dos caracteres maiúsculos também não deveria ser substituído. Talvez existam outras letras corretas, exceto esta. É necessário olhar para todo o alfabeto de caracteres maiúsculos.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ No entanto
Se o 6º argumento da função não for especificado explicitamente, por exemplo, 'i' não diferencia maiúsculas de minúsculas ou 'c' diferencia maiúsculas de minúsculas ao comparar uma string de origem com um modelo, o expressão regular usa o parâmetro NLS_SORT da sessão/banco de dados por padrão. Por exemplo:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Este parâmetro especifica o método de classificação em ORDER BY. Se falamos em classificar caracteres individuais simples, um certo número binário (código NLSSORT) corresponde a cada um deles e a classificação realmente ocorre pelo valor desses números.
Para ilustrar isso, vamos pegar os primeiros e últimos caracteres do alfabeto, tanto em letras minúsculas quanto em maiúsculas, e colocá-los em um conjunto de tabelas condicionalmente não ordenado e chamá-lo de ABC. Então, vamos classificar este conjunto pelo campo SYMBOL e exibir seu código NLSSORT no formato HEX ao lado de cada símbolo.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol 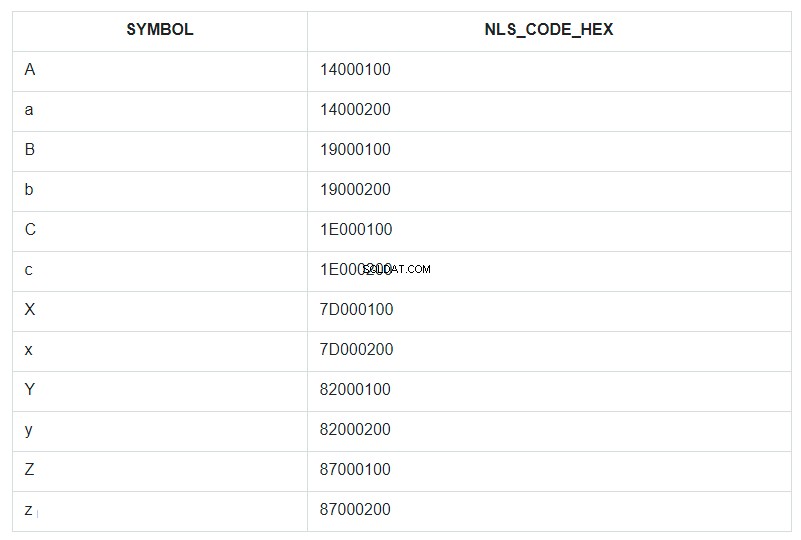
Na consulta, ORDER BY é especificado para o campo SYMBOL, mas na verdade, no banco de dados, a ordenação passou pelos valores do campo NLS_CODE_HEX.
Agora, volte para o intervalo do modelo e olhe para a tabela - o que é vertical entre o símbolo 'a' (código 14000200) e 'z' (código 87000200)? Tudo, exceto a letra maiúscula ‘A’. Isso é tudo o que foi substituído por um asterisco. E o código 14000100 da letra ‘A’ não está incluído na faixa de substituição de 14000200 a 87000200.
Cura
Especifique explicitamente o modificador de diferenciação de maiúsculas e minúsculas
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Algumas fontes dizem que o modificador 'c' é definido por padrão, mas acabamos de ver que isso não é bem verdade. E se alguém não o viu, então o parâmetro NLS_SORT de sua sessão/banco de dados provavelmente está definido como BINARY e a classificação é realizada em correspondência com códigos reais de caracteres. De fato, se você alterar o parâmetro de sessão, o problema será resolvido.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Os testes foram realizados no Oracle 12c.
Fique à vontade para deixar seus comentários e se cuide.