Resumo:
Eu executei cada consulta 10 vezes cada usando o conjunto de dados de teste abaixo.
- Um conjunto de resultados de subconsulta muito grande (100.000 linhas)
- Linhas duplicadas
- Linhas nulas
Para todos os cenários acima, tanto
IN e EXISTS realizado de maneira idêntica. Algumas informações sobre o banco de dados Performance V3 usado para testar.20.000 clientes com 1.000.000 pedidos, de modo que cada cliente é duplicado aleatoriamente (em um intervalo de 10 a 100) na tabela de pedidos.
Custo de execução, tempo:
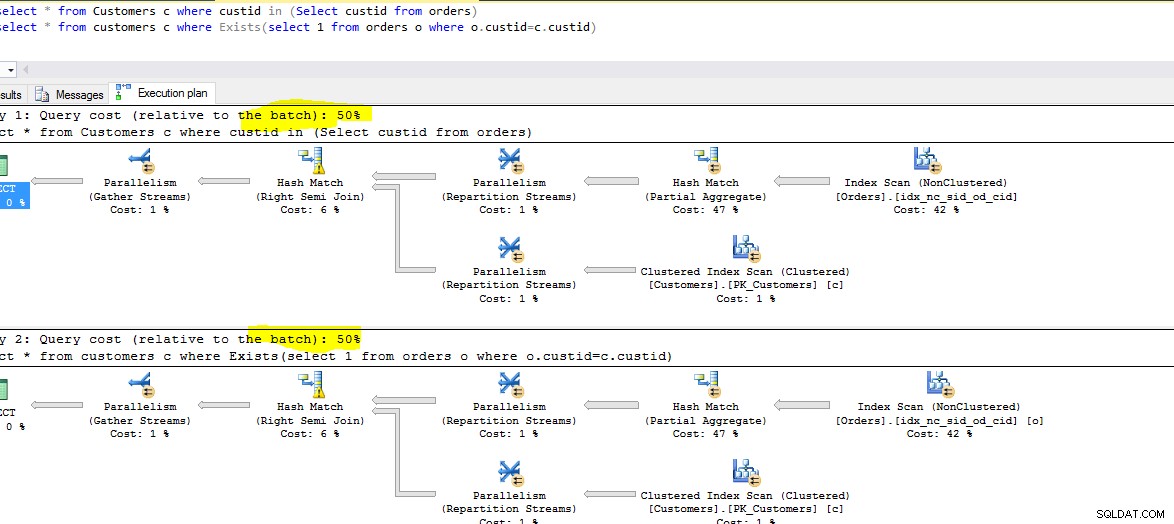
Abaixo está a captura de tela de ambas as consultas em execução. Observe o custo relativo de cada consulta.
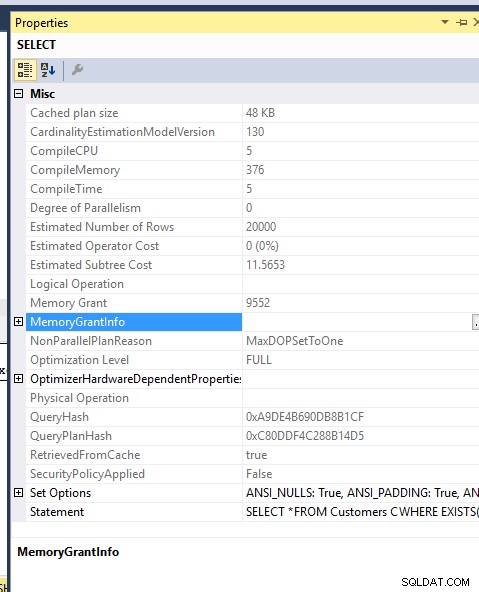
Custo de memória:
A concessão de memória para as duas consultas também é a mesma.. Forcei o MDOP 1 para não derramá-las no TEMPDB..
Tempo de CPU ,Lê:
Para Existe:
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 469 ms, elapsed time = 595 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Para IN:
(20000 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 547 ms, elapsed time = 669 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Em cada caso, o otimizador é inteligente o suficiente para reorganizar as consultas.
Eu costumo usar
EXISTS apenas embora (minha opinião). Um caso de uso para usar EXISTS é quando você não deseja retornar um segundo conjunto de resultados da tabela. Atualização de acordo com as consultas de Martin Smith:
Executei as consultas abaixo para encontrar a maneira mais eficaz de obter linhas da primeira tabela para as quais existe uma referência na segunda tabela.
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
SELECT *
FROM Customers C
WHERE EXISTS(SELECT 1 FROM Orders o WHERE o.custid = c.custid)
SELECT *
FROM Customers c
WHERE custid IN (SELECT custid FROM Orders)
Todas as consultas acima compartilham o mesmo custo, com exceção da 2ª
INNER JOIN , Plano sendo o mesmo para o resto. 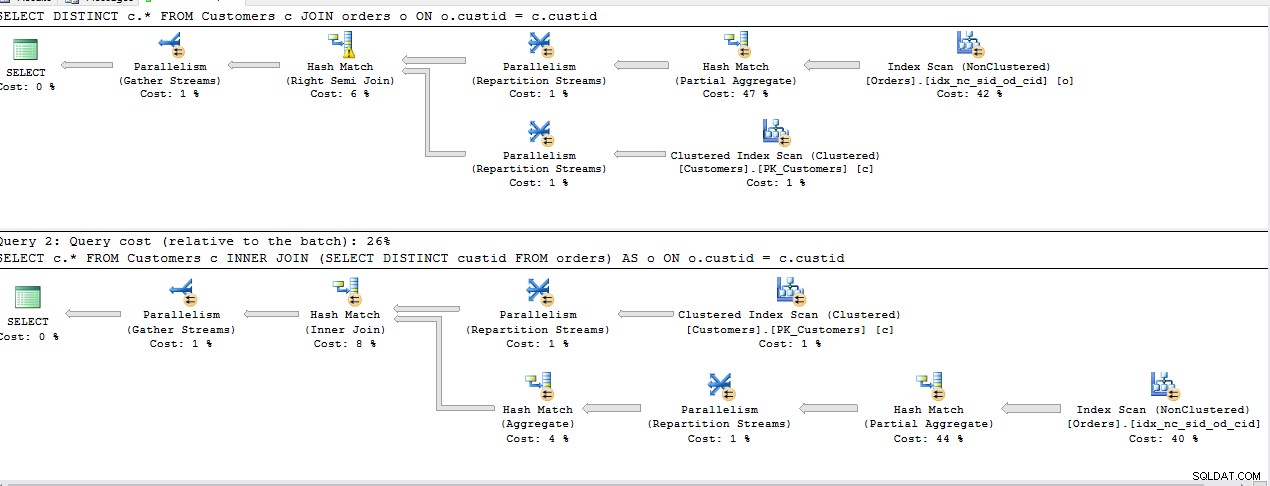
Concessão de memória:
Esta consulta
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
necessária concessão de memória de
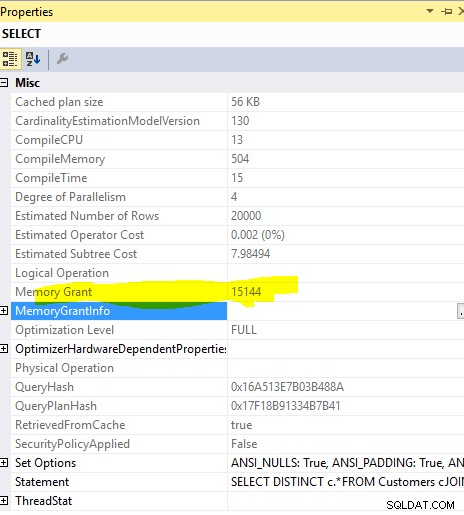
Esta consulta
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
necessária concessão de memória de ..
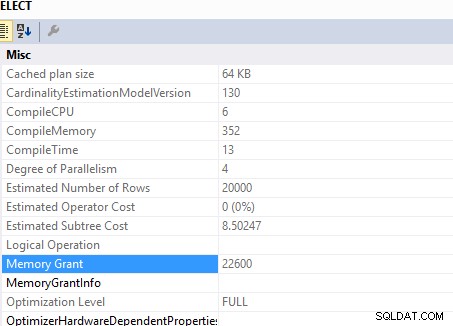
Tempo de CPU, leituras:
Para consulta:
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 48, logical reads 1344, physical reads 96, read-ahead reads 1248, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms, elapsed time = 781 ms.
Para consulta:
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1499 ms, elapsed time = 403 ms.