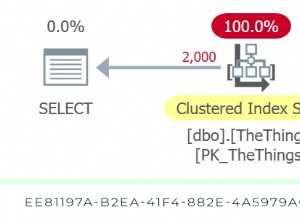
Se a tabela tiver um índice clusterizado exclusivo , o "localizador de linha" consiste nas colunas do índice clusterizado.
Com um índice clusterizado não exclusivo , o "localizador de linha" consiste nas colunas do índice clusterizado, além de um novo campo que o SQL Server adiciona para tornar a referência exclusiva. O novo campo é invisível para os usuários. É chamado de "unificador" e consiste em quatro bytes.
Em uma tabela sem um índice clusterizado (também conhecido como heap), o "localizador de linha" é um RID ou identificador de linha. O RID aponta para um local físico. Ele consiste no identificador do arquivo (ID), número da página e número da linha na página.
Uma consequência prática do "localizador de linha" é que faz sentido ter uma pequena chave primária para uma tabela com muitos índices :) Detalhes completos nesta página do MSDN.