Espero ter entendido corretamente. Então vou repetir.
- Você tem 1 tabela com muitas entradas
- Você tem esta lista do Excel onde você pesquisa a "coluna de pesquisa"
- Em caso de correspondência, substitua o valor inteiro por "substituir coluna"
Se este for o caso, então esta pode ser a solução:
declare @data table (Column1 nvarchar(50))
insert into @data
(Column1)
values (N'RbC investment for Seniors 65+'),
(N'RBC inv for juniors')
declare @replace table
(
OriginalValue nvarchar(50),
NewValue nvarchar(50),
[priority] int
)
insert into @replace
(OriginalValue, NewValue, [priority])
values (N'rbc inv', N'RBC dominion securities', 2),
(N'rbc dom', N'RBC dominion securities', 2),
(N'RBC', N'RBC Bank', 3)
update @data
set Column1 = coalesce((
select top 1
NewValue
from @replace
where Column1 like '%' + OriginalValue + '%'
order by [priority]
), Column1)
select *
from @data
A tabela "dados" seria aquela onde você faz a substituição.
Pode haver alguns efeitos colaterais usando isso (por exemplo, curingas como % em "search_column", talvez várias correspondências - agora um "aleatório" é obtido, o desempenho pode não ser o melhor, ...) uma resposta mais precisa eu precisaria de uma pergunta melhor.
Editar:
Graças a Ralph... Eu adicionei uma prioridade à tabela "substituir" para poder lidar com correspondências duplicadas.
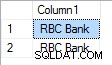
Caso "RBC" tenha prioridade 3, o resultado é:
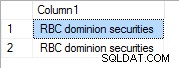
Com prioridade 1 é: