Concordo completamente com @PaulStock que os agregados são melhor deixados para os sistemas de origem. Um agregado no SSIS é um componente de bloqueio total, muito parecido com uma classificação e eu já fiz meu argumento sobre esse ponto .
Mas há momentos em que essas operações no sistema de origem simplesmente não funcionam. O melhor que consegui fazer é basicamente processar os dados duas vezes. Sim, mas nunca consegui encontrar uma maneira de passar uma coluna sem ser afetada. Para cenários Min/Max, eu gostaria disso como uma opção, mas obviamente algo como um Sum tornaria difícil para o componente saber a qual linha de "fonte" ele se vincularia.
2005
Uma implementação de 2005 ficaria assim. Seu desempenho não será bom, na verdade, algumas ordens de magnitude do bom, pois você terá todas essas transformações de bloqueio, além de ter que reprocessar seus dados de origem.
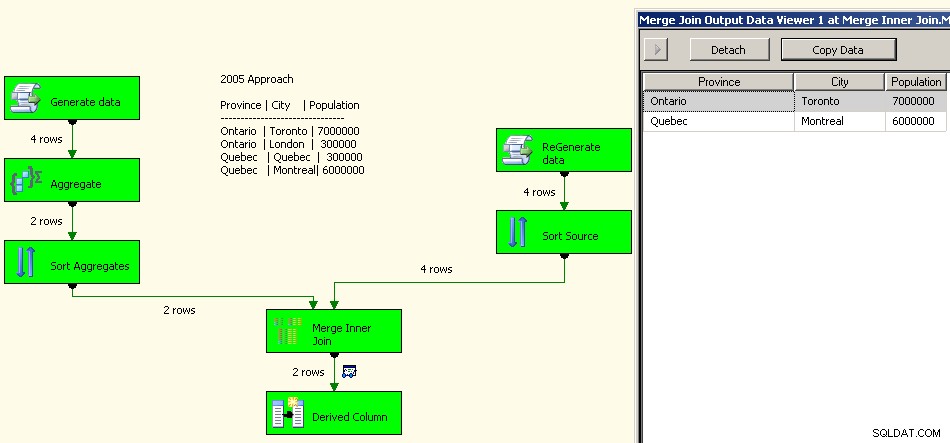
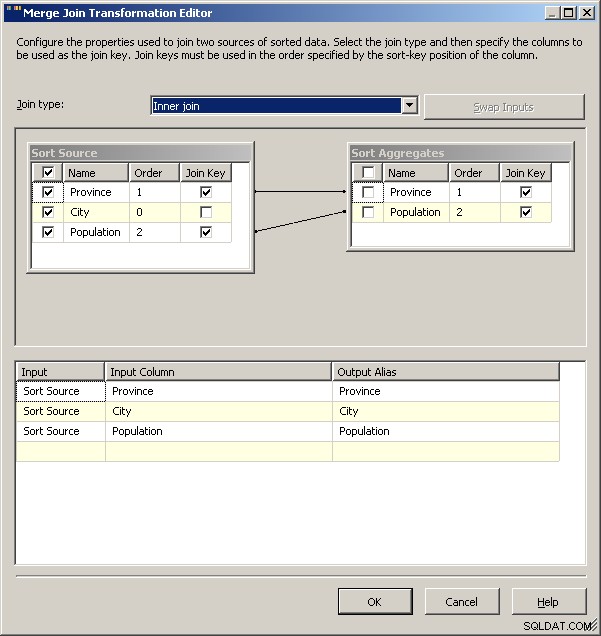
Mesclar associação
2008
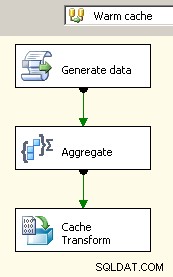
Em 2008, você tem a opção de usar o Gerenciador de conexões de cache o que ajudaria a eliminar as transformações de bloqueio, pelo menos onde for importante, mas você ainda terá que pagar o custo de duplicar o processamento de seus dados de origem.
Arraste dois fluxos de dados para a tela. O primeiro preencherá o gerenciador de conexões de cache e deve ser onde a agregação ocorre.
Agora que o cache tem os dados agregados, solte uma tarefa de pesquisa em seu fluxo de dados principal e execute uma pesquisa no cache.
Aba de pesquisa geral
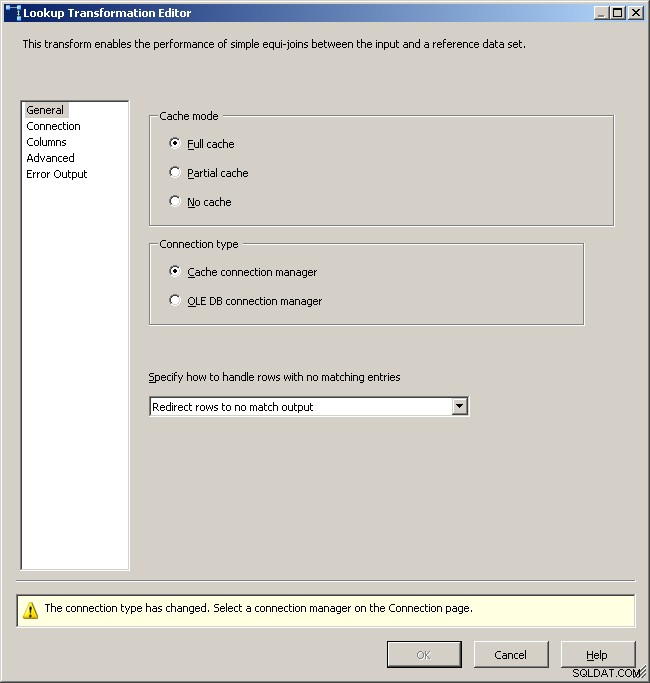
Selecione o gerenciador de conexões de cache
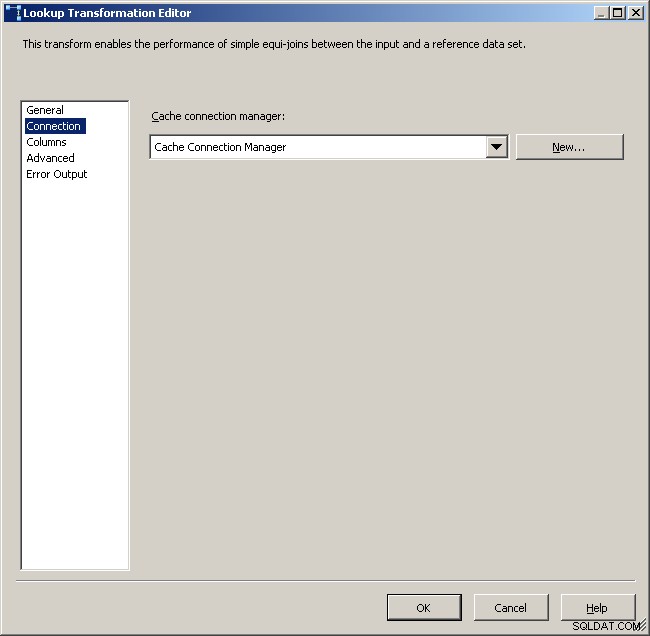
Mapeie as colunas apropriadas
Grande sucesso
Tarefa de script
A terceira abordagem que consigo pensar, 2005 ou 2008, é escrever você mesmo. Como regra geral, tento evitar as tarefas de script, mas este é um caso em que provavelmente faz sentido. Você precisará torná-lo um transformação de script assíncrona mas simplesmente manipule suas agregações lá. Mais código para manter, mas você pode evitar o trabalho de reprocessar seus dados de origem.
Finalmente, como uma advertência geral, eu investigaria o que o impacto dos laços fará com sua solução. Para este conjunto de dados, eu esperaria que algo como Guelph de repente aumentasse e amarrasse Toronto, mas se isso acontecesse, o que o pacote deveria fazer? No momento, ambos resultarão em 2 linhas para Ontário, mas esse é o comportamento pretendido? O script, é claro, permite definir o que acontece no caso de empates. Você provavelmente poderia colocar a solução de 2008 de cabeça para baixo armazenando em cache os dados "normais" e usando isso como sua condição de pesquisa e usando os agregados para recuperar apenas um dos laços. 2005 provavelmente pode fazer o mesmo apenas colocando o agregado como a fonte esquerda para a junção de mesclagem
Edições
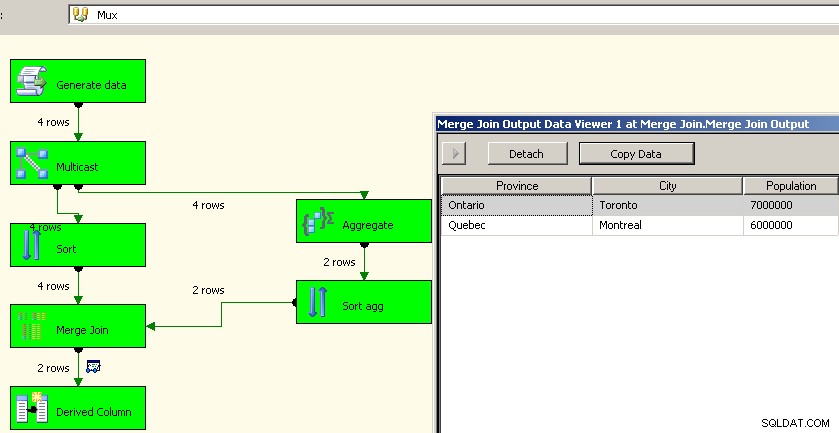
Jason Horner teve uma boa ideia em seu comentário. Uma abordagem diferente seria usar uma transformação multicast e realizar a agregação em um fluxo e reuni-lo novamente. Eu não consegui descobrir como fazê-lo funcionar com uma união all, mas poderíamos usar sorts e mesclar joins como no exemplo acima. Esta é provavelmente uma abordagem melhor, pois nos poupa o trabalho de reprocessar os dados de origem.