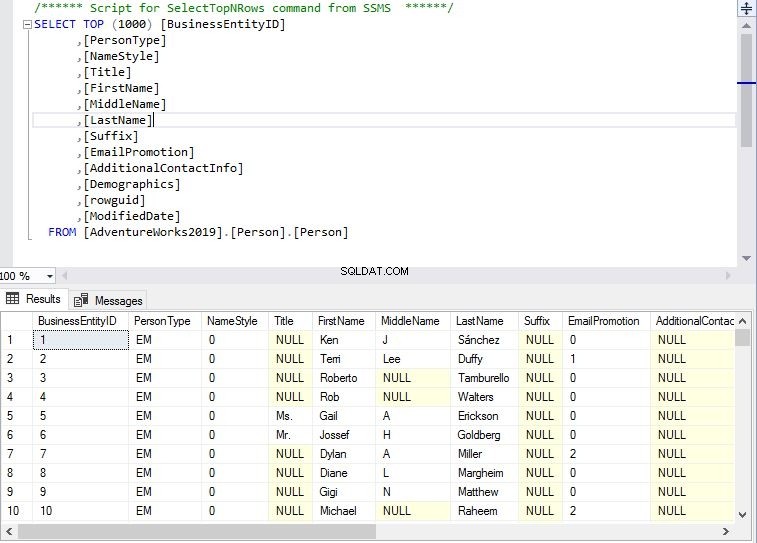
Só quero deixar um aviso:por favor, com muito cuidado escolha seu índice clusterizado! Toda tabela de dados "regular" deve ter um índice clusterizado, pois ter um índice clusterizado realmente acelera muitas operações - sim, acelera , até mesmo insere e exclui! Mas somente se você escolher um bom índice agrupado.
É o mais replicado estrutura de dados em seu banco de dados SQL Server. A chave de clustering também fará parte de cada índice não clusterizado em sua tabela.
Você deve ter muito cuidado ao escolher uma chave de cluster - deve ser:
-
restringir (4 bytes ideais)
-
único (afinal, é o "ponteiro de linha". Se você não o tornar único, o SQL Server fará isso para você em segundo plano, custando alguns bytes para cada entrada vezes o número de linhas e o número de índices não clusterizados que você tem - isso pode ser muito caro!)
-
estático (nunca mude - se possível)
-
idealmente sempre crescente para que você não acabe com uma fragmentação de índice horrível (um GUID é o oposto total de uma boa chave de cluster - por esse motivo específico)
-
deve ser não anulável e idealmente também com largura fixa - umvarchar(250)faz uma chave de cluster muito ruim
Qualquer outra coisa deve realmente ser o segundo e o terceiro nível de importância por trás desses pontos ....
Veja alguns dos trabalhos de Kimberly Tripp (A Rainha da Indexação ) sobre o assunto - qualquer coisa que ela tenha escrito em seu blog é absolutamente inestimável - leia-o, digira-o - viva por ele!
- GUIDs como PRIMARY KEYs e/ou a chave de cluster
- O debate sobre índices agrupados continua...
- Chave de clusterização cada vez maior - o Debate sobre Índices Agrupados... de novo!
- O espaço em disco é barato - isso é não o ponto!