Presumo que o motivo seja que eles simplesmente não consideraram esse recurso prioritário que vale a pena implementar. Parece que Postgres faz suporta ambos
UNION e UNION ALL . Se você tem um forte argumento para esse recurso, pode fornecer comentários em Connect (ou qualquer que seja a URL de sua substituição).
Impedir a adição de duplicatas pode ser útil, pois uma linha duplicada adicionada em uma etapa posterior a uma anterior quase sempre acaba causando um loop infinito ou excedendo o limite máximo de recursão.
Existem alguns lugares nos Padrões SQL onde o código é usado demonstrando
UNION como abaixo 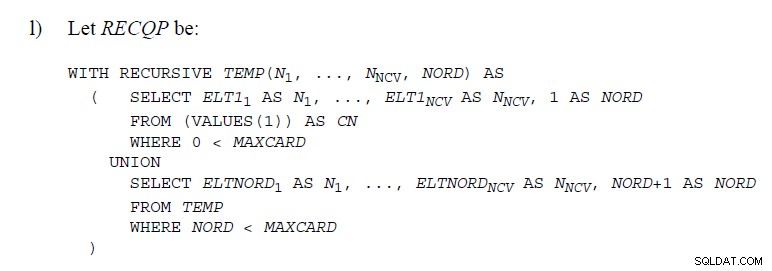
Este artigo explica como eles são implementados no SQL Server . Eles não estão fazendo nada assim "sob o capô". O spool de pilha exclui as linhas à medida que avança para que não seja possível saber se uma linha posterior é uma duplicata de uma excluída. Suportando
UNION precisaria de uma abordagem um pouco diferente. Enquanto isso, você pode facilmente conseguir o mesmo em um TVF multi-instrução.
Para dar um exemplo bobo abaixo (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Alterando o
UNION para UNION ALL e adicionando um DISTINCT no final não vai te salvar da recursão infinita. Mas você pode implementar isso como
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
O acima usa
IGNORE_DUP_KEY para descartar duplicatas. Se a lista de colunas for muito grande para ser indexada, você precisará de DISTINCT e NOT EXISTS em vez de. Você provavelmente também desejaria um parâmetro para definir o número máximo de recursões e evitar loops infinitos. 


