Oi,
O uso do Index no banco de dados do SQL Server ocorre em ambientes que exigem maior desempenho, velocidade e economia de memória.
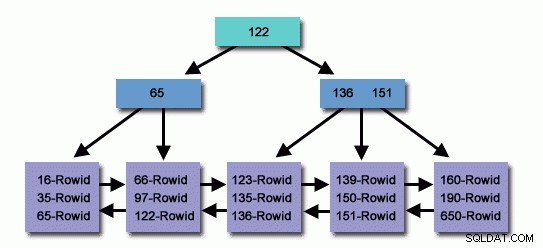
Em uma tabela com milhões ou bilhões de registros, podemos usar um índice para ler menos registros e pesquisar menos para encontrar registros relacionados.
Índice criado com precisão, milhões de registros dentro do banco de dados que pesquisamos em um tempo muito curto para trazer o registro da conveniência do chamador, enquanto ao mesmo tempo ler menos o registro, atingindo o registro de destino, usamos os recursos do sistema operacional de forma eficaz.
Você deve criar índice principalmente para consultas somente leitura em uma tabela. Se as operações de exclusão e atualização forem mais do que consultas somente leitura, você não deve criar o índice dessa tabela.
Você pode examinar a recomendação de índice ausente do SQL Server com o script a seguir. Você pode criar um índice ausente, mas você deve monitorar esses índices. Se eles não forem úteis, você deve eliminá-los.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;