O Galera Cluster vem com muitos recursos notáveis que não estão disponíveis na replicação padrão do MySQL (ou Replicação de Grupo); provisionamento automático de nós, verdadeiro multimestre com resolução de conflitos e failover automático. Há também uma série de limitações que podem afetar o desempenho do cluster. Felizmente, se você não estiver ciente disso, existem soluções alternativas. E se você fizer isso corretamente, poderá minimizar o impacto dessas limitações e melhorar o desempenho geral.
Anteriormente, abordamos muitas dicas e truques relacionados ao Galera Cluster, incluindo a execução do Galera na Nuvem AWS. Este post do blog mergulha distintamente nos aspectos de desempenho, com exemplos de como tirar o máximo proveito do Galera.
Carga útil de replicação
Um pouco de introdução - Galera replica os conjuntos de gravação durante o estágio de confirmação, transferindo conjuntos de gravação do nó originador para os nós receptores de forma síncrona através do plug-in de replicação wsrep. Este plug-in também certificará conjuntos de gravação nos nós receptores. Se o processo de certificação for aprovado, ele retornará OK para o cliente no nó originador e será aplicado nos nós receptores posteriormente de forma assíncrona. Caso contrário, a transação será revertida no nó originador (retornando o erro para o cliente) e os writesets que foram transferidos para os nós receptores serão descartados.
Um writeset consiste em operações de gravação dentro de uma transação que altera o estado do banco de dados. No Galera Cluster, autocommit é padrão para 1 (ativado). Literalmente, qualquer instrução SQL executada no Galera Cluster será incluída como uma transação, a menos que você comece explicitamente com BEGIN, START TRANSACTION ou SET autocommit=0. O diagrama a seguir ilustra o encapsulamento de uma única instrução DML em um conjunto de gravação:
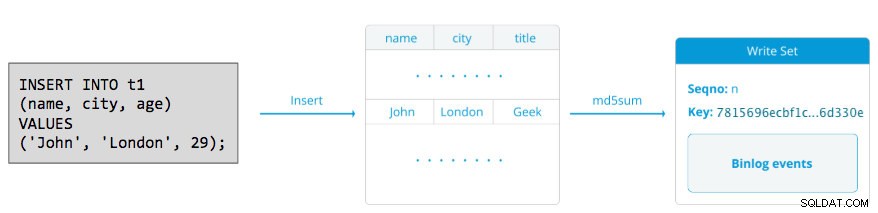
Para DML (INSERT, UPDATE, DELETE..), a carga útil do conjunto de gravação consiste nos eventos de log binários para uma transação específica, enquanto para DDLs (ALTER, GRANT, CREATE..), a carga útil do conjunto de gravação é a própria instrução DDL. Para DMLs, o conjunto de gravação terá que ser certificado contra conflitos no nó receptor enquanto para DDLs (dependendo do wsrep_osu_method , padrão para TOI), o cluster de cluster executa a instrução DDL em todos os nós na mesma sequência de ordem total, bloqueando a confirmação de outras transações enquanto o DDL está em andamento (consulte também RSU). Em palavras simples, o Galera Cluster lida com a replicação DDL e DML de maneira diferente.
Tempo de ida e volta
Geralmente, os seguintes fatores determinam a rapidez com que o Galera pode replicar um conjunto de gravação de um nó originador para todos os nós receptores:
- Tempo de ida e volta (RTT) até o nó mais distante no cluster do nó originador.
- O tamanho de um conjunto de gravações a ser transferido e certificado para conflito no nó receptor.
Por exemplo, se tivermos um Galera Cluster de três nós e um dos nós estiver localizado a 10 milissegundos (0,01 segundo), é muito improvável que você consiga gravar mais de 100 vezes por segundo na mesma linha sem entrar em conflito. Há uma citação popular de Mark Callaghan que descreve muito bem esse comportamento:
"[Em um cluster Galera] uma determinada linha não pode ser modificada mais de uma vez por RTT"
Para medir o valor de RTT, basta executar ping no nó originador para o nó mais distante no cluster:
$ ping 192.168.55.173 # the farthest nodeAguarde alguns segundos (ou minutos) e encerre o comando. A última linha da seção de estatística de ping é o que estamos procurando:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msO máximo valor é de 1,340 ms (0,00134s) e devemos considerar esse valor ao estimar o mínimo transações por segundo (tps) para este cluster. A média valor é 0,431ms (0,000431s) e podemos usar para estimar a média tps enquanto min valor é 0,111ms (0,000111s) que podemos usar para estimar o máximo tps. O mdev significa como as amostras RTT foram distribuídas a partir da média. Valor mais baixo significa RTT mais estável.
Assim, as transações por segundo podem ser estimadas dividindo o RTT (em segundo) em 1 segundo:

Resultante,
- Tps mínimo:1 / 0,00134 (RTT máx.) =746,26 ~ 746 tps
- Tps médios:1 / 0,000431 (RTT médio) =2320,19 ~ 2320 tps
- Máximo de tps:1/0,000111 (min RTT) =9009,01 ~ 9009 tps
Observe que esta é apenas uma estimativa para antecipar o desempenho da replicação. Não há muito que possamos fazer para melhorar isso no lado do banco de dados, uma vez que tenhamos tudo implantado e funcionando. Exceto, se você mover ou migrar os servidores de banco de dados mais próximos uns dos outros para melhorar o RTT entre nós ou atualizar os periféricos ou a infraestrutura de rede. Isso exigiria uma janela de manutenção e um planejamento adequado.
Agrupe grandes transações
Outro fator é o tamanho da transação. Após a transferência do conjunto de escritas, haverá um processo de certificação. A certificação é um processo para determinar se o nó pode ou não aplicar o conjunto de gravação. Galera gera pseudochaves de soma de verificação MD5 de cada linha completa. O custo da certificação depende do tamanho do conjunto de gravações, que se traduz em várias pesquisas de chave exclusivas no índice de certificação (uma tabela de hash). Se você atualizar 500.000 linhas em uma única transação, por exemplo:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;O acima irá gerar um único conjunto de escrita com 500.000 eventos de log binários nele. Este enorme conjunto de escrita não excede wsrep_max_ws_size (padrão para 2 GB) para que seja transferido pelo plugin de replicação Galera para todos os nós do cluster, certificando essas 500.000 linhas nos nós receptores para quaisquer transações conflitantes que ainda estejam na fila escrava. Por fim, o status de certificação é retornado ao plug-in de replicação de grupo. Quanto maior o tamanho da transação, maior o risco de entrar em conflito com outras transações que vêm de outro mestre. Transações conflitantes desperdiçam recursos do servidor, além de causar uma enorme reversão para o nó originador. Observe que uma operação de reversão no MySQL é muito mais lenta e menos otimizada do que a operação de confirmação.
A instrução SQL acima pode ser reescrita em uma instrução mais amigável ao Galera com a ajuda de um loop simples, como o exemplo abaixo:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneO comando shell acima atualizaria 1.000 linhas por transação 500 vezes e aguardaria 2 segundos entre as execuções. Você também pode usar um procedimento armazenado ou outros meios para obter um resultado semelhante. Se reescrever a consulta SQL não for uma opção, simplesmente instrua o aplicativo a executar a grande transação durante uma janela de manutenção para reduzir o risco de conflitos.
Para grandes exclusões, considere usar o pt-archiver do Percona Toolkit - um trabalho de baixo impacto e somente encaminhamento para eliminar dados antigos da tabela sem afetar muito as consultas OLTP.
Encadeamentos Escravos Paralelos
No Galera, o aplicador é um processo multithread. Applier é um thread executado no Galera para aplicar os conjuntos de gravação de entrada de outro nó. O que significa que é possível que todos os receptores executem várias operações DML que vêm diretamente do nó originador (mestre) simultaneamente. A replicação paralela Galera só é aplicada a transações quando for seguro fazê-lo. Melhora a probabilidade do nó sincronizar com o nó originador. No entanto, a velocidade de replicação ainda está limitada ao RTT e ao tamanho do conjunto de gravações.
Para tirar o melhor proveito disso, precisamos saber duas coisas:
- O número de núcleos que o servidor possui.
- O valor de wsrep_cert_deps_distance estado.
O status wsrep_cert_deps_distance nos diz o grau potencial de paralelização. É o valor da distância média entre os valores de sequência mais altos e mais baixos que podem ser aplicados em paralelo. Você pode usar a wsrep_cert_deps_distance variável de status para determinar o número máximo de encadeamentos escravos possível. Observe que este é um valor médio ao longo do tempo. Portanto, para obter um bom valor, você precisa atingir o cluster com operações de gravação por meio de carga de trabalho de teste ou benchmark até ver um valor estável saindo.
Para obter o número de núcleos, você pode simplesmente usar o seguinte comando:
$ grep -c processor /proc/cpuinfo
4Idealmente, 2, 3 ou 4 threads de aplicador escravo por núcleo de CPU é um bom começo. Assim, o valor mínimo para os encadeamentos escravos deve ser 4 x número de núcleos de CPU e não deve exceder a wsrep_cert_deps_distance valor:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Você pode controlar o número de threads do aplicador escravo usando wsrep_slave_thread variável. Mesmo sendo uma variável dinâmica, apenas aumentar o número teria um efeito imediato. Se você reduzir o valor dinamicamente, levará algum tempo até que o thread do aplicador seja encerrado após a conclusão da aplicação. Um valor recomendado está entre 16 e 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Observe que para que os threads escravos paralelos funcionem, o seguinte deve ser definido (o que geralmente é pré-configurado para o Galera Cluster):
innodb_autoinc_lock_mode=2Galera Cache (gcache)
Galera usa um arquivo pré-alocado com um tamanho específico chamado gcache, onde um nó Galera mantém uma cópia de writesets no estilo de buffer circular. Por padrão, seu tamanho é de 128 MB, o que é bastante pequeno. Incremental State Transfer (IST) é um método para preparar um joiner enviando apenas os writesets ausentes disponíveis no gcache do doador. O IST é mais rápido que a transferência de instantâneo de estado (SST), não bloqueia e não tem impacto significativo no desempenho do doador. Deve ser a opção preferida sempre que possível.
O IST só pode ser alcançado se todas as alterações perdidas pelo joiner ainda estiverem no arquivo gcache do doador. A configuração recomendada para isso é ser tão grande quanto todo o conjunto de dados MySQL. Se o espaço em disco for limitado ou caro, determinar o tamanho correto do tamanho do gcache é crucial, pois pode influenciar o desempenho da sincronização de dados entre os nós do Galera.
A declaração abaixo nos dará uma ideia da quantidade de dados replicados pelo Galera. Execute a seguinte instrução em um dos nós Galera durante o horário de pico (testado em MariaDB>10.0 e PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+Podemos estimar que o nó Galera pode ter aproximadamente 16 minutos de inatividade, sem exigir que o SST se junte (a menos que o Galera não possa determinar o estado do joiner). Se o tempo for muito curto e você tiver espaço em disco suficiente em seus nós, poderá alterar o wsrep_provider_options="gcache.size=
Também é recomendado usar gcache.recover=yes em wsrep_provider_options (Galera>3.19), onde o Galera tentará recuperar o arquivo gcache para um estado utilizável na inicialização em vez de excluí-lo, preservando assim a capacidade de ter IST e evitando SST o máximo possível. Codership e Percona abordaram isso em detalhes em seus blogs. IST é sempre o melhor método para sincronizar depois que um nó se junta novamente ao cluster. É 50% mais rápido que xtrabackup ou mariabackup e 5x mais rápido que mysqldump.
Escravo assíncrono
Os nós Galera são fortemente acoplados, onde o desempenho da replicação é tão rápido quanto o nó mais lento. Galera usa um mecanismo de controle de fluxo, para controlar o fluxo de replicação entre os membros e eliminar qualquer atraso escravo. A replicação pode ser toda rápida ou toda lenta em cada nó e é ajustada automaticamente pelo Galera. Se você quiser saber sobre controle de fluxo, leia esta postagem no blog de Jay Janssen da Percona.
Na maioria dos casos, operações pesadas, como análises de longa duração (leitura intensa) e backups (leitura intensa, bloqueio) geralmente são inevitáveis, o que pode prejudicar o desempenho do cluster. A melhor maneira de executar esse tipo de consulta é enviá-las para um servidor de réplica fracamente acoplado, por exemplo, um escravo assíncrono.
Um escravo assíncrono replica de um nó Galera usando o protocolo de replicação assíncrona padrão do MySQL. Não há limite no número de escravos que podem ser conectados a um nó Galera, e também é possível encadeá-lo com um mestre intermediário. As operações do MySQL executadas neste servidor não afetarão o desempenho do cluster, exceto a fase inicial de sincronização onde um backup completo deve ser feito no nó Galera para preparar o escravo antes de estabelecer o link de replicação (embora o ClusterControl permita que você construa o nó assíncrono escravo de um backup existente primeiro, antes de conectá-lo ao cluster).
GTID (Global Transaction Identifier) fornece um melhor mapeamento de transações entre nós e é compatível com MySQL 5.6 e MariaDB 10.0. Com o GTID, a operação de failover de um escravo para outro mestre (outro nó Galera) é simplificada, sem a necessidade de descobrir o arquivo de log e a posição exata. O Galera também vem com sua própria implementação GTID, mas esses dois são independentes um do outro.
O dimensionamento de um escravo assíncrono está a um clique de distância se você estiver usando o recurso ClusterControl -> Adicionar escravo de replicação:
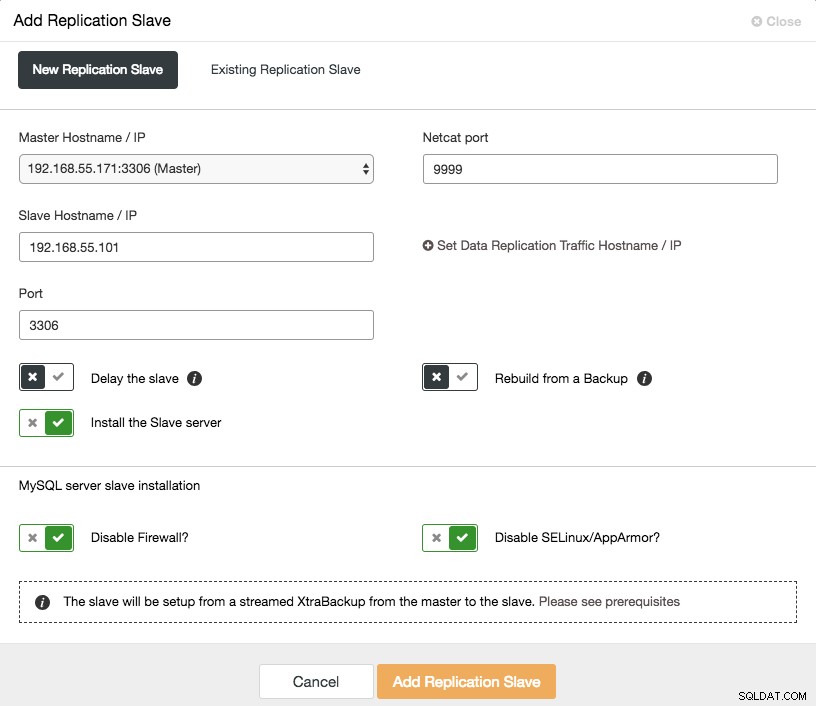
Observe que os logs binários devem ser habilitados no mestre (o nó Galera escolhido) antes que possamos prosseguir com esta configuração. Também abordamos a maneira manual neste post anterior.
A captura de tela a seguir do ClusterControl mostra a topologia do cluster, ilustra nossa arquitetura Galera Cluster com um escravo assíncrono:
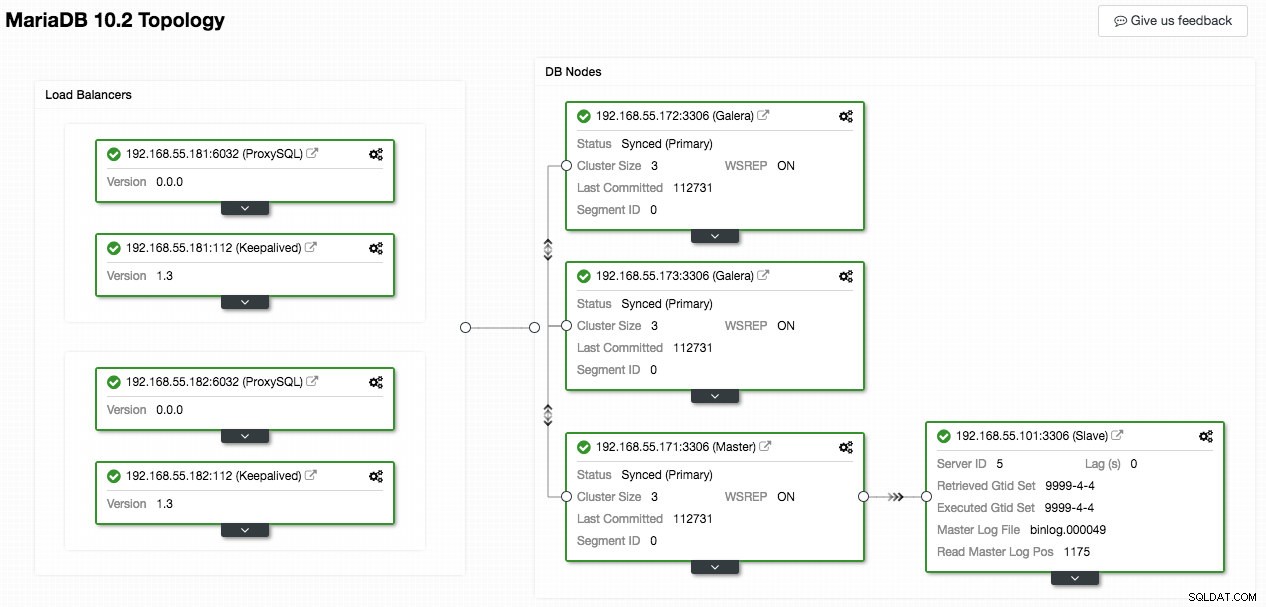
O ClusterControl descobre automaticamente a topologia e gera o diagrama super legal como acima. Você também pode executar tarefas de administração diretamente desta página clicando no ícone de engrenagem no canto superior direito de cada caixa.
Proxy reverso com reconhecimento de SQL
ProxySQL e MariaDB MaxScale são proxies reversos inteligentes que entendem o protocolo MySQL e são capazes de atuar como gateway, roteador, balanceador de carga e firewall na frente de seus nós Galera. Com a ajuda de um provedor de endereço IP virtual como LVS ou Keepalived, e combinando isso com a tecnologia de replicação multimestre Galera, podemos ter um serviço de banco de dados altamente disponível, eliminando todos os possíveis pontos de falha (SPOF) do ponto de aplicação -de-vista. Isso certamente melhorará a disponibilidade e confiabilidade da arquitetura como um todo.
Outra vantagem dessa abordagem é que você poderá monitorar, reescrever ou redirecionar as consultas SQL recebidas com base em um conjunto de regras antes que elas atinjam o servidor de banco de dados real, minimizando as alterações no aplicativo ou no lado do cliente e roteando as consultas para um nó mais adequado para um desempenho ideal. Consultas arriscadas para Galera como LOCK TABLES e FLUSH TABLES WITH READ LOCK podem ser evitadas antes que causem estragos no sistema, enquanto consultas impactantes como consultas "hotspot" (uma linha que diferentes consultas desejam acessar ao mesmo tempo) podem ser reescrito ou redirecionado para um único nó Galera para reduzir o risco de conflitos de transação. Para consultas pesadas somente leitura, como OLAP ou backup, você pode roteá-las para um escravo assíncrono, se houver.
O proxy reverso também monitora o estado do banco de dados, consultas e variáveis para entender as alterações de topologia e produzir uma decisão de roteamento precisa para os servidores de back-end. Indiretamente, ele centraliza o monitoramento dos nós e a visão geral do cluster sem a necessidade de verificar cada nó Galera regularmente. A captura de tela a seguir mostra o painel de monitoramento do ProxySQL no ClusterControl:
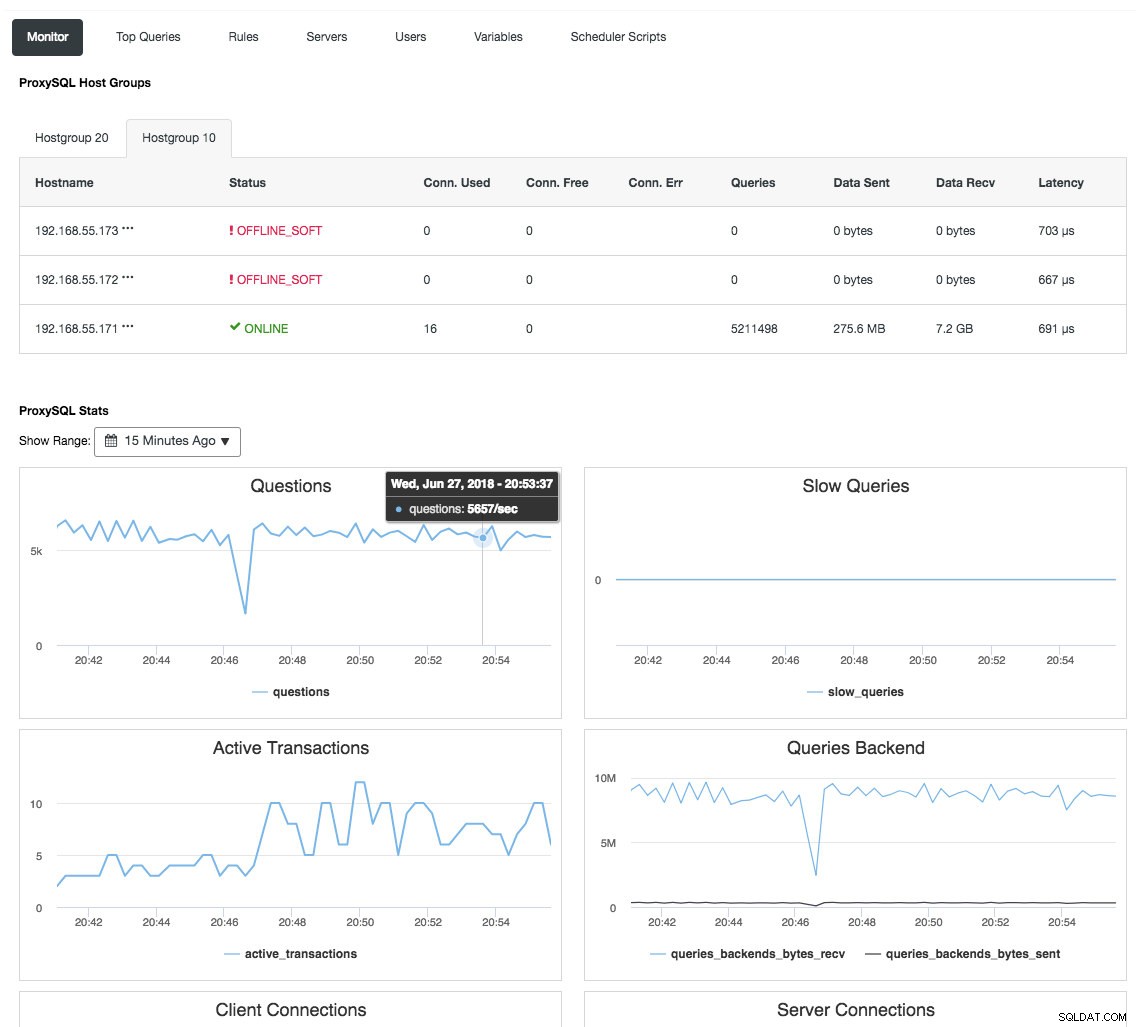
Há também muitos outros benefícios que um balanceador de carga pode trazer para melhorar significativamente o Galera Cluster, conforme abordado em detalhes nesta postagem do blog, Torne-se um DBA ClusterControl:Tornando seus componentes de banco de dados HA via Load Balancers.
Considerações finais
Com um bom entendimento de como o Galera Cluster funciona internamente, podemos contornar algumas das limitações e melhorar o serviço de banco de dados. Boa aglomeração!