Resumo
- O desempenho do método de subconsultas depende da distribuição dos dados.
- O desempenho da agregação condicional não depende da distribuição de dados.
O método de subconsultas pode ser mais rápido ou mais lento que a agregação condicional, depende da distribuição dos dados.
Naturalmente, se a tabela tiver um índice adequado, as subconsultas provavelmente se beneficiarão dele, porque o índice permitiria a varredura apenas da parte relevante da tabela em vez da varredura completa. É improvável que ter um índice adequado beneficie significativamente o método de agregação condicional, porque ele verificará o índice completo de qualquer maneira. O único benefício seria se o índice fosse mais estreito do que a tabela e o mecanismo tivesse que ler menos páginas na memória.
Sabendo disso, você pode decidir qual método escolher.
Primeiro teste
Fiz uma tabela de teste maior, com 5M de linhas. Não havia índices na tabela. Eu medi as estatísticas de E/S e CPU usando o SQL Sentry Plan Explorer. Usei o SQL Server 2014 SP1-CU7 (12.0.4459.0) Express de 64 bits para esses testes.
De fato, suas consultas originais se comportaram como você descreveu, ou seja, as subconsultas foram mais rápidas, embora as leituras fossem 3 vezes maiores.
Depois de algumas tentativas em uma tabela sem um índice, reescrevi sua agregação condicional e adicionei variáveis para manter o valor de
DATEADD expressões. O tempo total tornou-se significativamente mais rápido.
Então eu substituí
SUM com COUNT e tornou-se um pouco mais rápido novamente. Afinal, a agregação condicional tornou-se praticamente tão rápida quanto as subconsultas.
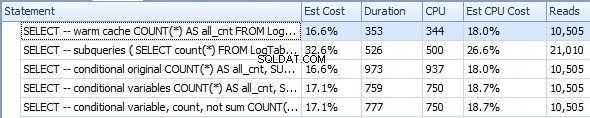
Aqueça o cache (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subconsultas (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Agregação condicional original (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregação condicional com variáveis (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregação condicional com variáveis e COUNT em vez de SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Com base nesses resultados, meu palpite é que
CASE invocado DATEADD para cada linha, enquanto WHERE foi inteligente o suficiente para calculá-lo uma vez. Mais COUNT é um pouco mais eficiente que SUM . No final, a agregação condicional é apenas um pouco mais lenta que as subconsultas (1062 vs 1031), talvez porque
WHERE é um pouco mais eficiente que CASE em si, e além disso, WHERE filtra algumas linhas, então COUNT tem que processar menos linhas. Na prática eu usaria agregação condicional, porque acho que esse número de leituras é mais importante. Se sua tabela for pequena para caber e permanecer no buffer pool, qualquer consulta será rápida para o usuário final. Mas, se a tabela for maior que a memória disponível, espero que a leitura do disco diminua significativamente as subconsultas.
Segundo teste
Por outro lado, filtrar as linhas o mais cedo possível também é importante.
Aqui está uma pequena variação do teste, que demonstra isso. Aqui, defino o limite como GETDATE() + 100 anos, para garantir que nenhuma linha satisfaça os critérios do filtro.
Aqueça o cache (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subconsultas (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Agregação condicional original (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregação condicional com variáveis (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregação condicional com variáveis e COUNT em vez de SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
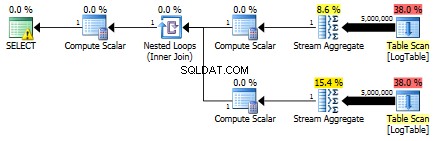
Abaixo está um plano com subconsultas. Você pode ver que 0 linhas foram para o Stream Aggregate na segunda subconsulta, todas elas foram filtradas na etapa Table Scan.
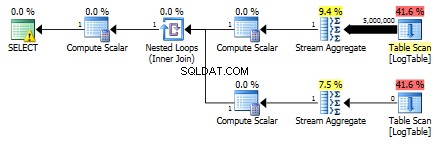
Como resultado, as subconsultas são novamente mais rápidas.
Terceiro teste
Aqui alterei os critérios de filtragem do teste anterior:all
> foram substituídos por < . Como resultado, o condicional COUNT contou todas as linhas em vez de nenhuma. Surpresa surpresa! A consulta de agregação condicional levou os mesmos 750 ms, enquanto as subconsultas se tornaram 813 em vez de 500. 
Aqui está o plano para subconsultas:
Você poderia me dar um exemplo, onde a agregação condicional supera notavelmente a solução de subconsulta?
Aqui está. O desempenho do método de subconsultas depende da distribuição dos dados. O desempenho da agregação condicional não depende da distribuição de dados.
O método de subconsultas pode ser mais rápido ou mais lento que a agregação condicional, depende da distribuição dos dados.
Sabendo disso, você pode decidir qual método escolher.
Detalhes do bônus
Se você passar o mouse sobre o
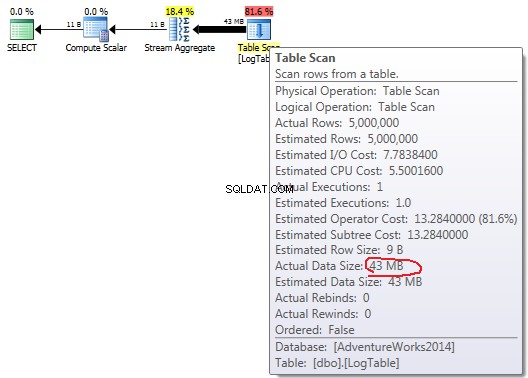
Table Scan operador você pode ver o Actual Data Size em diferentes variantes. - Simples
COUNT(*):
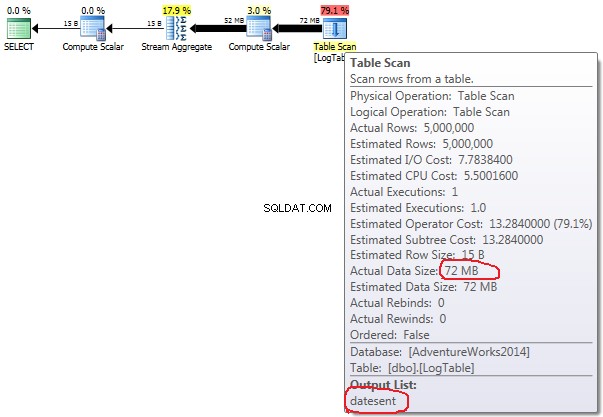
- Agregação condicional:
- Subconsulta no teste 2:
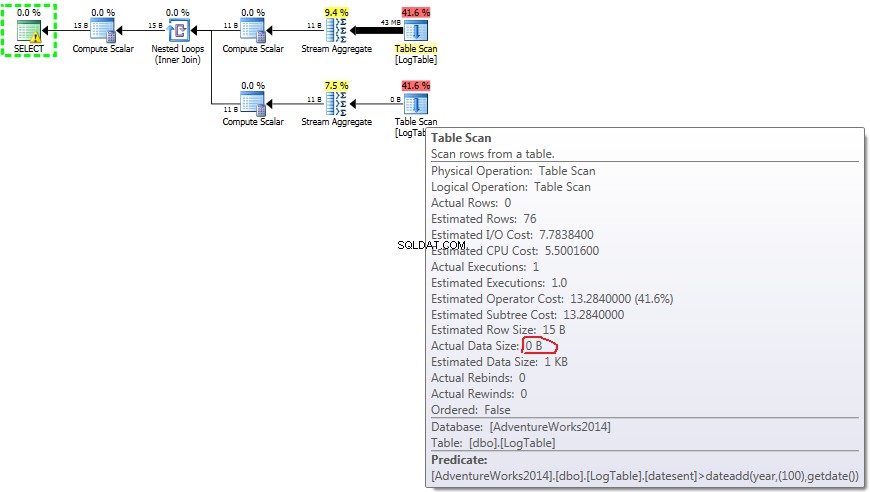
- Subconsulta no teste 3:
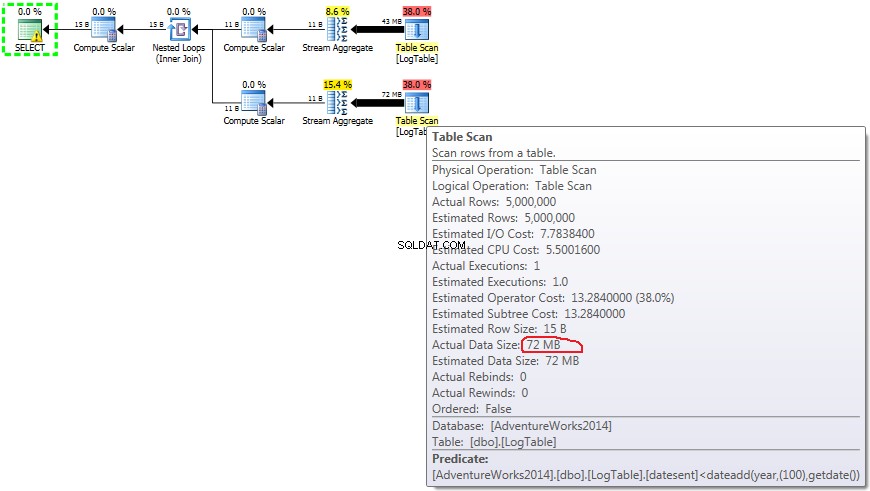
Agora fica claro que a diferença no desempenho provavelmente é causada pela diferença na quantidade de dados que flui pelo plano.
No caso de
COUNT(*) simples não há Output list (nenhum valor de coluna é necessário) e o tamanho dos dados é menor (43 MB). No caso de agregação condicional este valor não muda entre os testes 2 e 3, é sempre 72MB.
Output list tem uma coluna datesent . No caso de subconsultas, esse valor não mudam de acordo com a distribuição dos dados.