Concordo com Cade Roux.
Este artigo deve colocá-lo no caminho certo:
- Índices no SQL Server 2005/2008 – Práticas recomendadas, parte 1
- Índices no SQL Server 2005/2008 – Parte 2 – Internos
Uma coisa a notar, índices clusterizados devem ter uma chave única (uma coluna de identidade que eu recomendaria) como a primeira coluna.
Em segundo lugar, se você estiver criando outros índices em seus dados e eles forem construídos de forma inteligente, eles serão reutilizados.
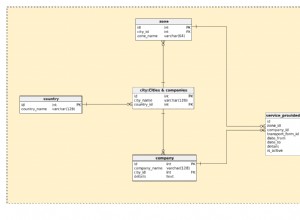
por exemplo. imagine que você pesquisa uma tabela em três colunas
estado, município, CEP.
- às vezes você pesquisa apenas por estado.
- às vezes você pesquisa por estado e município.
- você pesquisa com frequência por estado, município, CEP.
Em seguida, um índice com estado, município, CEP. será usado em todas essas três pesquisas.
Se você pesquisar bastante apenas por zip, o índice acima não será usado (pelo SQL Server de qualquer maneira), pois o zip é a terceira parte desse índice e o otimizador de consulta não verá esse índice como útil.
Você poderia então criar um índice somente no Zip que seria usado nesta instância.
A propósito, podemos tirar proveito do fato de que com a indexação de várias colunas a primeira coluna de índice é sempre utilizável para pesquisa e quando você pesquisa apenas por 'estado' é eficiente, mas não tão eficiente quanto o índice de coluna única em 'estado '
Acho que a resposta que você está procurando é que depende das cláusulas where de suas consultas usadas com frequência e também do seu group by.
O artigo vai ajudar muito. :-)