Você usa subconsultas SQL ou evita usá-las?
Digamos que o diretor de crédito e cobranças peça para você listar os nomes das pessoas, seus saldos não pagos por mês e o saldo atual e quer que você importe essa matriz de dados para o Excel. O objetivo é analisar os dados e apresentar uma oferta que torne os pagamentos mais leves para mitigar os efeitos da pandemia do COVID19.
Você opta por usar uma consulta e uma subconsulta aninhada ou uma junção? Que decisão você vai tomar?
Subconsultas SQL – O que são?
Antes de nos aprofundarmos na sintaxe, no impacto no desempenho e nas advertências, por que não definir uma subconsulta primeiro?
Em termos mais simples, uma subconsulta é uma consulta dentro de uma consulta. Enquanto uma consulta que incorpora uma subconsulta é a consulta externa, nos referimos a uma subconsulta como a consulta interna ou seleção interna. E os parênteses incluem uma subconsulta semelhante à estrutura abaixo:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)Vamos analisar os seguintes pontos neste post:
- Sintaxe de subconsulta SQL dependendo de diferentes tipos e operadores de subconsulta.
- Quando e em que tipo de declarações se pode usar uma subconsulta.
- Implicações de desempenho x JOINs .
- Avisos comuns ao usar subconsultas SQL.
Como de costume, fornecemos exemplos e ilustrações para melhorar a compreensão. Mas tenha em mente que o foco principal deste post são as subconsultas no SQL Server.
Agora, vamos começar.
Faça subconsultas SQL independentes ou correlacionadas
Por um lado, as subconsultas são categorizadas com base em sua dependência da consulta externa.
Deixe-me descrever o que é uma subconsulta independente.
As subconsultas independentes (ou às vezes chamadas de subconsultas simples ou não correlacionadas) são independentes das tabelas na consulta externa. Deixe-me ilustrar isso:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)Conforme demonstrado no código acima, a subconsulta (entre parênteses abaixo) não tem referências a nenhuma coluna na consulta externa. Além disso, você pode destacar a subconsulta no SQL Server Management Studio e executá-la sem obter nenhum erro de tempo de execução.
O que, por sua vez, leva a uma depuração mais fácil de subconsultas autocontidas.
A próxima coisa a considerar são as subconsultas correlacionadas. Comparado com sua contraparte independente, esta tem pelo menos uma coluna sendo referenciada a partir da consulta externa. Para esclarecer, vou dar um exemplo:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)Você prestou atenção o suficiente para notar a referência a BusinessEntityID da Pessoa tabela? Bom trabalho!
Depois que uma coluna da consulta externa é referenciada na subconsulta, ela se torna uma subconsulta correlacionada. Mais um ponto a ser considerado:se você destacar uma subconsulta e executá-la, ocorrerá um erro.
E sim, você está absolutamente certo:isso torna as subconsultas correlacionadas muito mais difíceis de depurar.
Para possibilitar a depuração, siga estas etapas:
- isolar a subconsulta.
- substitua a referência à consulta externa por um valor constante.
Isolar a subconsulta para depuração fará com que fique assim:
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>Agora, vamos nos aprofundar um pouco mais na saída das subconsultas.
Faça subconsultas SQL com 3 possíveis valores retornados
Bem, primeiro, vamos pensar em quais valores retornados podemos esperar das subconsultas SQL.
Na verdade, existem 3 resultados possíveis:
- Um único valor
- Vários valores
- Tabelas inteiras
Valor único
Vamos começar com a saída de valor único. Esse tipo de subconsulta pode aparecer em qualquer lugar na consulta externa onde uma expressão é esperada, como WHERE cláusula.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)Quando você usa um MAX (), você recupera um único valor. Foi exatamente isso que aconteceu com nossa subconsulta acima. Usando o igual (= ) informa ao SQL Server que você espera um valor único. Outra coisa:se a subconsulta retornar vários valores usando o equals (= ), você recebe um erro, semelhante ao abaixo:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Vários valores
Em seguida, examinamos a saída multivalorada. Esse tipo de subconsulta retorna uma lista de valores com uma única coluna. Além disso, operadores como IN e NÃO EM esperará um ou mais valores.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')Valores da tabela inteira
E por último, mas não menos importante, por que não se aprofundar nas saídas da tabela inteira.
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]Você notou o DE cláusula?
Em vez de usar uma tabela, usou uma subconsulta. Isso é chamado de tabela derivada ou subconsulta de tabela.
E agora, deixe-me apresentar algumas regras básicas ao usar esse tipo de consulta:
- Todas as colunas na subconsulta devem ter nomes exclusivos. Assim como uma tabela física, uma tabela derivada deve ter nomes de coluna exclusivos.
- ORENDER POR não é permitido a menos que TOP também é especificado. Isso porque a tabela derivada representa uma tabela relacional em que as linhas não têm ordem definida.
Nesse caso, uma tabela derivada tem os benefícios de uma tabela física. É por isso que, em nosso exemplo, podemos usar COUNT () em uma das colunas da tabela derivada.
Isso é tudo sobre saídas de subconsulta. Mas antes de prosseguirmos, você deve ter notado que a lógica por trás do exemplo para vários valores e outros também pode ser feita usando um JOIN .
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'Na verdade, a saída será a mesma. Mas qual tem melhor desempenho?
Antes de entrarmos nisso, deixe-me dizer que dediquei uma seção a este tópico quente. Vamos examiná-lo com planos de execução completos e dar uma olhada nas ilustrações.
Então, tenha paciência comigo por um momento. Vamos discutir outra maneira de colocar suas subconsultas.
Outras instruções em que você pode usar subconsultas SQL
Até agora, usamos subconsultas SQL em SELECT declarações. E o fato é que você pode aproveitar os benefícios das subconsultas em INSERIR , ATUALIZAÇÃO e EXCLUIR instruções ou em qualquer instrução T-SQL que forme uma expressão.
Então, vamos dar uma olhada em uma série de mais alguns exemplos.
Usando subconsultas SQL em instruções UPDATE
É bastante simples incluir subconsultas em UPDATE declarações. Por que não verificar este exemplo?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GOVocê viu o que fizemos lá?
O problema é que você pode colocar subconsultas em WHERE cláusula de um UPDATE demonstração.
Como não temos no exemplo, você também pode usar uma subconsulta para o SET cláusula como SET coluna =(subconsulta) . Mas esteja avisado:ele deve gerar um único valor porque, caso contrário, ocorrerá um erro.
O que faremos a seguir?
Usando subconsultas SQL em instruções INSERT
Como você já sabe, você pode inserir registros em uma tabela usando um SELECT demonstração. Tenho certeza que você tem uma ideia de qual será a estrutura da subconsulta, mas vamos demonstrar isso com um exemplo:
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)Então, o que estamos vendo aqui?
- A primeira subconsulta recupera a última taxa salarial de um funcionário antes de adicionar os 10 adicionais.
- A segunda subconsulta obtém o último registro de salário do funcionário.
- Por último, o resultado do SELECT é inserido no EmployeePayHistory tabela.
Em outras instruções T-SQL
Além de SELECT , INSERIR , ATUALIZAÇÃO e EXCLUIR , você também pode usar subconsultas SQL no seguinte:
Declarações de variáveis ou instruções SET em procedimentos armazenados e funções
Deixe-me esclarecer usando este exemplo:
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Alternativamente, você pode fazer isso da seguinte maneira:
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Em Expressões Condicionais
Por que você não dá uma olhada neste exemplo:
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDAlém disso, podemos fazer assim:
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
ENDFaça subconsultas SQL com comparação ou operadores lógicos
Até agora, vimos os iguais (= ) e o operador IN. Mas há muito mais para explorar.
Usando operadores de comparação
Quando um operador de comparação como =, <,>, <>,>=ou <=é usado com uma subconsulta, a subconsulta deve retornar um único valor. Além disso, ocorre um erro se a subconsulta retornar vários valores.
O exemplo abaixo irá gerar um erro de tempo de execução.
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)Você sabe o que está errado no código acima?
Em primeiro lugar, o código usa o operador equals (=) com a subconsulta. Além disso, a subconsulta retorna uma lista de datas de início.
Para corrigir o problema, faça a subconsulta usar uma função como MAX () na coluna de data de início para retornar um único valor.
Usando operadores lógicos
Usando EXISTS ou NOT EXISTS
EXISTE retorna VERDADEIRO se a subconsulta retornar alguma linha. Caso contrário, ele retornará FALSE . Enquanto isso, usando NÃO EXISTE retornará VERDADEIRO se não houver linhas e FALSE , por outro lado.
Considere o exemplo abaixo:
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDPrimeiro, permita-me explicar. O código acima descartará o token de tabela se ele for encontrado em sys.tables , ou seja, se existir no banco de dados. Outro ponto:a referência ao nome da coluna é irrelevante.
Por que é que?
Acontece que o mecanismo de banco de dados só precisa obter pelo menos 1 linha usando EXISTS . Em nosso exemplo, se a subconsulta retornar uma linha, a tabela será descartada. Por outro lado, se a subconsulta não retornar uma única linha, as instruções seguintes não serão executadas.
Assim, a preocupação de EXISTE é apenas linhas e sem colunas.
Além disso, EXISTE usa lógica de dois valores:TRUE ou FALSO . Não há casos em que retornará NULL . A mesma coisa acontece quando você nega EXISTS usando NÃO .
Usando IN ou NOT IN
Uma subconsulta introduzida com IN ou NÃO DENTRO retornará uma lista de zero ou mais valores. E ao contrário de EXISTE , é necessária uma coluna válida com o tipo de dados apropriado.
Deixe-me esclarecer isso com outro exemplo:
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676Como você pode ver no código acima, tanto IN e NÃO EM operadores são introduzidos. E em ambos os casos, as linhas serão retornadas. Cada linha na consulta externa será comparada com o resultado de cada subconsulta para obter um produto disponível e um produto que não seja do fornecedor 1676.
Aninhamento de subconsultas SQL
Você pode aninhar subconsultas até 32 níveis. No entanto, essa capacidade depende da memória disponível do servidor e da complexidade de outras expressões na consulta.
Qual é a sua opinião sobre isso?
Na minha experiência, não me lembro de aninhar até 4. Raramente uso 2 ou 3 níveis. Mas isso é apenas eu e meus requisitos.
Que tal um bom exemplo para descobrir isso:
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))Como podemos ver neste exemplo, o aninhamento atingiu 2 níveis.
As subconsultas SQL são ruins para o desempenho?
Resumindo:sim e não. Em outras palavras, depende.
E não se esqueça, isso é no contexto do SQL Server.
Para começar, muitas instruções T-SQL que usam subconsultas podem ser reescritas usando JOIN s. E o desempenho para ambos é geralmente o mesmo. Apesar disso, existem casos particulares em que uma junção é mais rápida. E há casos em que a subconsulta funciona mais rapidamente.
Exemplo 1
Vamos examinar um exemplo de subconsulta. Antes de executá-los, pressione Control-M ou ative Incluir plano de execução real na barra de ferramentas do SQL Server Management Studio.
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')Alternativamente, a consulta acima pode ser reescrita usando uma junção que produz o mesmo resultado.
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'No final, o resultado para ambas as consultas é de 200 linhas.
Além disso, você pode conferir o plano de execução para ambas as instruções.
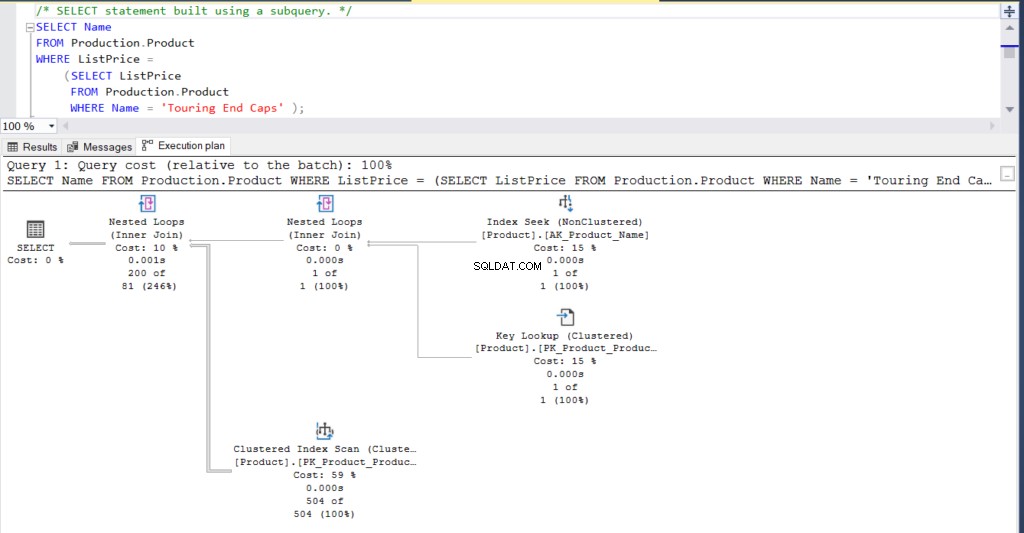
Figura 1:Plano de execução usando uma subconsulta
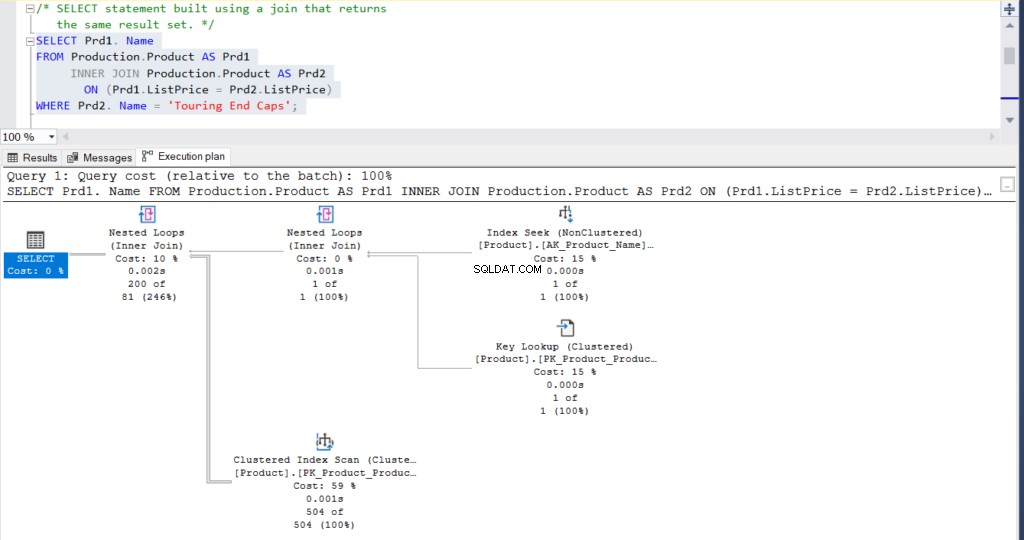
Figura 2:Plano de execução usando uma junção
O que você acha? São praticamente iguais? Exceto pelo tempo real decorrido de cada nó, todo o resto é basicamente o mesmo.
Mas aqui está outra maneira de compará-lo além das diferenças visuais. Sugiro usar o Compare Showplan .
Para realizá-lo, siga estes passos:
- Clique com o botão direito do mouse no plano de execução da instrução usando a subconsulta.
- Selecione Salvar plano de execução como .
- Nomeie o arquivo subquery-execution-plan.sqlplan .
- Vá para o plano de execução da instrução usando uma junção e clique com o botão direito do mouse.
- Selecione Comparar plano de exibição .
- Selecione o nome do arquivo que você salvou em #3.
Agora, confira mais informações sobre Compare Showplan .
Você deve ser capaz de ver algo semelhante a isto:
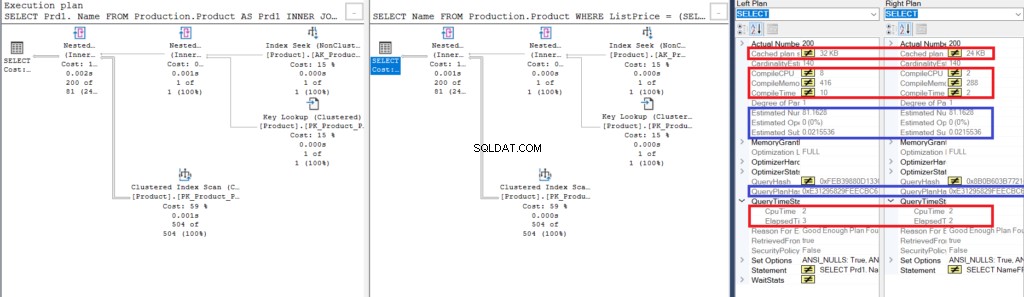
Figura 3:Comparar o Showplan para usar uma junção versus usar uma subconsulta
Observe as semelhanças:
- As linhas e os custos estimados são os mesmos.
- QueryPlanHash também é o mesmo, o que significa que eles têm planos de execução semelhantes.
No entanto, observe as diferenças:
- O tamanho do plano de cache é maior usando a junção do que usando a subconsulta
- A CPU e o tempo de compilação (em ms), incluindo a memória em KB, usada para analisar, vincular e otimizar o plano de execução é maior usando a junção do que a subconsulta
- O tempo de CPU e o tempo decorrido (em ms) para executar o plano são um pouco maiores usando a junção versus a subconsulta
Neste exemplo, a subconsulta é um tique mais rápido que a junção, mesmo que as linhas resultantes sejam as mesmas.
Exemplo 2
No exemplo anterior, usamos apenas uma tabela. No exemplo a seguir, vamos usar 3 tabelas diferentes.
Vamos fazer isso acontecer:
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Ambas as consultas geram as mesmas 3806 linhas.
Em seguida, vamos dar uma olhada em seus planos de execução:
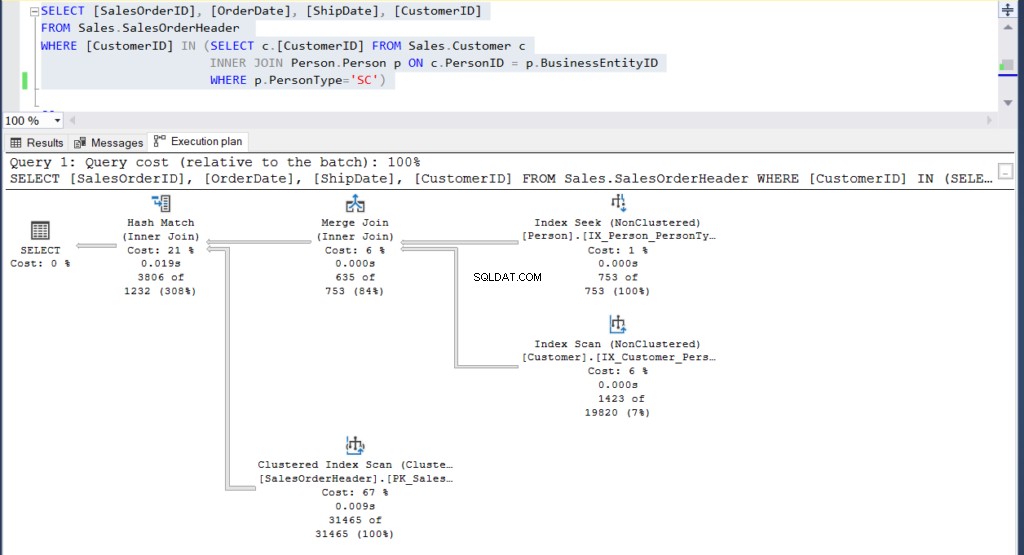
Figura 4:Plano de execução para nosso segundo exemplo usando uma subconsulta
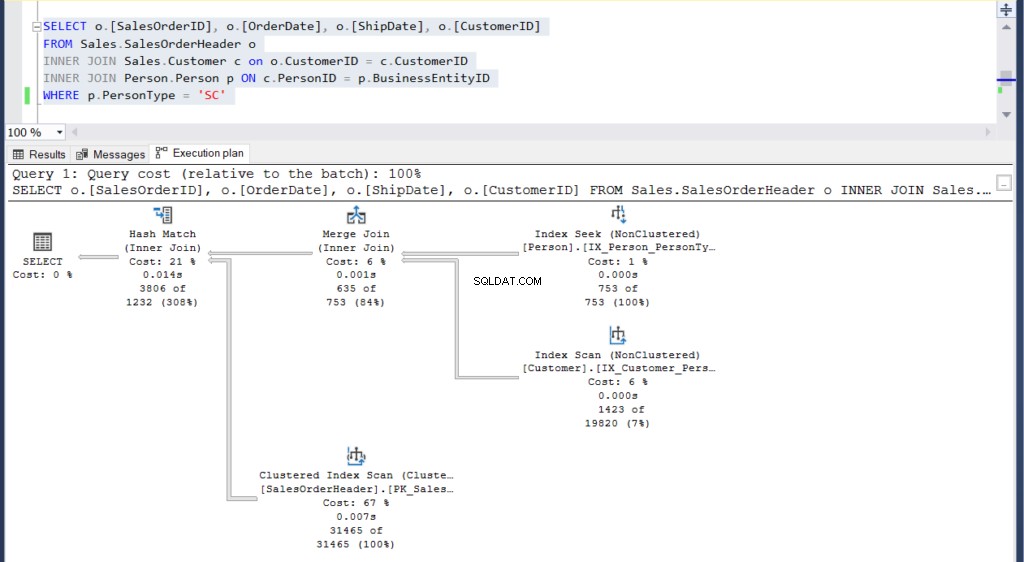
Figura 5:Plano de execução para nosso segundo exemplo usando uma junção
Você consegue ver os 2 planos de execução e encontrar alguma diferença entre eles? De relance, parecem iguais.
Mas um exame mais cuidadoso com o Compare Showplan revela o que está realmente dentro.
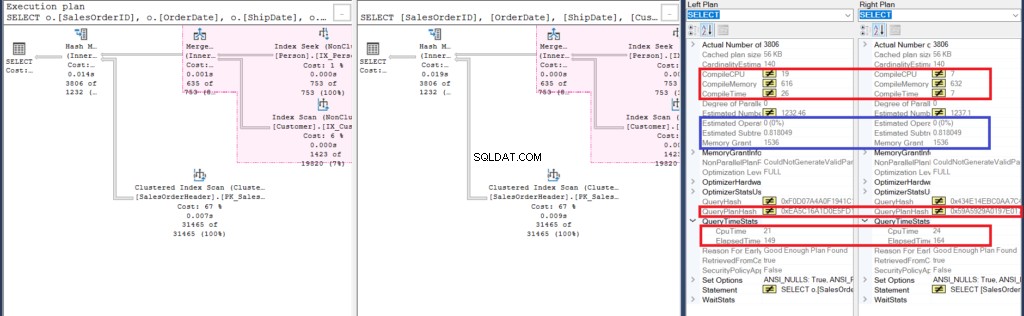
Figura 6:detalhes do plano de exibição de comparação para o segundo exemplo
Vamos começar analisando algumas semelhanças:
- O destaque em rosa no plano de execução revela operações semelhantes para ambas as consultas. Como a consulta interna usa uma junção em vez de aninhar subconsultas, isso é bastante compreensível.
- Os custos estimados do operador e da subárvore são os mesmos.
A seguir, vejamos as diferenças:
- Primeiro, a compilação demorou mais quando usamos junções. Você pode verificar isso em Compile CPU e Compile Time. No entanto, a consulta com uma subconsulta levou uma memória de compilação mais alta em KB.
- Então, o QueryPlanHash de ambas as consultas é diferente, o que significa que elas têm um plano de execução diferente.
- Por fim, o tempo decorrido e o tempo de CPU para executar o plano são mais rápidos usando a junção do que usar uma subconsulta.
Subconsulta vs. Conclusão do desempenho de participação
É provável que você enfrente muitos outros problemas relacionados à consulta que podem ser resolvidos usando uma junção ou uma subconsulta.
Mas o resultado final é que uma subconsulta não é inerentemente ruim em comparação com as junções. E não existe uma regra geral de que em uma situação específica uma junção seja melhor do que uma subconsulta ou o contrário.
Então, para ter certeza de que você tem a melhor escolha, verifique os planos de execução. O objetivo disso é obter informações sobre como o SQL Server processará uma consulta específica.
No entanto, se você optar por usar uma subconsulta, esteja ciente de que podem surgir problemas que testarão sua habilidade.
Avisos comuns no uso de subconsultas SQL
Existem 2 problemas comuns que podem fazer com que suas consultas se comportem descontroladamente ao usar subconsultas SQL.
O problema da resolução de nomes de colunas
Esse problema introduz bugs lógicos em suas consultas e eles podem ser muito difíceis de encontrar. Um exemplo pode esclarecer melhor esse problema.
Vamos começar criando uma tabela para fins de demonstração e preenchendo-a com dados.
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GOAgora que a tabela está definida, vamos disparar algumas subconsultas usando-a. Mas antes de executar a consulta abaixo, lembre-se de que os IDs de fornecedor que usamos no código anterior começam com '14'.
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)O código acima é executado sem erros, como você pode ver abaixo. De qualquer forma, preste atenção na lista de BusinessEntityIDs .
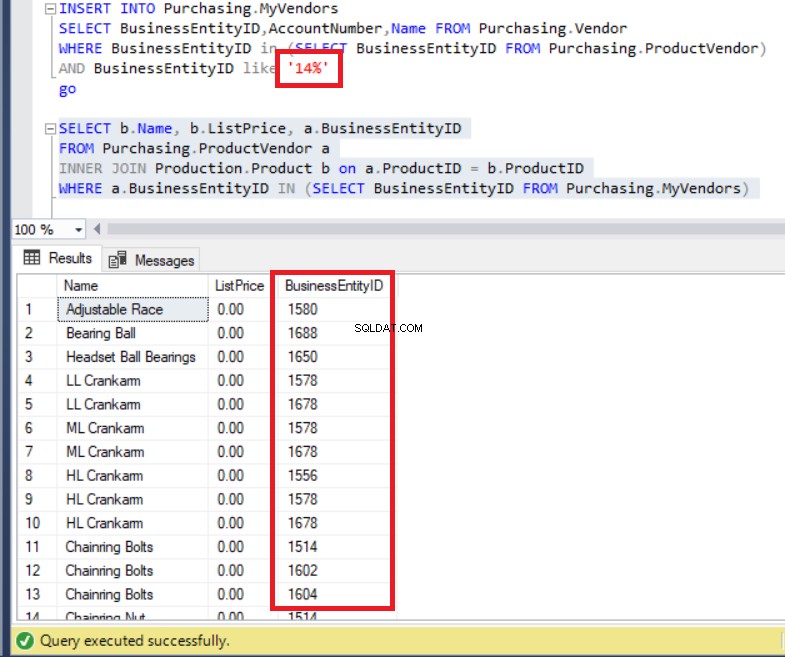
Figura 7:BusinessEntityIDs do conjunto de resultados são inconsistentes com os registros da tabela MyVendors
Não inserimos dados com BusinessEntityID começando com '14'? Então qual é o problema? Na verdade, podemos ver BusinessEntityIDs que começam com '15' e '16'. de onde isso veio?
Na verdade, a consulta listou todos os dados do ProductVendor tabela.
Nesse caso, você pode pensar que um alias resolverá esse problema para que ele se refira a MyVendors tabela igual a abaixo:
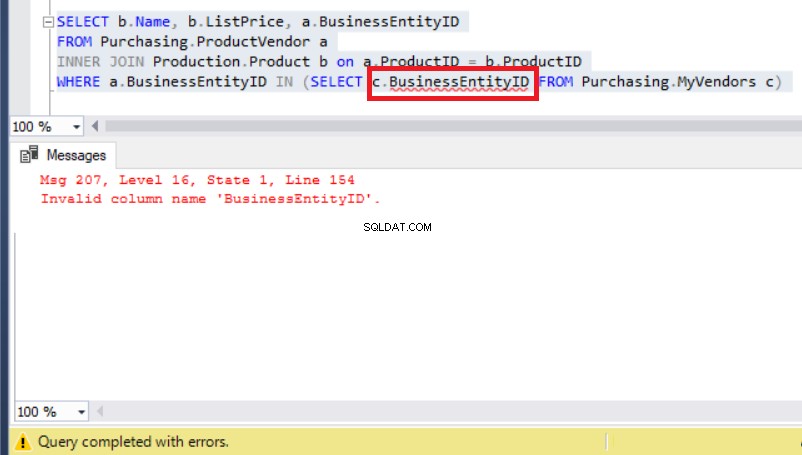
Figura 8:adicionar um alias ao BusinessEntityID resulta em erro
Só que agora o problema real apareceu por causa de um erro de tempo de execução.
Verifique os Meus fornecedores table novamente e você verá que em vez de BusinessEntityID , o nome da coluna deve ser BusinessEntity_id (com sublinhado).
Assim, usar o nome de coluna correto finalmente corrigirá esse problema, como você pode ver abaixo:
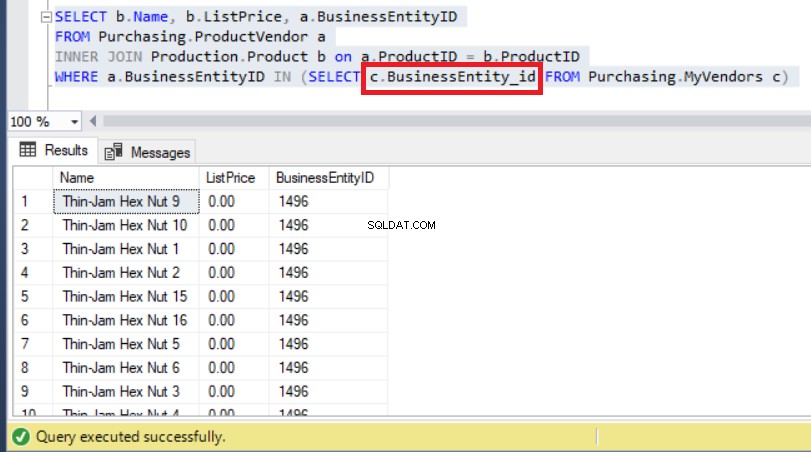
Figura 9:Alterar a subconsulta com o nome correto da coluna resolveu o problema
Como você pode ver acima, agora podemos observar BusinessEntityIDs começando com '14' exatamente como esperávamos anteriormente.
Mas você pode se perguntar: por que diabos o SQL Server permitiu executar a consulta com sucesso em primeiro lugar?
Aqui está o kicker:a resolução de nomes de colunas sem alias funciona no contexto da subconsulta de si mesma para a consulta externa. É por isso que a referência a BusinessEntityID dentro da subconsulta não acionou um erro porque está fora da subconsulta – no ProductVendor tabela.
Em outras palavras, o SQL Server procura a coluna sem alias BusinessEntityID em Meus fornecedores tabela. Como não está lá, ele olhou para fora e o encontrou no ProductVendor tabela. Louco, não é?
Você pode dizer que é um bug no SQL Server, mas, na verdade, é por design no padrão SQL e a Microsoft o seguiu.
Tudo bem, está claro, não podemos fazer nada sobre o padrão, mas como podemos evitar erros?
- Primeiro, prefixe os nomes das colunas com o nome da tabela ou use um alias. Em outras palavras, evite nomes de tabela sem prefixo ou sem alias.
- Segundo, tenha uma nomenclatura consistente de colunas. Evite ter ambos BusinessEntityID e BusinessEntity_id , por exemplo.
Soa bem? Sim, isso traz alguma sanidade para a situação.
Mas este não é o fim.
NULLs malucos
Como eu mencionei, há mais para cobrir. T-SQL usa lógica de 3 valores devido ao suporte para NULL . E NULO pode quase nos deixar loucos quando usamos subconsultas SQL com NOT IN .
Deixe-me começar apresentando este exemplo:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)A saída da consulta nos leva a uma lista de produtos que não estão em MyVendors tabela., como visto abaixo:
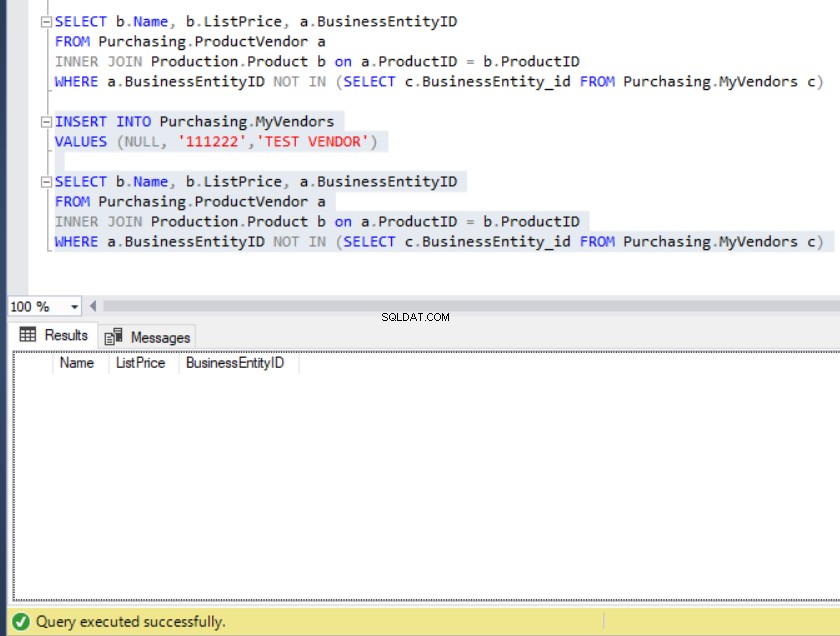
Figura 10:a saída da consulta de exemplo usando NOT IN
Agora, suponha que alguém acidentalmente inseriu um registro no MyVendors tabela com um NULL BusinessEntity_id . O que vamos fazer sobre isso?
Figura 11:o conjunto de resultados fica vazio quando um NULL BusinessEntity_id é inserido em MyVendors
Para onde foram todos os dados?
Veja, o NÃO operador negou o IN predicado. Portanto, NÃO É VERDADEIRO agora se tornará FALSO . Mas NÃO NULO É desconhecido. Isso fez com que o filtro descartasse as linhas que são UNKNOWN, e esse é o culpado.
Para garantir que isso não aconteça com você:
- Faça com que a coluna da tabela não permita NULLs se os dados não deveriam ser assim.
- Ou adicione o column_name IS NOT NULL para o seu ONDE cláusula. No nosso caso, a subconsulta é a seguinte:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)Recomendações
Já falamos bastante sobre subconsultas, e chegou a hora de fornecer as principais conclusões deste post na forma de uma lista resumida:
Uma subconsulta:
- é uma consulta dentro de uma consulta.
- está entre parênteses.
- pode substituir uma expressão em qualquer lugar.
- pode ser usado em SELECT , INSERIR , ATUALIZAÇÃO , EXCLUIR, ou outras instruções T-SQL.
- pode ser independente ou correlacionado.
- gera valores únicos, múltiplos ou de tabela.
- funciona em operadores de comparação como =, <>,>, <,>=, <=e operadores lógicos como IN /NÃO DENTRO e EXISTE /NÃO EXISTE .
- não é ruim ou mau. Pode ter um desempenho melhor ou pior do que JOIN s dependendo de uma situação. Portanto, siga meu conselho e sempre verifique os planos de execução.
- pode ter um comportamento desagradável em NULL s quando usado com NOT IN , e quando uma coluna não é explicitamente identificada com uma tabela ou alias de tabela.
Familiarize-se com várias referências adicionais para o seu prazer de leitura:
- Discussão de subconsultas da Microsoft.
- IN (Transact-SQL)
- EXISTE (Transact-SQL)
- TODOS (Transact-SQL)
- ALGUNS | ANY (Transact-SQL)
- Operadores de comparação