Introdução
Há alguns anos, fomos encarregados de um requisito comercial de dados de cartão em um formato específico para o propósito de algo chamado “reconciliação”. A ideia era apresentar os dados em uma tabela para uma aplicação que consumisse e processasse os dados que teriam um período de retenção de seis meses. Tivemos que criar um novo banco de dados para essa necessidade comercial e, em seguida, criar a tabela principal como uma tabela particionada. O processo descrito aqui é o processo que usamos para garantir que os dados com mais de seis meses sejam removidos da tabela de maneira limpa.
Um pouco sobre particionamento
Table Partitioning é uma tecnologia de banco de dados que permite armazenar dados pertencentes a uma unidade lógica (a tabela) como um conjunto de partições que ficarão em uma estrutura física separada – arquivos de dados – por meio de uma camada de abstração chamada Grupos de Arquivos no SQL Server. O processo de criação desta Tabela Particionada envolve dois objetos principais:
Uma função de partição :Uma Função de Partição define como as linhas de uma tabela particionada são mapeadas com base nos valores de uma coluna especificada (a Coluna de Partição). Uma tabela particionada pode ser baseada em uma lista ou um intervalo. Para fins de nosso caso de uso (preservando apenas seis meses de dados), usamos uma Partição de intervalo . Uma função de partição pode ser definida como RANGE RIGHT ou RANGE LEFT. Usamos RANGE RIGHT conforme mostrado no código na Listagem 1, o que significa que o valor do limite pertencerá ao lado direito do intervalo do valor do limite quando os valores forem classificados em ordem crescente da esquerda para a direita.
-- Listing 1: Create a Partition Function
USE [post_office_history]
GO
CREATE PARTITION FUNCTION
PostTranPartFunc (datetime)
AS RANGE RIGHT
FOR VALUES
('20190201'
,'20190301'
,'20190401'
,'20190501'
,'20190601'
,'20190701'
,'20190801'
,'20190901'
,'20191001'
,'20191101'
,'20191201'
)
GO Um esquema de partição :Um esquema de partição é baseado na Função de Partição e determina em quais estruturas físicas as linhas pertencentes a cada partição serão colocadas. Isso é obtido mapeando essas linhas para grupos de arquivos. A Listagem 2 mostra o código para criar um Esquema de Partição. Antes de criar o Esquema de Partição, os grupos de arquivos aos quais ele se referirá devem existir.
-- Listing 2: Create Partition Scheme -- -- Step 1: Create Filegroups -- USE [master] GO ALTER DATABASE [post_office_history] ADD FILEGROUP [JAN] ALTER DATABASE [post_office_history] ADD FILEGROUP [FEB] ALTER DATABASE [post_office_history] ADD FILEGROUP [MAR] ALTER DATABASE [post_office_history] ADD FILEGROUP [APR] ALTER DATABASE [post_office_history] ADD FILEGROUP [MAY] ALTER DATABASE [post_office_history] ADD FILEGROUP [JUN] ALTER DATABASE [post_office_history] ADD FILEGROUP [JUL] ALTER DATABASE [post_office_history] ADD FILEGROUP [AUG] ALTER DATABASE [post_office_history] ADD FILEGROUP [SEP] ALTER DATABASE [post_office_history] ADD FILEGROUP [OCT] ALTER DATABASE [post_office_history] ADD FILEGROUP [NOV] ALTER DATABASE [post_office_history] ADD FILEGROUP [DEC] GO -- Step 2: Add Data Files to each Filegroup -- USE [master] GO ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_01', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JAN] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_02', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_02.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [FEB] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_03', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [MAR] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_04', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_04.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [APR] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_05', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_05.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [MAY] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_06', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_06.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JUN] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_07', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_07.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JUL] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_08', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_08.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [AUG] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_09', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [SEP] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_10', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [OCT] GO ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_09', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_11.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [NOV] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_10', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_12.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [DEC] GO -- Step 3: Create Partition Scheme -- PRINT 'creating partition scheme ...' GO USE [post_office_history] GO CREATE PARTITION SCHEME PostTranPartSch AS PARTITION PostTranPartFunc TO ( JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC ) GO
Observe que para N partições, sempre haverá N-1 limites. Deve-se tomar cuidado ao definir o primeiro grupo de arquivos no esquema de partição. O primeiro limite listado na Função de Partição ficará entre o primeiro e o segundo Grupos de Arquivos, portanto, esse valor de limite (20190201) ficará na segunda partição (FEB). Além disso, é possível colocar todas as partições em um único grupo de arquivos, mas neste caso escolhemos grupos de arquivos separados.
Suja as mãos
Então, vamos mergulhar na tarefa de trocar as partições!
A primeira coisa que precisamos fazer é determinar exatamente como nossos dados são distribuídos entre as partições para que possamos saber qual partição gostaríamos de mudar. Normalmente, vamos trocar a partição mais antiga.
-- Listing 3: Check Data Distribution in Partitions -- USE POST_OFFICE_HISTORY GO SELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) AS [PARTITION NUMBER] , MIN(DATETIME_TRAN_LOCAL) AS [MIN DATE] , MAX(DATETIME_TRAN_LOCAL) AS [MAX DATE] , COUNT(*) AS [ROWS IN PARTITION] FROM DBO.POST_TRAN_TAB -- PARTITIONED TABLE GROUP BY $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) ORDER BY [PARTITION NUMBER] GO
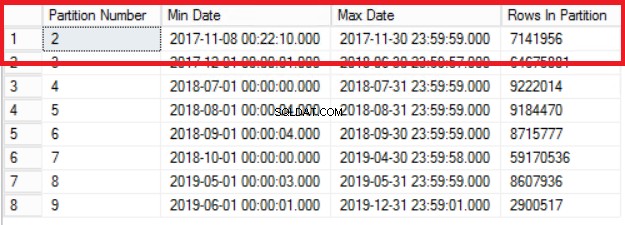
Fig. 1 Saída da Listagem 3
A Fig. 1 mostra a saída da consulta na Listagem 3. A partição mais antiga é a Partição 2 que contém linhas do ano de 2017. Verificamos isso com a consulta na Listagem 4. A Listagem 4 também nos mostra qual Grupo de Arquivos contém os dados na Partição 2.
-- Listing 4: Check Filegroup Associated with Partition --
USE POST_OFFICE_HISTORY
GO
SELECT PS.NAME AS PSNAME,
DDS.DESTINATION_ID AS PARTITIONNUMBER,
FG.NAME AS FILEGROUPNAME
FROM (((SYS.TABLES AS T
INNER JOIN SYS.INDEXES AS I
ON (T.OBJECT_ID = I.OBJECT_ID))
INNER JOIN SYS.PARTITION_SCHEMES AS PS
ON (I.DATA_SPACE_ID = PS.DATA_SPACE_ID))
INNER JOIN SYS.DESTINATION_DATA_SPACES AS DDS
ON (PS.DATA_SPACE_ID = DDS.PARTITION_SCHEME_ID))
INNER JOIN SYS.FILEGROUPS AS FG
ON DDS.DATA_SPACE_ID = FG.DATA_SPACE_ID
WHERE (T.NAME = 'POST_TRAN_TAB') AND (I.INDEX_ID IN (0,1))
AND DDS.DESTINATION_ID = $PARTITION.POSTTRANPARTFUNC('20171108') ; Fig. 1 Saída da Listagem 3
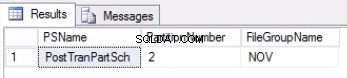
Fig. 2 Saída da Listagem 4
A Listagem 4 nos mostra que o grupo de arquivos associado à Partição 2 é NOV . Para trocar a Partição 2, precisamos de uma tabela de histórico que é uma réplica da tabela ativa, mas fica no mesmo grupo de arquivos da partição que pretendemos trocar. Como já temos essa tabela, tudo o que precisamos é recriá-la no grupo de arquivos desejado. Você também precisa recriar o índice clusterizado. Observe que este índice clusterizado tem a mesma definição que o índice clusterizado na tabela post_tran_tab e também fica no mesmo grupo de arquivos que post_tran_tab_hist tabela.
-- Listing 5: Re-create the History Table -- Re-create the History Table -- USE [post_office_history] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO DROP TABLE [dbo].[post_tran_tab_hist] GO CREATE TABLE [dbo].[post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [char](4) NULL, [source_node_name] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_node_currency_code] [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_rsp] [float] NOT NULL, [datetime_tran_gmt] [char](10) NULL, [merchant_type] [char](4) NULL, [pos_entry_mode] [char](3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char](15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code] [char](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approved] [float] NOT NULL, [tran_completed] [char](2) NULL ) ON [NOV] GO SET ANSI_PADDING OFF GO -- Re-create the Clustered Index -- USE [post_office_history] GO CREATE CLUSTERED INDEX [IX_Datetime_Local] ON [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [NOV] GO
Alternar a última partição agora é um comando de uma linha. Fazer uma contagem de ambas as tabelas antes e depois de executar este comando de uma linha garantirá que temos todos os dados desejados.
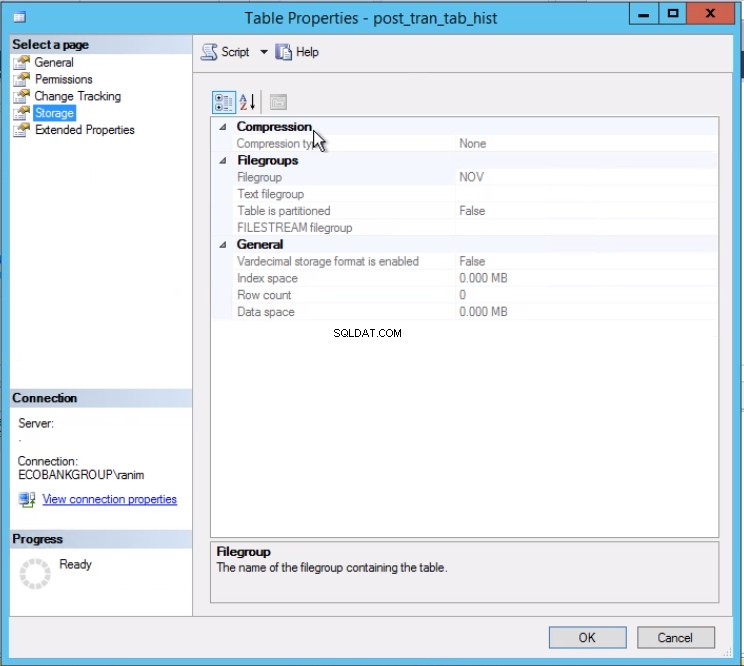
Fig. 3 A tabela post_tran_tab_hist fica no grupo de arquivos NOV
-- Listing 6: Switching Out the Last Partition SELECT COUNT(*) FROM 'POST_TRAN_TAB'; SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST'; USE [POST_OFFICE_HISTORY] GO ALTER TABLE POST_TRAN_TAB SWITCH PARTITION 2 TO POST_TRAN_TAB_HIST GO SELECT COUNT(*) FROM 'POST_TRAN_TAB'; SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST';
Como nós trocamos a última partição, não precisamos mais do limite. Mesclamos os dois intervalos anteriormente divididos por esse limite usando o comando na Listagem 7. Truncamos ainda mais a tabela de histórico conforme mostrado na Listagem 8. Estamos fazendo isso porque este é o ponto principal:remover dados antigos que não precisamos mais.
-- Listing 7: Merging Partition Ranges
-- Merge Range
USE [POST_OFFICE_HISTORY]
GO
ALTER PARTITION FUNCTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');
-- Confirm Range Is Merged
USE [POST_OFFICE_HISTORY]
GO
SELECT * FROM SYS.PARTITION_RANGE_VALUES
GO 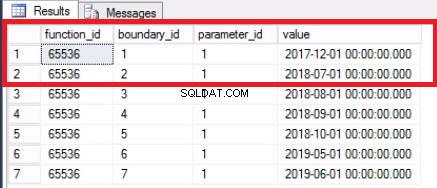
Fig. 4 Limite mesclado
-- Listing 8: Truncate the History Table USE [post_office_history] GO TRUNCATE TABLE post_tran_tab_hist; GO
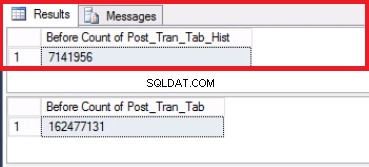
Fig. 5 Contagem de linhas para ambas as tabelas antes de truncar
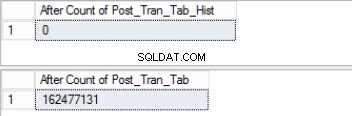
Observe que o número de linhas na tabela de histórico é exatamente o mesmo que o número de linhas anteriormente na Partição 2, conforme mostrado na Fig. 1. Você também pode ir além recuperando o espaço vazio no grupo de arquivos pertencente ao último partição. Isso será útil se você precisar desse espaço para os novos dados que ficarão na partição anterior. Esta etapa pode não ser necessária se você achar que tem um amplo espaço em seu ambiente.
-- Listing 9: Recover Space on Operating System -- Determine that File has been emptied USE [post_office_history] GO SELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS.DATABASE_FILES DF JOIN SYS.DATA_SPACES DS ON DF.DATA_SPACE_ID = DS.DATA_SPACE_ID;
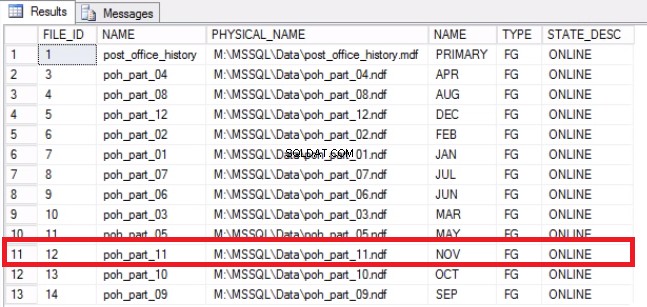
Fig. 7 Mapeamentos de arquivo para grupo de arquivos
-- Shrink the file to 2GB USE [post_office_history] GO DBCC SHRINKFILE (N'post_office_history_part_11’, 2048) GO -- From the OS confirm free space on disks SELECT DISTINCT DB_NAME (S.DATABASE_ID) AS DATABASE_NAME, S.DATABASE_ID, S.VOLUME_MOUNT_POINT --, S.VOLUME_ID , S.LOGICAL_VOLUME_NAME , S.FILE_SYSTEM_TYPE , S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)] , S.AVAILABLE_BYTES/1024/1024/1024 AS [FREE_SPACE (GB)] , LEFT ((ROUND (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) AS PERCENT_FREE FROM SYS.MASTER_FILES AS F CROSS APPLY SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.FILE_ID) AS S WHERE DB_NAME (S.DATABASE_ID) = 'POST_OFFICE_HISTORY';

Fig. 8 Espaço Livre no Sistema Operacional
Conclusão
Neste artigo, fizemos um passo a passo do processo para alternar as partições de uma tabela particionada. Essa é uma maneira muito eficiente de gerenciar o crescimento de dados de forma nativa no SQL Server. Tecnologias mais avançadas, como Stretch Database, estão disponíveis nas versões atuais do SQL Server.
Referências
Isakov, V. (2018). Exame Ref 70-764 Administrando uma Infraestrutura de Banco de Dados SQL. Pearson Education
Tabelas e índices particionados no SQL Server