Na programação de banco de dados, existem quatro operações fundamentais:criar , leia , atualizar e excluir – CRUD operações. Eles são o primeiro passo na programação de banco de dados.
O termo CRUD apareceu pela primeira vez no livro de James Martin ‘Managing the Database Environment’. Neste artigo, vamos explorar a operação CRUD em termos de SQL Server porque a sintaxe da operação pode ser diferente de outros bancos de dados relacionais e NoSQL.
Preparações
A ideia principal dos bancos de dados relacionais é armazenar dados em tabelas. Os dados da tabela podem ser lidos, inseridos, excluídos. Dessa forma, as operações CRUD manipulam os dados da tabela.
| C | C REATE | Inserir linha/linhas em uma tabela |
| R | R EAD | Ler (selecionar) linha/linhas de uma tabela |
| U | U PDATE | Editar linha/linhas na tabela |
| D | D ELE | Excluir linha/linhas da tabela |
Para ilustrar as operações CRUD, precisamos de uma tabela de dados. Vamos criar um. Ele conterá apenas três colunas. A primeira coluna armazenará os nomes dos países, a segunda armazenará o continente desses países e a última coluna armazenará a população desses países. Podemos criar esta tabela com a ajuda da instrução T-SQL e intitular como TblCountry .
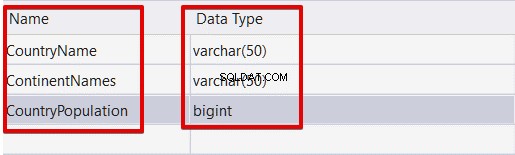
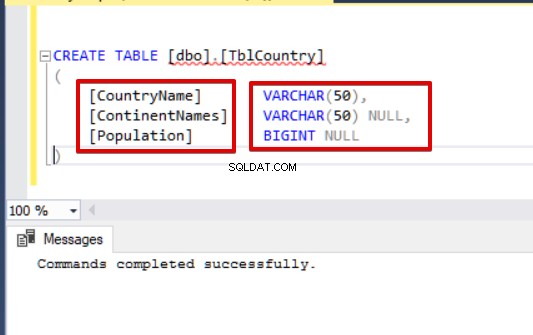
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL
)
Agora, vamos revisar as operações CRUD realizadas no TblCountry tabela.
C – CRIAR
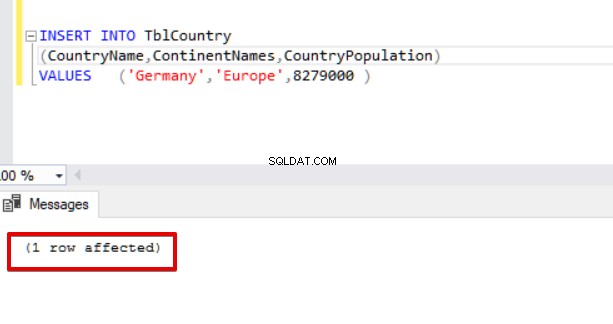
Para adicionar novas linhas a uma tabela, usamos o INSERT INTO comando. Neste comando, precisamos especificar o nome da tabela de destino e listaremos os nomes das colunas entre colchetes. A estrutura da instrução deve terminar com VALUES:
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES ('Germany','Europe',8279000 )
Para adicionar várias linhas à tabela, podemos usar o seguinte tipo de instrução INSERT:
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Observe que o INTO palavra-chave é opcional e você não precisa usá-la nas instruções de inserção.
INSERT TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Além disso, você pode usar o seguinte formato para inserir várias linhas na tabela:
INSERT INTO TblCountry
SELECT 'Germany','Europe',8279000
UNION ALL
SELECT 'Japan','Asia',126800000
UNION ALL
SELECT 'Moroco','Africa',35740000
Agora, copiaremos os dados diretamente da tabela de origem para a tabela de destino. Este método é conhecido como INSERT INTO … SELECT demonstração.
INSERT INTO … SELECT requer a correspondência dos tipos de dados das tabelas de origem e destino. Na instrução INSERT INTO … SELECT a seguir, inseriremos os dados do SourceCountryTbl tabela no TblCountry tabela.
Inicialmente, inserimos alguns dados sintéticos no SourceCountryTbl mesa para esta demonstração.
DROP TABLE IF EXISTS [SourceCountryTbl]
CREATE TABLE [dbo].[SourceCountryTbl]
(
[SourceCountryName] VARCHAR(50),
[SourceContinentNames] VARCHAR(50) NULL,
[SourceCountryPopulation] BIGINT NULL
)
INSERT INTO [SourceCountryTbl]
VALUES
('Ukraine','Europe',44009214 ) ,
('UK','Europe',66573504) ,
('France','Europe',65233271)
Agora vamos executar a instrução INSERT INTO … SELECT.
INSERT INTO TblCountry
SELECT * FROM SourceCountryTbl
A instrução de inserção acima adicionou todos os SourceCountryTbl dados para o TblCountry tabela. Também podemos adicionar o WHERE cláusula para filtrar a instrução select.
INSERT INTO TblCountry
SELECT * FROM SourceCountryTbl WHERE TargetCountryName='UK'
O SQL Server nos permite usar variáveis de tabela (objetos que ajudam a armazenar dados temporários de tabela no escopo local) com as instruções INSERT INTO … SELECT. Na demonstração a seguir, usaremos a variável table como uma tabela de origem:
DECLARE @SourceVarTable AS TABLE
([TargetCountryName] VARCHAR(50),
[TargetContinentNames] VARCHAR(50) NULL,
[TargetCountryPopulation] BIGINT NULL
)
INSERT INTO @SourceVarTable
VALUES
('Ukraine','Europe',44009214 ) ,
('UK','Europe',66573504) ,
('France','Europe',65233271)
INSERT INTO TblCountry
SELECT * FROM @SourceVarTable
Dica :A Microsoft anunciou um recurso no SQL Server 2016 que é inserção paralela . Esse recurso nos permite realizar operações INSERT em threads paralelas.
Se você adicionar o TABLOCK dica no final de sua instrução de inserção, o SQL Server pode escolher um plano de execução paralela com o processamento de acordo com o grau máximo de paralelismo do seu servidor ou o limite de custo para parâmetros de paralelismo.
O processamento de inserção paralela também reduzirá o tempo de execução da instrução de inserção. No entanto, o TABLOCO dica irá adquirir o bloqueio da tabela inserida durante a operação de inserção. Para mais informações sobre a inserção paralela, você pode consultar o Real World Parallel INSERT…SELECT.
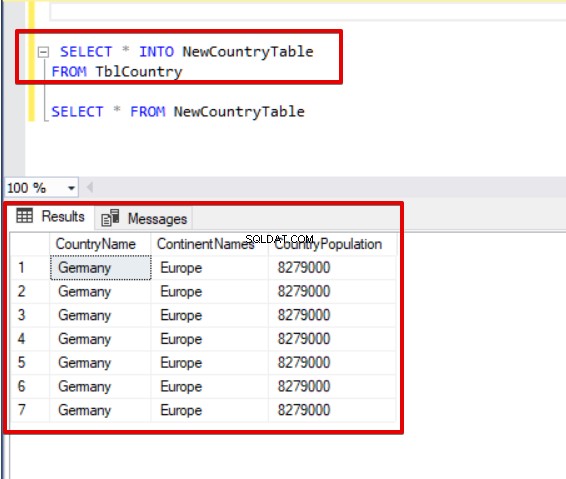
Outra instrução útil é SELECT INTO. Esse método nos permite copiar dados de uma tabela para uma tabela recém-criada. Na declaração a seguir, NewCountryTable não existia antes da execução da consulta. A consulta cria a tabela e insere todos os dados do TblCountry tabela.
SELECT * INTO NewCountryTable
FROM TblCountry
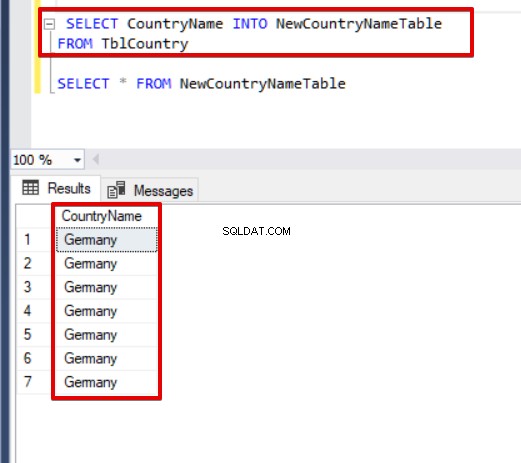
Ao mesmo tempo, podemos criar uma nova tabela para colunas específicas da tabela de origem.
Em alguns casos, precisamos retornar e usar valores inseridos da instrução INSERT. Desde o SQL Server 2005, a instrução INSERT nos permite recuperar valores em questão da instrução INSERT.
Agora, vamos descartar e criar nossa tabela de teste e adicionar uma nova coluna de identidade. Além disso, adicionaremos uma restrição padrão a esta coluna. Assim, se não inserirmos nenhum valor explícito nesta coluna, ela criará automaticamente um novo valor.
No exemplo a seguir, declararemos uma tabela com uma coluna e inseriremos a saída do SeqID valor da coluna para esta tabela com a ajuda da coluna OUTPUT:
DROP TABLE IF EXISTS TblCountry
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL ,
SeqID uniqueidentifier default(newid())
)
DECLARE @OutputID AS TABLE(LogID uniqueidentifier)
INSERT TblCountry
(CountryName,ContinentNames,CountryPopulation)
OUTPUT INSERTED.SeqId INTO @OutputID
VALUES
('Germany','Europe',8279000 )
SELECT * FROM @OutPutId
R – Ler
A Ler A operação recupera dados de uma tabela e retorna um conjunto de resultados com os registros da tabela. Caso queiramos recuperar dados de mais de uma tabela, podemos utilizar o operador JOIN e criar uma relação lógica entre as tabelas.
A instrução SELECT desempenha um único papel principal no ler Operação. É baseado em três componentes:
- Coluna – definimos as colunas das quais queremos recuperar dados
- Tabela – nós especifique a tabela da qual queremos obter dados
- Filtro – nós pode filtrar os dados que queremos ler. Esta parte é opcional.
A forma mais simples da instrução select é a seguinte:
SELECT column1, column2,...,columnN
FROM table_name
Agora, vamos passar pelos exemplos. Inicialmente, precisamos de uma tabela de amostra para ler. Vamos criá-lo:
DROP TABLE IF EXISTS TblCountry
GO
CREATE TABLE [dbo].[TblCountry]
(
[CountryName] VARCHAR(50),
[ContinentNames] VARCHAR(50) NULL,
[CountryPopulation] BIGINT NULL
)
GO
INSERT INTO TblCountry
(CountryName,ContinentNames,CountryPopulation)
VALUES
('Germany','Europe',8279000 ),
('Japan','Asia',126800000 ),
('Moroco','Africa',35740000)
Ler todas as colunas da tabela
O operador asterisco (*) é usado nas instruções SELECT porque retorna todas as colunas da tabela:
SELECT * FROM TblCountry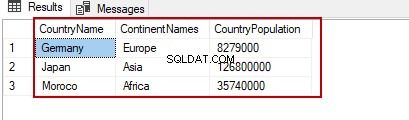
Dica :O operador asterisco (*) pode influenciar negativamente o desempenho porque causa mais tráfego de rede e consome mais recursos. Assim, se você não precisar obter todos os dados de todas as colunas retornadas, evite usar o asterisco (*) na instrução SELECT.
Lendo colunas específicas da tabela
Podemos ler colunas específicas da tabela também. Vamos analisar o exemplo que retornará apenas o CountryName e PaísPopulação colunas:
SELECT CountryName,CountryPopulation FROM TblCountry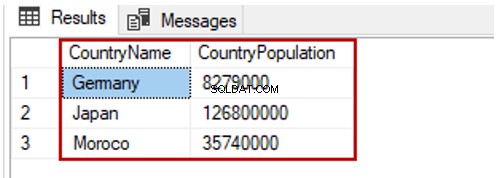
Usando alias nas instruções SELECT
Nas instruções SELECT, podemos dar nomes temporários à tabela ou colunas. Esses nomes temporários são aliases. Vamos reescrever as duas consultas anteriores com aliases de tabela e coluna.
Na consulta a seguir, o TblC alias especificará o nome da tabela:
SELECT TblC.* FROM TblCountry TblC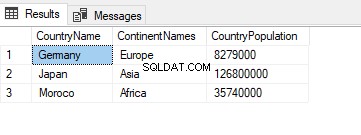
No exemplo a seguir, forneceremos aliases para os nomes das colunas. Alteraremos Nome do País para CName e PaísPopulação – para CPop .
SELECT TblC.CountryName AS [CName], CountryPopulation AS [CPop] FROM TblCountry TblC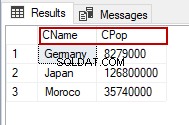
Os objetivos do alias são:
- Torne a consulta mais legível se os nomes das tabelas ou colunas forem complexos.
- Certifique-se de usar uma consulta para a tabela mais de uma vez.
- Simplifique a escrita da consulta se o nome da tabela ou coluna for longo.
Filtrando instruções SELECT
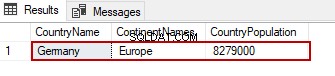
As instruções SELECT nos permitem filtrar os conjuntos de resultados por meio da cláusula WHERE. Por exemplo, queremos filtrar a instrução SELECT de acordo com o CountryName coluna e retornar apenas os dados da Alemanha no conjunto de resultados. A consulta a seguir realizará a operação de leitura com um filtro:
SELECT TblC.* FROM TblCountry TblC
WHERE TblC.CountryName='Germany'
Classificando resultados de instruções SELECT
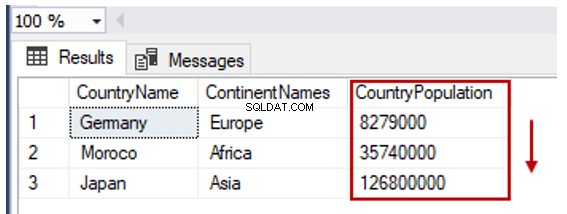
A cláusula ORDER BY nos ajuda a classificar o conjunto de resultados da instrução SELECT pela coluna ou colunas especificadas. Podemos realizar ordenação ascendente ou descendente com a ajuda da cláusula ORDER BY.
Classificaremos o TblCountry tabela de acordo com a população dos países em ordem crescente:
SELECT TblC.* FROM TblCountry TblC
ORDER BY TblC.CountryPopulation ASC
Dica :você pode usar o índice da coluna na cláusula ORDER BY e os números do índice das colunas começam por 1.
Também podemos escrever a consulta anterior. O número três (3) indica a CounrtyPopulation coluna:
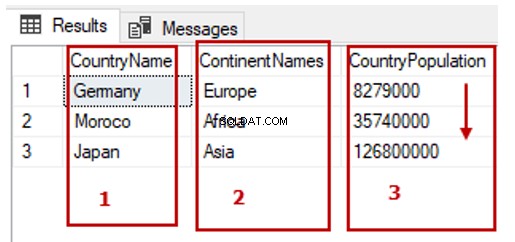
SELECT TblC.* FROM TblCountry TblC
ORDER BY 3 ASC
U – Atualização
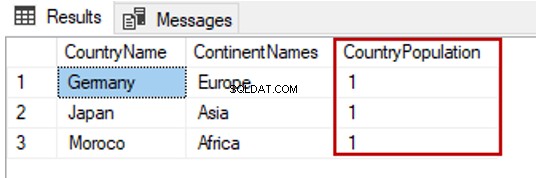
A instrução UPDATE modifica os dados existentes na tabela. Essa instrução deve incluir a cláusula SET para que possamos definir a coluna de destino para modificar os dados.
A consulta a seguir alterará todas as linhas da CounrtyPopulation valor da coluna para 1.
UPDATE TblCountry SET CountryPopulation=1
GO
SELECT TblC.* FROM TblCountry TblC
Nas instruções UPDATE, podemos usar a cláusula WHERE para modificar uma linha ou linhas específicas na tabela.
Vamos mudar o Japão linha de CounrtyPopulation para 245000:
UPDATE TblCountry SET CountryPopulation=245000
WHERE CountryName = 'Japan'
GO
SELECT TblC.* FROM TblCountry TblC
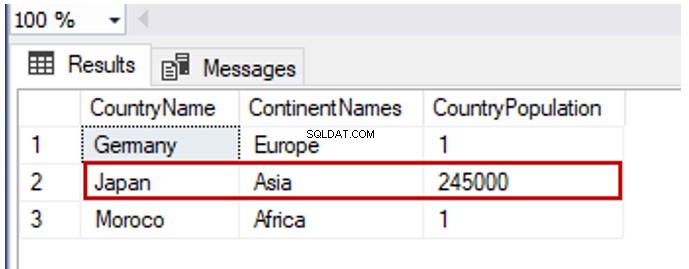
A instrução UPDATE é uma união das instruções delete e insert. Assim, podemos retornar os valores inseridos e excluídos através da cláusula OUTPUT.
Vamos fazer um exemplo:
UPDATE TblCountry SET CountryPopulation=22
OUTPUT inserted.CountryPopulation AS [Insertedvalue],
deleted.CountryPopulation AS [Deletedvalue]
WHERE CountryName = 'Germany'
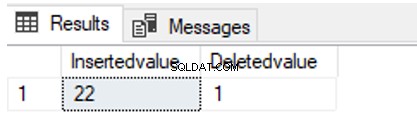
Como você pode ver, modificamos a CountryPopulation valor de 1 a 22. Então podemos descobrir os valores inseridos e excluídos. Além disso, podemos inserir esses valores em uma variável de tabela (um tipo de variável especial que pode ser usado como tabela).
Vamos inserir os valores inseridos e excluídos na variável da tabela:
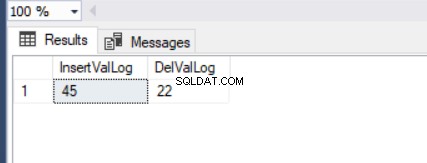
DECLARE @LogTable TABLE(InsertValLog INT , DelValLog INT)
UPDATE TblCountry SET CountryPopulation=45
OUTPUT inserted.CountryPopulation ,
deleted.CountryPopulation INTO @LogTable
WHERE CountryName = 'Germany'
SELECT * FROM @LogTable
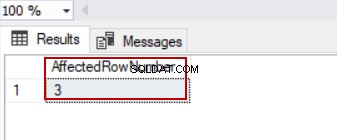
@@ROWCOUNT é uma variável de sistema que retorna o número de linhas afetadas na última instrução. Assim, podemos usar essa variável para expor algumas linhas modificadas na instrução de atualização.
No exemplo a seguir, a consulta de atualização mudará 3 linhas e a variável de sistema @@ROWCOUNT retornará 3.
UPDATE TblCountry SET CountryPopulation=1
SELECT @@ROWCOUNT AS [AffectedRowNumber]
D – Excluir
A instrução Delete remove a(s) linha(s) existente(s) da tabela.
Primeiramente, vamos ver como usar a cláusula WHERE nas instruções DELETE. Na maioria das vezes, queremos filtrar as linhas excluídas.
O exemplo abaixo ilustra como remover uma linha específica:
SELECT TblC.* FROM TblCountry TblC
DELETE FROM TblCountry WHERE CountryName='Japan'
SELECT TblC.* FROM TblCountry TblC
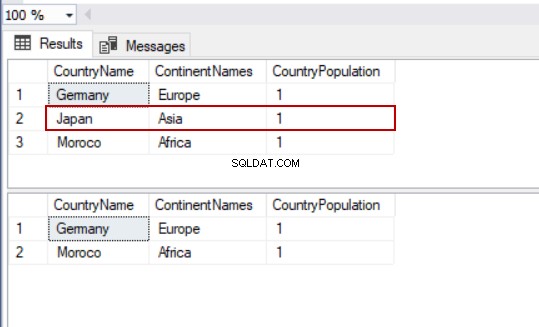
Embora com a instrução DELETE, podemos remover todos os registros da tabela. No entanto, a instrução DELETE é muito básica e não usamos a condição WHERE.
SELECT TblC.* FROM TblCountry TblC
DELETE FROM TblCountry
SELECT TblC.* FROM TblCountry TblC
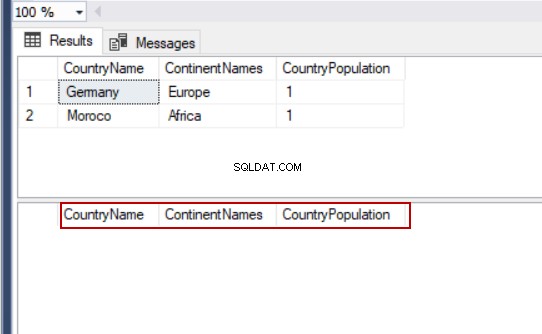
Ainda assim, em algumas circunstâncias dos designs de banco de dados, a instrução DELETE não exclui a(s) linha(s) se violar chaves estrangeiras ou outras restrições.
Por exemplo, no AdventureWorks banco de dados, não podemos excluir linhas da ProductCategory tabela porque ProductCategoryID é especificado como uma chave estrangeira nessa tabela.
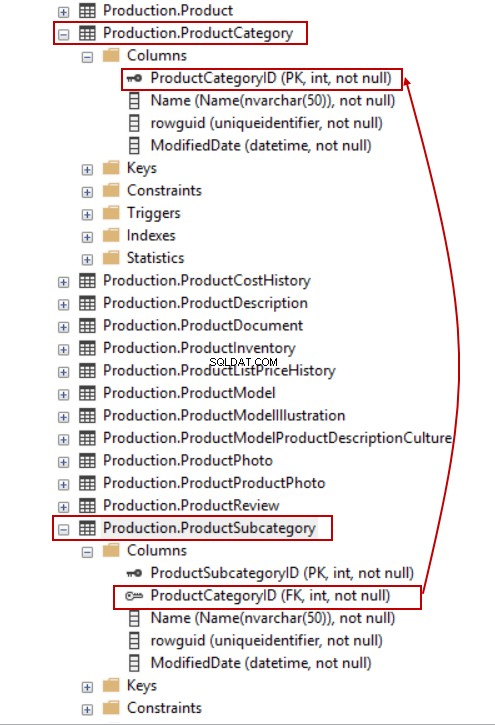
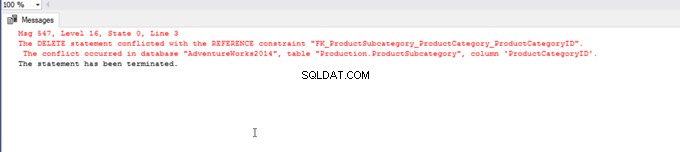
Vamos tentar excluir uma linha da ProductCategory table – sem dúvida, nos depararemos com o seguinte erro:
DELETE FROM [Production].[ProductCategory]
WHERE ProductCategoryID=1
Conclusão
Assim, exploramos as operações CRUD em SQL. As instruções INSERT, SELECT, UPDATE e DELETE são as funções básicas do banco de dados SQL, e você precisa dominá-las se quiser aprender a programação de banco de dados SQL. A teoria CRUD pode ser um bom ponto de partida, e muita prática o ajudará a se tornar um especialista.