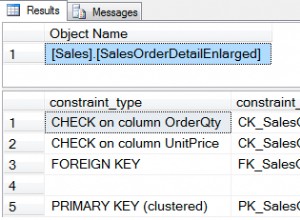
Em todos os principais produtos RDBMS, Chave primária em restrições SQL tem um papel vital. Eles identificam os registros presentes em uma tabela de forma exclusiva. Portanto, devemos escolher o servidor de Chaves Primárias com cuidado durante o design da tabela para melhorar o desempenho.
Neste artigo, aprenderemos o que é uma restrição de chave primária. Além disso, veremos como criar, modificar ou descartar restrições de Chaves Primárias.
Restrições do SQL Server
No SQL Server, Restrições são regras que regulam a entrada dos dados nas colunas necessárias. As restrições impõem a precisão dos dados e como esses dados atendem aos requisitos de negócios. Além disso, eles tornam os dados confiáveis para os usuários finais. É por isso que é fundamental identificar as Restrições corretas durante a fase de design do banco de dados ou esquema de tabela.
O SQL Server oferece suporte aos seguintes tipos de restrição para impor a integridade dos dados:
Restrições de chave primária são criados em uma única coluna ou combinação de colunas para impor a exclusividade dos registros e identificar os registros mais rapidamente. As colunas envolvidas não devem conter valores NULL. Portanto, a propriedade NOT NULL deve ser definida nas colunas.
Restrições de chave estrangeira são criados em uma única coluna ou combinação de colunas para criar um relacionamento entre duas tabelas e impor os dados presentes em uma tabela a outra. Idealmente, as colunas da tabela onde precisamos impor os dados com restrições de chave estrangeira referem-se à tabela de origem com uma restrição de chave primária em SQL ou chave única. Em outras palavras, apenas os registros disponíveis nas restrições de Chave Primária ou Única da tabela Origem podem ser inseridos ou atualizados na tabela Destino.
Restrições de chave exclusivas são criados em uma única coluna ou combinação de colunas para impor exclusividade nos dados da coluna. Eles são semelhantes às restrições de chave primária com uma única alteração. A diferença entre as restrições de chave primária e de chave exclusiva é que a última pode ser criada em Nullable colunas e permitir um registro de valor NULL em sua coluna.
Verificar restrições são criados em uma única coluna ou combinação de colunas, restringindo os valores de dados aceitos para as colunas envolvidas por meio de uma expressão lógica. Há uma diferença entre Chave Estrangeira e Restrições de Verificação. A chave estrangeira reforça a integridade dos dados verificando os dados da chave primária ou exclusiva de outra tabela. No entanto, a restrição de verificação faz isso usando uma expressão lógica.
Agora, vamos passar pelas Restrições de Chave Primária.
Restrição de chave primária
A restrição de chave primária impõe exclusividade em uma única coluna ou combinação de colunas sem nenhum valor NULL dentro das colunas envolvidas.
Para impor a exclusividade, o SQL Server cria um índice clusterizado exclusivo nas colunas em que as Chaves Primárias foram criadas. Se houver índices clusterizados existentes, o SQL Server criará um índice exclusivo não clusterizado na tabela para a chave primária.
Vamos ver como criamos, modificamos, descartamos, desabilitamos ou habilitamos chaves primárias em uma tabela usando scripts T-SQL.
Criar uma chave primária
Podemos criar chaves primárias em uma tabela durante a criação da tabela ou depois disso. A sintaxe varia um pouco para esses cenários.
Criação da chave primária durante a criação da tabela
A sintaxe está abaixo:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Vamos criar uma tabela chamada Funcionários em Recursos Humanos esquema para fins de teste com o script abaixo:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
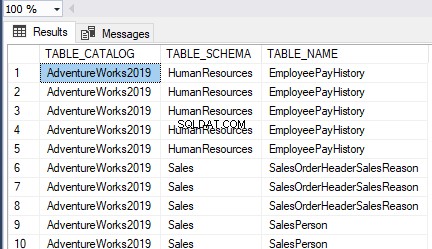
Criamos com sucesso o HumanResources.Employees tabela no AdventureWorks base de dados:
Podemos ver que o índice clusterizado foi criado na tabela correspondente ao nome da Chave Primária, conforme destacado acima.
Vamos descartar a tabela usando o script abaixo e tentar novamente com a nova sintaxe.
DROP TABLE HumanResources.EmployeesPara criar a chave primária no SQL em uma tabela com o nome da chave primária definida pelo usuário PK_Employees , use a sintaxe abaixo:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
Criamos o HumanResources.Employees tabela com o nome da chave primária PK_Employees :
Criação da chave primária após a criação da tabela
Às vezes, desenvolvedores ou DBAs esquecem as Chaves Primárias e criam tabelas sem elas. Mas é possível criar uma chave primária em tabelas existentes.
Vamos abandonar o HumanResources.Employees table e recrie-o usando o script abaixo:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
Quando você executa este script com sucesso, podemos ver o HumanResources.Employees tabela criada sem nenhuma chave primária ou índice:

Para criar uma chave primária chamada PK_Employees nesta tabela, use a sintaxe abaixo:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
A execução deste script cria a chave primária em nossa tabela:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Criação de chave primária em várias colunas
Em nossos exemplos, criamos Chaves Primárias em colunas únicas. Se quisermos criar chaves primárias em várias colunas, precisamos de uma sintaxe diferente.
Para adicionar várias colunas como parte da Chave Primária, precisamos simplesmente adicionar valores separados por vírgula dos nomes das colunas que devem fazer parte da Chave Primária.
Chave primária durante a criação da tabela
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Chave primária após a criação da tabela
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Retire a chave primária
Para descartar a chave primária, usamos a sintaxe abaixo. Não importa se a Chave Primária estava em uma ou várias colunas.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
Para descartar a restrição de chave primária em HumanResources.Employees tabela, use o script abaixo:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
Descartar a chave primária remove as chaves primárias e os índices clusterizados ou não clusterizados criados junto com a criação da chave primária:
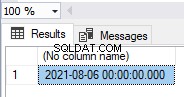
Modificar a chave primária
No SQL Server, não há comandos diretos para modificar as chaves primárias. Precisamos descartar uma chave primária existente e recriá-la com as modificações necessárias. Portanto, as etapas para modificar a chave primária são:
- Retire uma chave primária existente.
- Crie novas chaves primárias com as alterações necessárias.
Desativar/ativar chave primária
Ao executar o carregamento em massa em uma tabela com muitos registros, desative a Chave Primária e ative-a novamente para obter melhor desempenho. Os passos estão abaixo:
Desative a chave primária existente com a sintaxe abaixo:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;Para desabilitar a chave primária no HumanResources.Employees tabela, o script é:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Habilite as Chaves Primárias existentes que estão no estado desabilitado. Precisamos RECONSTRUIR o índice usando a sintaxe abaixo:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;Para habilitar a chave primária no HumanResources.Employees tabela, use o seguinte script:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
Os mitos sobre a chave primária
Muitas pessoas ficam confusas com os mitos abaixo relacionados às Chaves Primárias no SQL Server.
- A tabela com chave primária não é uma tabela heap
- As chaves primárias têm o índice agrupado e os dados classificados em ordem física
Vamos esclarecê-los.
A tabela com chave primária não é uma tabela de pilha
Antes de nos aprofundarmos, vamos revisar a definição da Chave Primária e da Tabela Heap.
A chave primária cria um índice clusterizado em uma tabela se não houver outros índices clusterizados disponíveis lá. Uma Tabela sem um Índice Agrupado será uma Tabela Heap.
Com base nessas definições, podemos entender que a chave primária cria um índice clusterizado somente se não houver outros índices clusterizados na tabela. Se houver índices clusterizados existentes, a criação da chave primária criará um índice não clusterizado na tabela correspondente à chave primária.
Vamos verificar isso descartando o HumanResources.Employees Tabela e recriá-la:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
Podemos especificar a opção de índice NONCLUSTERED para a Chave Primária (veja acima). Uma tabela foi criada com um índice exclusivo e não agrupado para a chave PK_Employees principal .
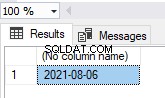
Portanto, essa tabela é uma tabela de heap, embora tenha uma chave primária.
Vamos ver se o SQL Server pode criar um índice não clusterizado para a Chave Primária se não especificarmos a palavra-chave Não clusterizado durante a criação da chave primária. Use o script abaixo:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
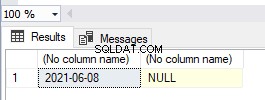
Aqui criamos um índice clusterizado separadamente antes da criação da Chave Primária. E uma tabela pode ter apenas um índice clusterizado. Portanto, o SQL Server criou a chave primária como um índice exclusivo e não clusterizado. No momento, a tabela não é uma tabela Heap porque possui um índice clusterizado.
Se eu mudar de ideia e descartar o índice clusterizado no First_Name e Sobrenome colunas usando o script abaixo:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
Eliminamos o índice clusterizado com sucesso. Os HumanResources.Employees table é uma tabela Heap embora tenhamos uma Chave Primária disponível na tabela:
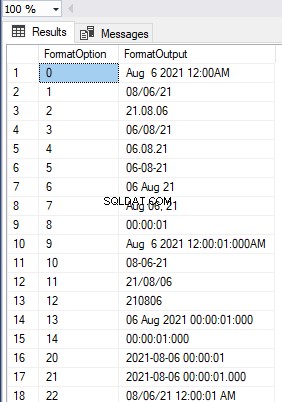
Isso elimina o mito de que uma tabela com uma chave primária pode ser uma tabela Heap se não houver índices clusterizados disponíveis na tabela.
A chave primária terá um índice clusterizado e dados classificados em ordem física
Como aprendemos com o exemplo anterior, uma chave primária em SQL pode ter um índice não clusterizado. Nesse caso, os registros não seriam classificados em ordem física.
Vamos verificar a tabela com o índice clusterizado em uma chave primária. Vamos verificar se ele classifica os registros em ordem física.
Recrie o HumanResources.Employees tabela com colunas mínimas e a propriedade IDENTITY removida para o Employee_ID coluna:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Agora que criamos a tabela sem a chave primária ou um índice clusterizado, podemos INSERT 3 registros em uma ordem não classificada para o Employee_Id coluna:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Vamos selecionar entre HumanResources.Employees tabela:
SELECT *
FROM HumanResources.Employees
Podemos ver os registros buscados na mesma ordem que os registros inseridos da tabela Heap neste momento.
Vamos criar uma Chave Primária nesta tabela Heap e ver se ela tem algum impacto na instrução SELECT:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

Após a criação da chave primária, podemos ver que a instrução SELECT buscou registros em ordem crescente do Employee_Id (coluna Chave Primária). É devido ao índice clusterizado em Employee_Id .
Se uma Chave Primária for criada com a opção não agrupada, os dados da tabela não serão classificados com base na coluna Chave Primária.
Se o comprimento de um único registro em uma tabela exceder 4.030 bytes, apenas um registro poderá caber em uma página. O índice clusterizado garante que as páginas estejam em ordem física.
Uma página é uma unidade fundamental de armazenamento em arquivos de dados do SQL Server com tamanho de 8 KB (8192 bytes). Apenas 8060 bytes dessa unidade são utilizáveis para armazenamento de dados. O valor restante é para cabeçalhos de página e outros internos.
Dicas para escolher colunas de chave primária
- Colunas de tipo de dados inteiros são mais adequadas para colunas de chave primária, pois ocupam tamanhos de armazenamento menores e podem ajudar a recuperar os dados mais rapidamente.
- Como as colunas de chave primária têm um índice clusterizado por padrão, use a opção IDENTITY em colunas de tipo de dados inteiros para gerar novos valores em ordem incremental.
- Em vez de criar uma chave primária em várias colunas, crie uma nova coluna inteira com a propriedade IDENTITY definida. Além disso, crie um índice exclusivo em várias colunas que foram originalmente identificadas para um melhor desempenho.
- Tente evitar colunas com tipo de dados string como varchar, nvarchar etc. Não podemos garantir o incremento sequencial de dados nesses tipos de dados. Isso pode afetar o desempenho do INSERT nessas colunas.
- Escolha as colunas em que os valores não serão atualizados como chaves primárias. Por exemplo, se o valor da chave primária puder ser alterado de 5 para 1.000, a árvore B associada ao índice clusterizado precisará ser atualizada, resultando em pequenas perdas de desempenho.
- Se as colunas de tipo de dados de string precisarem ser escolhidas como colunas de chave primária, certifique-se de que o comprimento das colunas de tipo de dados varchar ou nvarchar permaneça pequeno para melhor desempenho.
Conclusão
Passamos pelo básico das Restrições disponíveis no SQL Server. Examinamos detalhadamente as restrições de chave primária e aprendemos como criar, descartar, modificar, desabilitar e reconstruir chaves primárias. Além disso, esclarecemos alguns mitos populares sobre chaves primárias com exemplos.
Fique ligado no próximo artigo!