A estratégia de indexação de tabela é uma das chaves de otimização e ajuste de desempenho mais importantes. No SQL Server, os índices (tanto clusterizados quanto não clusterizados) são criados usando uma estrutura de árvore B, na qual cada página atua como um nó de lista duplamente vinculado, contendo informações sobre as páginas anterior e seguinte. Essa estrutura de árvore B, chamada Forward Scan, facilita a leitura das linhas do índice ao varrer ou buscar suas páginas do início ao fim. Embora a varredura direta seja o método de varredura de índice padrão e bastante conhecido, o SQL Server nos fornece a capacidade de varrer as linhas de índice dentro da estrutura da árvore B do final ao início. Essa habilidade é chamada de Backward Scan. Neste artigo, veremos como isso acontece e quais são os prós e contras do método de digitalização para trás.
O SQL Server nos fornece a capacidade de ler dados do índice da tabela varrendo os nós da estrutura da árvore B do índice do início ao fim usando o método Forward Scan ou lendo os nós da estrutura da árvore B do fim ao início usando o Método de digitalização para trás. Como o nome indica, a varredura para trás é executada durante a leitura oposta à ordem da coluna incluída no índice, que é executada com a opção DESC na instrução de classificação ORDER BY T-SQL, que especifica a direção da operação de varredura.
Em situações específicas, o SQL Server Engine descobre que a leitura dos dados de índice do fim ao início com o método Backward scan é mais rápida do que a leitura em sua ordem normal com o método Forward scan, que pode exigir um processo de classificação caro pelo SQL Motor. Esses casos incluem o uso da função agregada MAX() e situações em que a classificação do resultado da consulta é oposta à ordem do índice. A principal desvantagem do método Backward scan é que o SQL Server Query Optimizer sempre optará por executá-lo usando a execução do plano serial, sem poder se beneficiar dos planos de execução paralela.
Suponha que temos a tabela a seguir que conterá informações sobre os funcionários da empresa. A tabela pode ser criada usando a instrução CREATE TABLE T-SQL abaixo:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Após criar a tabela, vamos preenchê-la com 10 mil registros fictícios, utilizando a instrução INSERT abaixo:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Se executarmos a instrução SELECT abaixo para recuperar dados da tabela criada anteriormente, as linhas serão classificadas de acordo com os valores da coluna ID em ordem crescente, ou seja, a mesma ordem do índice clusterizado:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
Em seguida, verificando o plano de execução dessa consulta, será realizada uma varredura no índice clusterizado para obter os dados classificados do índice conforme mostrado no plano de execução abaixo:
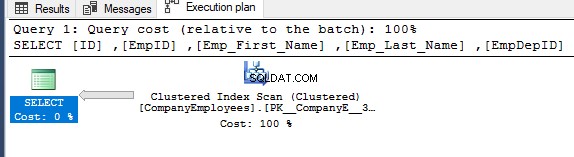
Para obter a direção da varredura que é executada no índice clusterizado, clique com o botão direito do mouse no nó de varredura do índice para navegar pelas propriedades do nó. Nas propriedades do nó Clustered Index Scan, a propriedade Scan Direction exibirá a direção da varredura que é executada no índice dentro dessa consulta, que é Forward Scan, conforme mostrado no instantâneo abaixo:
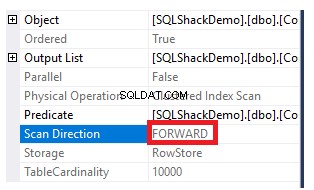
A direção de varredura do índice também pode ser recuperada do plano de execução XML da propriedade ScanDirection no nó IndexScan, conforme mostrado abaixo:

Suponha que precisamos recuperar o valor máximo de ID da tabela CompanyEmployees criada anteriormente, usando a consulta T-SQL abaixo:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Em seguida, revise o plano de execução gerado a partir da execução dessa consulta. Você verá que uma verificação será realizada no índice clusterizado conforme mostrado no plano de execução abaixo:
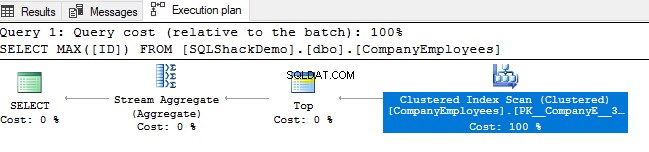
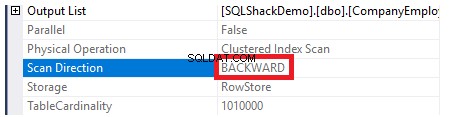
Para verificar a direção da verificação de índice, navegaremos pelas propriedades do nó Verificação de índice clusterizado. O resultado nos mostrará que, o SQL Server Engine prefere varrer o índice clusterizado do final para o início, o que será mais rápido neste caso, para obter o valor máximo da coluna ID, devido ao fato de que o index já está ordenado de acordo com a coluna ID, conforme mostrado abaixo:
Além disso, se tentarmos recuperar os dados da tabela criada anteriormente usando a seguinte instrução SELECT, os registros serão classificados de acordo com os valores da coluna ID, mas desta vez, em oposição à ordem do índice clusterizado, especificando a opção de classificação DESC no ORDER Cláusula BY mostrada abaixo:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
Se você verificar o plano de execução gerado após a execução da consulta SELECT anterior, verá que será realizada uma varredura no índice clusterizado para obter os registros solicitados da tabela, conforme mostrado abaixo:
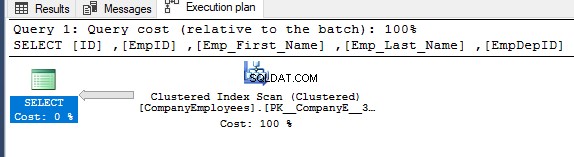
As propriedades do nó Clustered Index Scan mostrarão que a direção da verificação que o SQL Server Engine prefere fazer é a direção Backward Scan, que é mais rápida neste caso, devido à classificação dos dados oposta à classificação real do índice clusterizado, levando em consideração que o índice já está ordenado em ordem crescente de acordo com a coluna ID, conforme mostrado abaixo:
Comparação de desempenho
Suponha que temos as instruções SELECT abaixo que recuperam informações sobre todos os funcionários que foram contratados a partir de 2010, duas vezes; na primeira vez, o conjunto de resultados retornado será classificado em ordem crescente de acordo com os valores da coluna de ID e, na segunda vez, o conjunto de resultados retornado será classificado em ordem decrescente de acordo com os valores da coluna de ID usando as instruções T-SQL abaixo:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
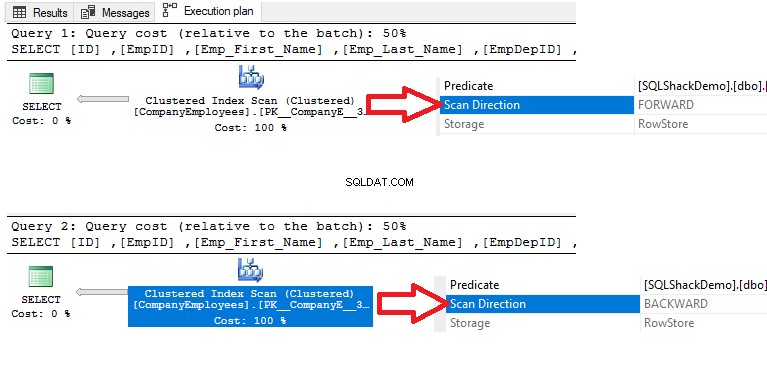
Verificando os planos de execução que são gerados pela execução das duas consultas SELECT, o resultado mostrará que uma varredura será realizada no índice clusterizado nas duas consultas para recuperar os dados, mas a direção da varredura na primeira consulta será Forward Scan devido à classificação de dados ASC, e Backward Scan na segunda consulta devido ao uso da classificação de dados DESC, para substituir a necessidade de reordenar os dados novamente, conforme mostrado abaixo:
Além disso, se verificarmos as estatísticas de execução de IO e TIME das duas consultas, veremos que ambas as consultas realizam as mesmas operações de IO e consomem valores próximos da execução e do tempo de CPU.
Esses valores nos mostram o quão inteligente é o SQL Server Engine ao escolher a direção de varredura de índice mais adequada e mais rápida para recuperar dados para o usuário, que é Forward Scan no primeiro caso e Backward Scan no segundo caso, conforme fica claro nas estatísticas abaixo :

Vamos visitar o exemplo anterior do MAX novamente. Suponha que precisamos recuperar o ID máximo dos funcionários que foram contratados em 2010 e posteriores. Para isso, usaremos as seguintes instruções SELECT que classificarão os dados lidos de acordo com o valor da coluna ID com a ordenação ASC na primeira consulta e com a ordenação DESC na segunda consulta:
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
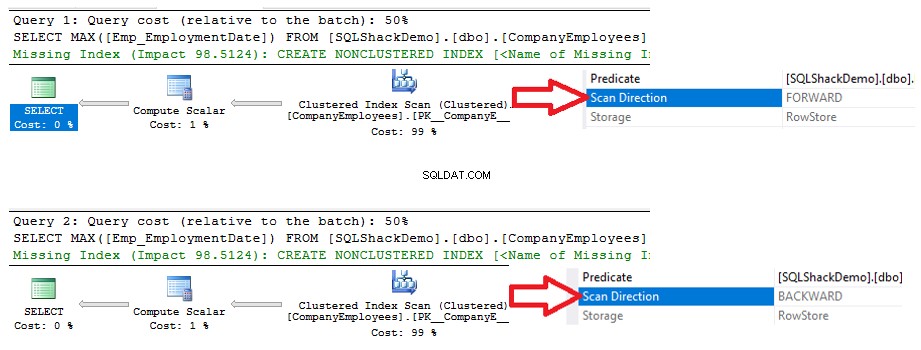
Você verá nos planos de execução gerados a partir da execução das duas instruções SELECT, que ambas as consultas realizarão uma operação de varredura no índice clusterizado para recuperar o valor máximo de ID, mas em direções de varredura diferentes; Forward Scan na primeira consulta e Backward Scan na segunda consulta, devido às opções de classificação ASC e DESC, conforme mostrado abaixo:
As estatísticas de E/S geradas pelas duas consultas não mostrarão diferença entre as duas direções de varredura. Mas as estatísticas TIME mostram uma grande diferença entre calcular o ID máximo das linhas quando essas linhas são varridas do início ao fim usando o método Forward Scan e varrer do fim ao início usando o método Backward Scan. Fica claro a partir do resultado abaixo que o método Backward Scan é o método de digitalização ideal para obter o valor máximo de ID:
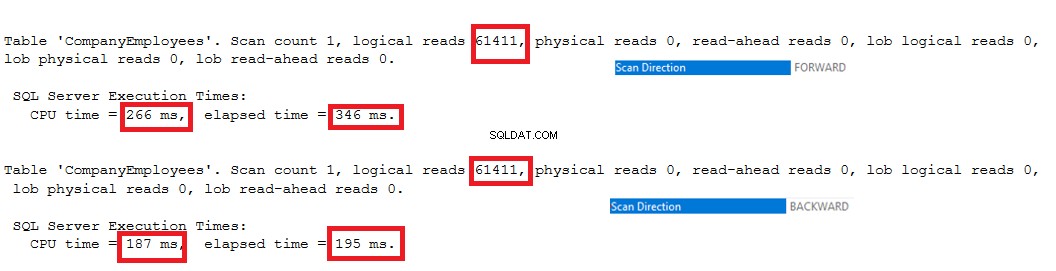
Otimização de desempenho
Como mencionei no início deste artigo, a indexação de consultas é a chave mais importante no processo de ajuste e otimização de desempenho. Na consulta anterior, se organizarmos para adicionar um índice não clusterizado na coluna EmploymentDate da tabela CompanyEmployees, usando a instrução CREATE INDEX T-SQL abaixo:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Verificando os planos de execução gerados após a execução das duas consultas, você verá que uma busca será realizada no índice não clusterizado recém-criado, e ambas as consultas irão varrer o índice do início ao fim usando o método Forward Scan, sem a necessidade para realizar um Backward Scan para acelerar a recuperação de dados, embora tenhamos usado a opção de classificação DESC na segunda consulta. Isso ocorreu devido à busca direta do índice sem a necessidade de realizar uma varredura completa do índice, conforme mostrado na comparação dos planos de execução abaixo:
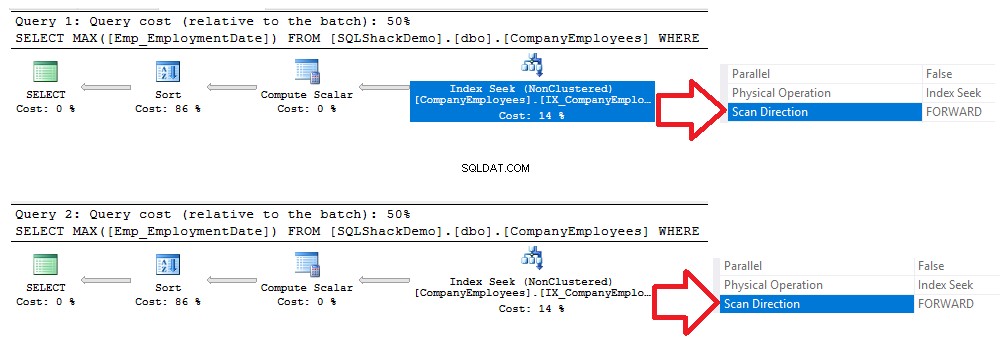
O mesmo resultado pode ser derivado das estatísticas IO e TIME geradas das duas consultas anteriores, onde as duas consultas consumirão a mesma quantidade de tempo de execução, operações de CPU e IO, com uma diferença muito pequena, conforme mostrado no instantâneo de estatísticas abaixo :

Links úteis:
- Índices agrupados e não agrupados descritos
- Criar índices não clusterizados
- Ajuste de desempenho do SQL Server:verificação para trás de um índice
Ferramenta útil:
dbForge Index Manager – suplemento SSMS útil para analisar o status de índices SQL e corrigir problemas com fragmentação de índice.



