Na Parte I, apresentamos uma estrutura de alta disponibilidade (HA) para hospedagem MySQL e discutimos vários componentes e suas funcionalidades. Agora, na Parte II, discutiremos os detalhes da replicação semissíncrona do MySQL e as definições de configuração relacionadas que nos ajudam a garantir a redundância e a consistência dos dados em nossa configuração de alta disponibilidade. Certifique-se de voltar para a Parte III, onde revisaremos vários cenários de falha que podem surgir e a maneira como a estrutura responde e se recupera dessas condições.
O que é replicação semisíncrona do MySQL?
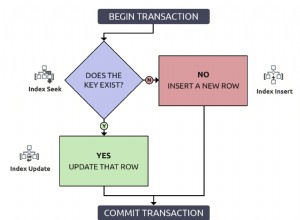
De forma simples, em uma configuração de replicação semisíncrona do MySQL, o mestre confirma transações para o mecanismo de armazenamento somente após receber confirmação de pelo menos um dos escravos. Os escravos forneceriam reconhecimento somente após os eventos serem recebidos e copiados para os logs de retransmissão e também liberados para o disco. Isso garante que, para todas as transações confirmadas e retornadas ao cliente, os dados existam em pelo menos 2 nós. O termo ‘semi’ em semisíncrono (replicação) é devido ao fato de que o mestre confirma as transações assim que os eventos são recebidos e liberados para o log de retransmissão, mas não necessariamente comprometidos com os arquivos de dados no escravo. Isso contrasta com a replicação totalmente síncrona, em que a transação teria sido confirmada no escravo e no mestre antes que a sessão retornasse ao cliente.
A replicação semisíncrona, que está disponível nativamente no MySQL, ajuda a estrutura de alta disponibilidade a garantir consistência e redundância de dados para transações confirmadas. No caso de uma falha do mestre, todas as transações confirmadas no mestre teriam sido replicadas para pelo menos um dos escravos (salvos nos logs de retransmissão). Como resultado, o failover para esse escravo seria sem perdas porque o escravo está atualizado (após os logs de retransmissão do escravo serem totalmente drenados).
Configurações relacionadas a replicação e semissíncronas
Vamos discutir algumas das principais configurações do MySQL usadas para garantir o comportamento ideal para alta disponibilidade e consistência de dados em nossa estrutura.
Gerenciando a velocidade de execução dos escravos
A primeira consideração é lidar com o comportamento 'semi' da replicação semi-síncrona, que garante apenas que os dados foram recebidos e liberados para os logs de retransmissão pela thread de E/S do slave, mas não necessariamente confirmado pelo thread SQL. Por padrão, o thread SQL em um escravo MySQL é single-thread e não será capaz de acompanhar o master que é multi-thread. O impacto óbvio disso é que, no caso de uma falha do mestre, o escravo não estará atualizado, pois seu thread SQL ainda está processando os eventos no log de retransmissão. Isso atrasará o processo de failover, pois nossa estrutura espera que o escravo esteja totalmente atualizado antes de poder ser promovido. Isso é necessário para preservar a consistência dos dados. Para resolver esse problema, habilitamos escravos multithread com a opção slave_parallel_workers para definir o número de threads SQL paralelos para processar eventos nos logs de retransmissão.
Além disso, definimos as configurações abaixo que garantem que o escravo não entre em nenhum estado em que o mestre não estava:
- slave-parallel-type =LOGICAL_CLOCK
- slave_preserve_commit_order =1
Isso nos fornece uma consistência de dados mais forte. Com essas configurações, poderemos obter melhor paralelização e velocidade no escravo, mas se houver muitas threads paralelas, a sobrecarga envolvida na coordenação entre as threads também aumentará e, infelizmente, poderá compensar os benefícios.
Outra configuração que podemos usar para aumentar a eficiência da execução paralela nos escravos é ajustar binlog_group_commit_sync_delay no mestre. Ao definir isso no mestre, as entradas de log binário no mestre e, portanto, as entradas de log de retransmissão no escravo terão lotes de transações que podem ser processadas paralelamente pelos threads SQL. Isso é explicado em detalhes no blog de J-F Gagné, onde ele se refere a esse comportamento como 'retardar o mestre para acelerar o escravo' .
Se você estiver gerenciando suas implantações MySQL por meio do console do ScaleGrid, poderá monitorar continuamente e receber alertas em tempo real sobre o atraso de replicação dos escravos. Também permite ajustar dinamicamente os parâmetros acima para garantir que os escravos estejam trabalhando lado a lado com o mestre, minimizando assim o tempo envolvido em um processo de failover.
Estrutura de alta disponibilidade do MySQL explicada - Parte IIClique para Tweet
Opções importantes de replicação semissíncrona
A replicação semissíncrona do MySQL, por design, pode retornar ao modo assíncrono com base nas configurações de tempo limite de confirmação do escravo ou com base no número de escravos com capacidade semissíncrona disponíveis a qualquer momento. O modo assíncrono, por definição, não fornece garantias de que as transações confirmadas sejam replicadas para o escravo e, portanto, uma perda do mestre levaria à perda dos dados que não foram replicados. O design padrão da estrutura ScaleGrid HA é evitar voltar ao modo assíncrono. Vamos rever as configurações que influenciam esse comportamento.
-
rpl_semi_sync_master_wait_for_slave_count
Esta opção é usada para configurar o número de escravos que devem enviar uma confirmação antes que um mestre semissíncrono possa confirmar a transação. Na configuração mestre-escravo de 3 nós, definimos isso como 1 para que sempre tenhamos a garantia de que os dados estão disponíveis em pelo menos um escravo, evitando qualquer impacto no desempenho envolvido na espera pelo reconhecimento de ambos os escravos.
-
rpl_semi_sync_master_timeout
Esta opção é usada para configurar a quantidade de tempo que um mestre semissíncrono espera pela confirmação de um escravo antes de retornar ao modo assíncrono. Definimos isso como um valor de tempo limite relativamente alto para que não haja fallback para o modo assíncrono.
Como estamos operando com 2 escravos e o rpl_semi_sync_master_wait_for_slave_count está definido como 1, notamos que pelo menos um dos escravos reconhece dentro de um período de tempo razoável e o mestre não alterna para o modo assíncrono durante interrupções temporárias da rede.
-
rpl_semi_sync_master_wait_no_slave
Isso controla se o mestre espera que o período de tempo limite configurado por rpl_semi_sync_master_timeout expire, mesmo que a contagem de escravos caia para menos do que o número de escravos configurado por rpl_semi_sync_master_wait_for_slave_count durante o período de tempo limite. Mantemos o valor padrão de ON para que o mestre não retorne à replicação assíncrona.
Impacto da perda de todos os escravos semissíncronos
Como vimos acima, nossa estrutura impede que o mestre alterne para a replicação assíncrona se todos os escravos ficarem inativos ou se tornarem inacessíveis pelo mestre. O impacto direto disso é que as gravações ficam paralisadas no mestre, afetando a disponibilidade do serviço. Isso é essencialmente como descrito pelo teorema CAP sobre as limitações de qualquer sistema distribuído. O teorema afirma que, na presença de uma partição de rede, teremos que escolher entre disponibilidade ou consistência, mas não ambas. A partição de rede, neste caso, pode ser considerada como escravos MySQL desconectados do mestre porque estão inativos ou inacessíveis.
Nosso objetivo de consistência é garantir que, para todas as transações confirmadas, os dados estejam disponíveis em pelo menos 2 nós. Como resultado, nesses casos, a estrutura ScaleGrid HA favorece a consistência sobre a disponibilidade. Outras gravações não serão aceitas de clientes, embora o MySQL master ainda esteja atendendo às solicitações de leitura. Esta é uma decisão de design consciente que tomamos como o comportamento padrão que é, obviamente, configurável com base nos requisitos do aplicativo.
Certifique-se de assinar o blog ScaleGrid para não perder a Parte III, onde discutiremos mais cenários de falha e capacidades de recuperação da estrutura MySQL HA . Fique atento!!