Este artigo explica o processo de implantação passo a passo do envio de log do SQL Server. É a solução de recuperação de desastres em nível de banco de dados que é fácil de configurar e manter.
O envio de logs envolve três etapas:
- Gere o backup de log no banco de dados primário.
- Copie o backup para o local da rede ou para o diretório específico no servidor secundário.
- Restaure o backup de log no servidor secundário.
A tecnologia de envio de logs executa as etapas descritas acima usando trabalhos de agente do SQL Server. Durante o processo de configuração, o assistente de envio de logs cria esses trabalhos nos servidores primário e secundário.
O envio de logs pode estar em dois modos operacionais.
- Modo de restauração . A Tarefa SQL restaura os backups do log de transações no banco de dados secundário. O estado do banco de dados é RESTORING , e não está acessível.
- Modo de espera . A Tarefa SQL restaura os backups do log de transações no banco de dados secundário, mas o banco de dados pode permanecer no modo somente leitura. Portanto, os usuários podem realizar operações de leitura nele. Por esta opção, podemos descarregar o aplicativo de relatórios.
Nota:o modo Standby tem uma desvantagem:o banco de dados não está disponível durante a execução da tarefa de restauração. Todos os usuários conectados ao banco de dados devem se desconectar durante esse processo. Caso contrário, a tarefa de restauração pode ser atrasada .
A principal desvantagem do envio de logs é a ausência de suporte a failover automático. Para executar um failover, você deve executar as seguintes etapas:
- Gere um backup do final do log e copie-o em um servidor de banco de dados secundário.
- Interrompa todos os trabalhos de envio de logs no servidor principal.
- Restaure o log no servidor secundário.
Esse processo pode atrasar a disponibilidade do banco de dados secundário.
Agora, passamos para o exame passo a passo do processo de implantação. Antes de tudo, preparamos a estação de trabalho configurando-a da seguinte maneira:
| Nome do servidor | Função |
| SQL01 | Servidor principal |
| SQL02 | Servidor secundário |
| iSCSI\SQL2017 | Servidor de monitoramento |
| \\domain\Backups de envio de log | Compartilhamento de rede para copiar os backups |
Configurar o servidor principal
O SQL01 atua como um Servidor Principal e o banco de dados. Vamos configurar o envio de logs entre o banco de dados AdventureWorks2017.
Para configurar o envio de logs, conecte-se à instância SQL01:
- Abra o SQL Server Management Studio
- Expandir banco de dados
- Clique com o botão direito do mouse em AdventureWorks2017
- Passe o mouse em Tarefas
- Clique em Logs de transações de envio.
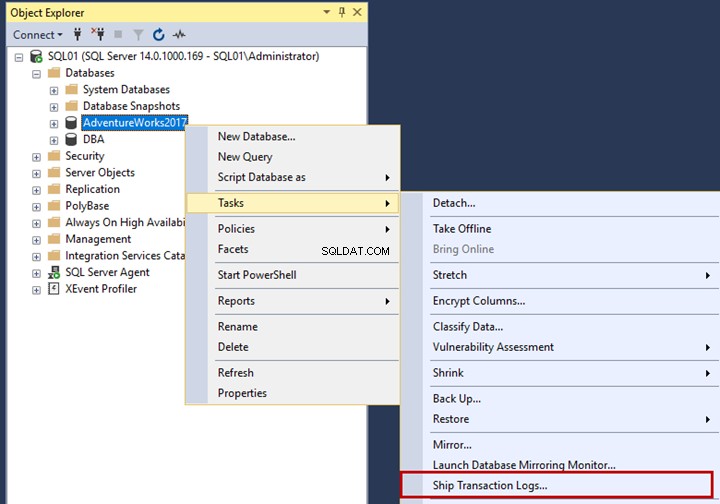
As Propriedades do banco de dados caixa de diálogo é aberta.
Para habilitar o envio de logs, clique em Ativar como banco de dados primário em uma configuração de envio de logs opção.
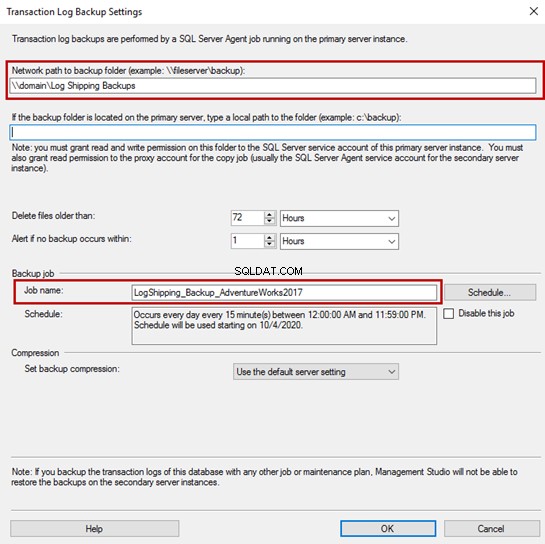
Para configurar o agendamento de backup do log de transações para envio de logs, clique em Configurações de backup .
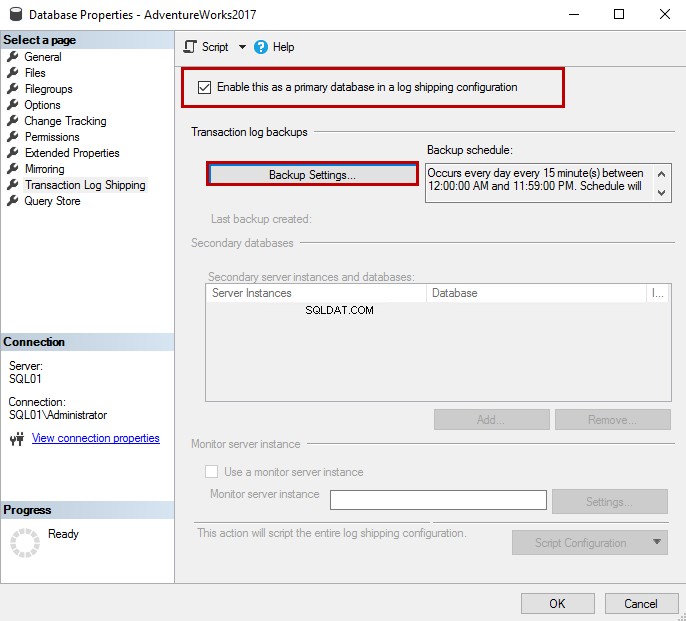
Uma caixa de diálogo, 'Configuração de backup do log de transações' é aberta.
Na caixa de diálogo, especifique o compartilhamento de rede onde você deseja copiar os backups do log de transações – o Caminho da rede para a pasta de backup caixa de texto. Você pode determinar o período de retenção do backup em Excluir arquivos anteriores a indicado na caixa de texto. Se o trabalho de backup falhar ou o arquivo de backup não ocorrer durante o tempo especificado na caixa de texto, o SQL Server emitirá um alerta.
No envio de log, o SQL Server copia os backups do arquivo de log para o compartilhamento de rede. O assistente cria automaticamente um trabalho de backup durante o processo de implantação. Ele faz um agendamento automaticamente também, mas você pode alterá-lo clicando no botão Agendar.
No meu caso, alterei o nome do trabalho de backup para identificá-lo. O nome do trabalho é LogShipping_Backup_AdventureWorks2017 .
Não fiz nenhuma alteração no agendamento do trabalho e nas configurações de compactação de backup.
Configurar o servidor secundário
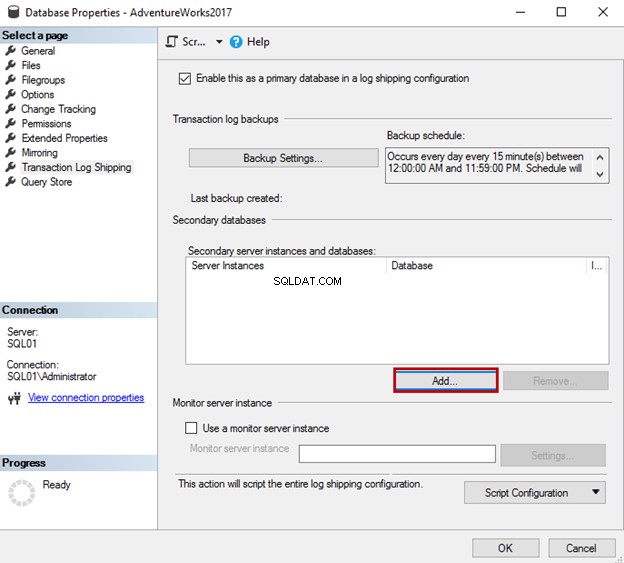
Para adicionar o servidor secundário e o banco de dados, clique em “Adicionar” nas Propriedades do banco de dados caixa de diálogo.
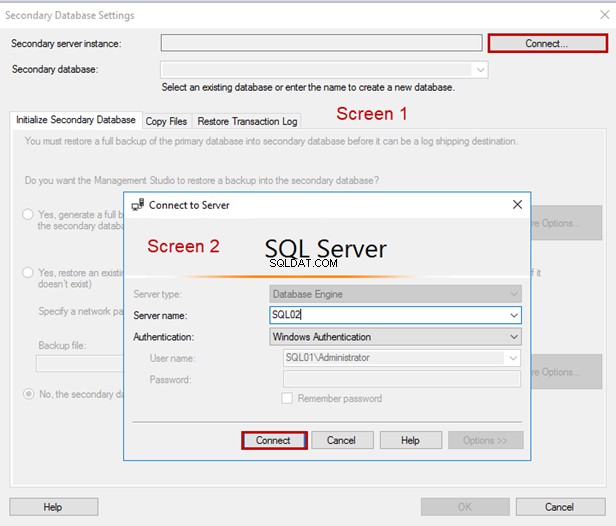
Uma caixa de diálogo chamada Configurações do banco de dados secundário vai abrir. Devemos nos conectar ao servidor de banco de dados secundário. Para isso, clique em “Adicionar”.
Uma caixa de diálogo é aberta. Digite o nome do servidor e clique em Conectar :
Configuração das configurações do banco de dados secundário
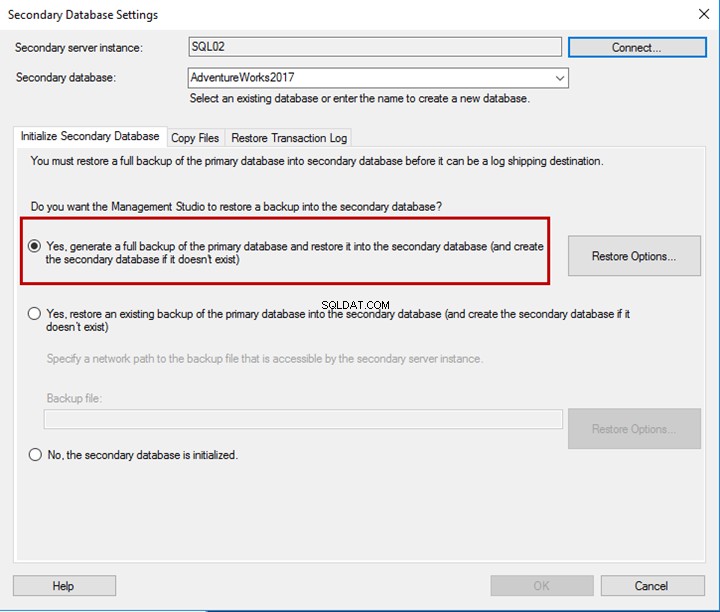
Inicializar banco de dados secundário
Na guia inicializar banco de dados secundário, você pode configurar qualquer uma das três opções a seguir para restaurar o banco de dados:
- Se o banco de dados não existir no servidor secundário, você poderá gerar um backup completo e restaurá-lo no servidor secundário. Nesse cenário, você pode usar a primeira opção.
- Se houver um backup completo do banco de dados gerado por outras tarefas de backup, ou se você já tiver um, poderá restaurá-lo no servidor secundário. Nesse cenário, você pode escolher a segunda opção.
- Se você restaurou o banco de dados secundário com o estado NORECOVERY, você pode escolher a terceira opção.
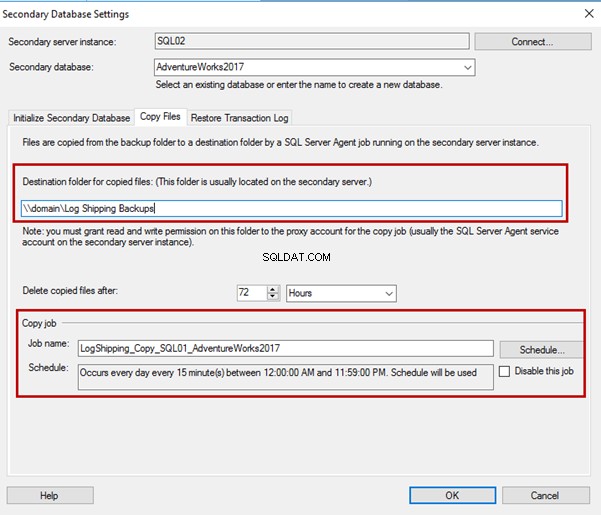
Copiar arquivos
Em Copiar arquivos guia, você pode especificar o diretório de destino para o local dos arquivos de backup copiados. O período de retenção também é definido lá.
O assistente cria um trabalho SQL para copiar arquivos para o diretório de destino. A pasta de destino do backup é \\domain\Log Shipping Backups. O nome do trabalho de cópia é LogShipping_Copy_SQL01_AdventureWorks2017 .
Restaurar registro de transações
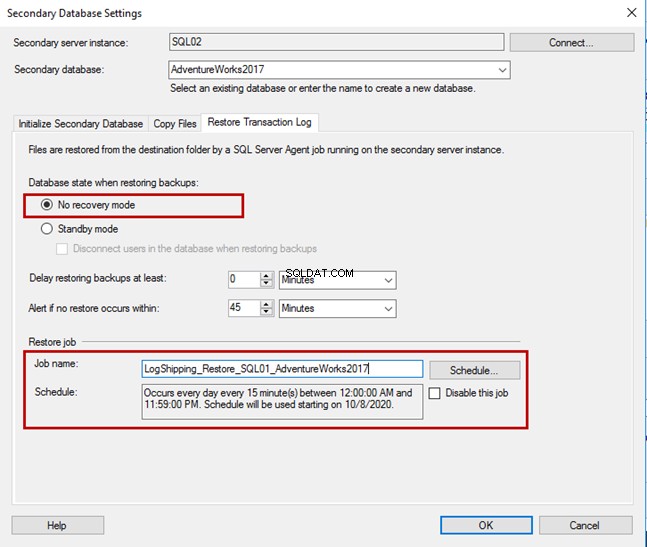
No Registro de transações de restauração guia, você pode especificar o modo de banco de dados. Se você deseja manter o banco de dados no modo somente leitura, selecione Modo de espera ou escolha o Sem modo de recuperação .
Nesta demonstração, mantemos o estado do banco de dados como NORECOVERY. Você pode especificar o atraso na restauração do backup e configurar alertas para backups não restaurados em um intervalo especificado. No nosso caso, não usamos configurações padrão.
O nome da tarefa de restauração é LogShipping_Restore_SQL01_AdventureWorks2017.
Quando a configuração estiver pronta, clique em OK para salvar as alterações.
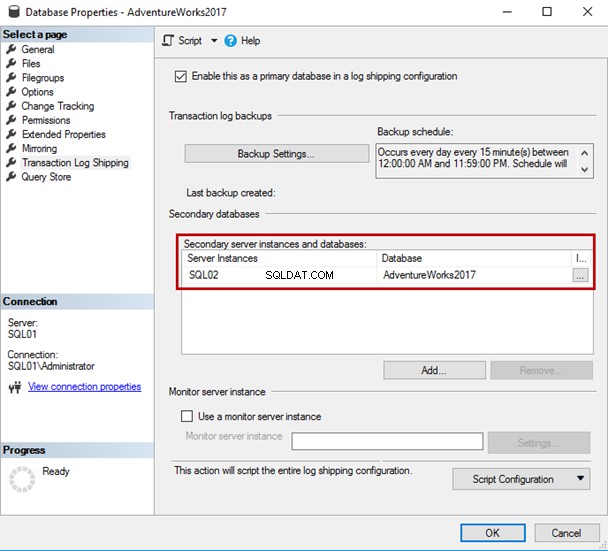
Como você vê, o servidor secundário e o banco de dados foram adicionados em “Instâncias do servidor secundário e grade de bancos de dados ” nas Propriedades do banco de dados tela.
Configurar instância de monitoramento
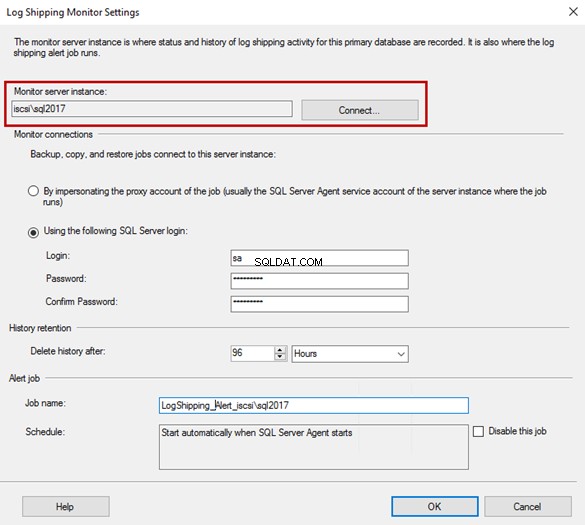
Se você quiser configurar a instância do servidor Monitor, marque Usar uma instância do servidor monitor . Para adicionar a instância do monitor, clique em Configurações .
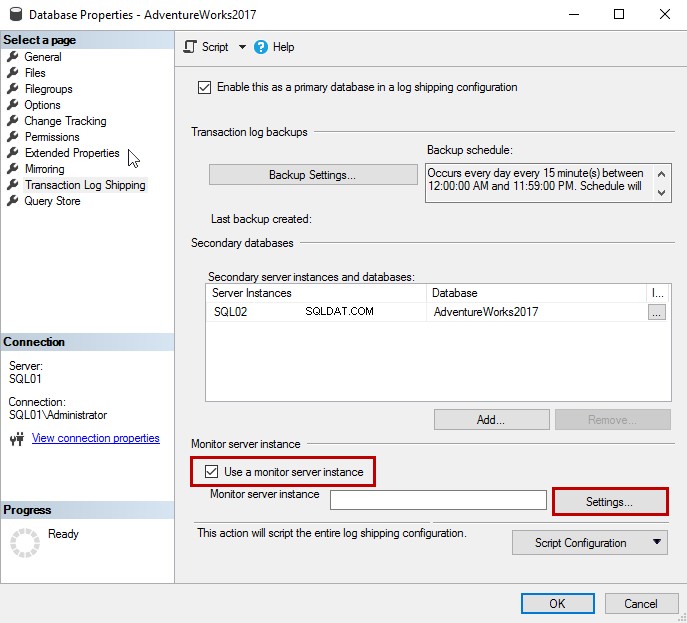
Vamos usar a instância iscsi\SQL2017 como servidor de monitoramento de envio de logs.
Na Configuração do Monitor de envio de registros caixa de diálogo, especifique o nome em Monitorar instância do servidor caixa de texto.
Usamos o sa conta para monitorar o envio de logs. Portanto, você precisa fornecer sa como nome de usuário e senha. Você também pode especificar o período de retenção dos alertas e do histórico de monitoramento.
Aqui, usamos as configurações padrão. O nome da tarefa de alerta é LogShipping_Alert_iscsi\sql2017 .
Clique em OK para salvar a configuração e fechar a caixa de diálogo.
Você pode gerar um script T-SQL para toda a configuração clicando em Configuração de script botão. Copie o script de configuração para a área de transferência ou o arquivo ou abra-o em uma nova janela do editor de consultas.
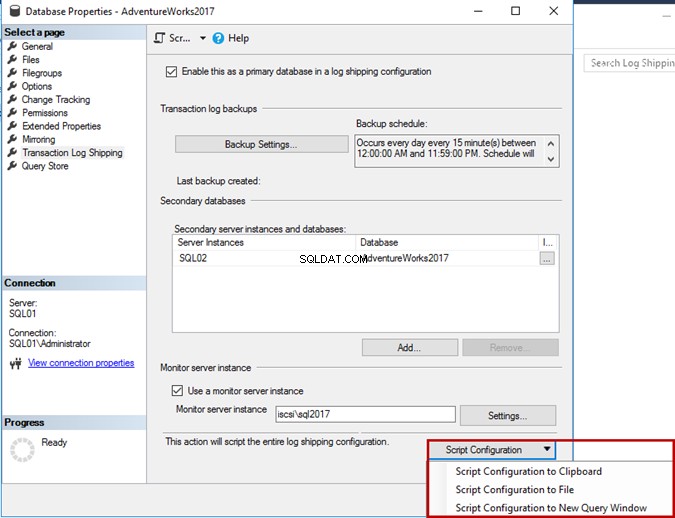
Não queremos roteirizar a ação. Você pode ignorar esta etapa.
Clique em OK para salvar a configuração de envio de logs e o processo será iniciado:
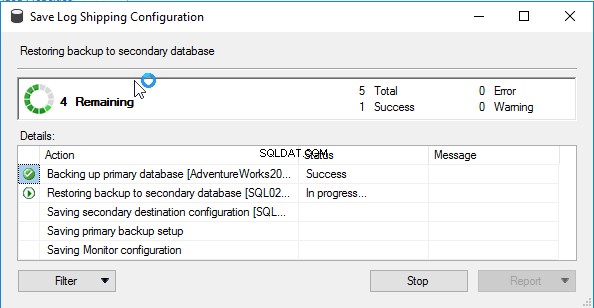
Depois que o envio de logs estiver configurado, você poderá ver a caixa de diálogo de sucesso:
Cenário de failover de teste
USE [AdventureWorks2017]
GO
CREATE TABLE [Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GOExecute a seguinte consulta para inserir dados de demonstração:
insert into [Person]([BusinessEntityID],[PersonType],[NameStyle],[Title],[FirstName] ,[MiddleName],[LastName] ,[Suffix] ,[EmailPromotion],[ModifiedDate])
select top 10 [BusinessEntityID],[PersonType],[NameStyle],[Title],[FirstName] ,[MiddleName],[LastName] ,[Suffix] ,[EmailPromotion],[ModifiedDate]
from Person.PersonPara executar o failover, faça um backup do log final do banco de dados adventureworks2017. Execute a seguinte consulta:
Backup Log adventureworks2017 to disk='\\domain\LogShippingBackups\Tail_Log_Backup.trn' with norecoveryConecte-se ao SQL02 (servidor secundário) e restaure o backup do log final usando RESTORE WITH RECOVERY. Execute o seguinte código:
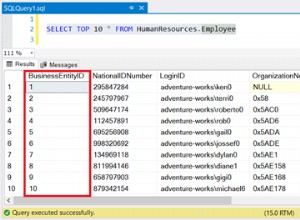
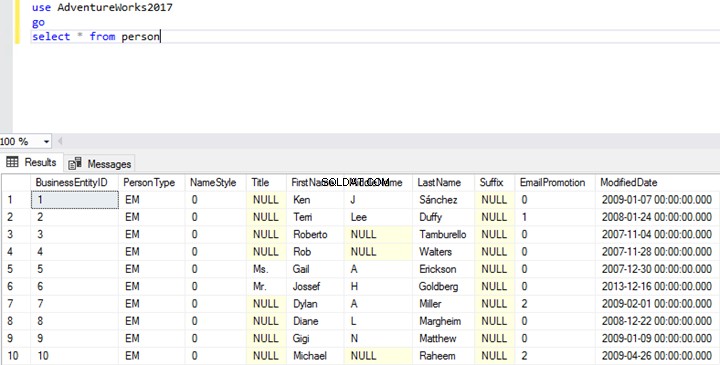
RESTORE LOG [AdventureWorks2017] FROM DISK = N'\\domain\LogShippingBackups\Tail_Log_Backup.trn' WITH RECOVERYDepois que o backup do final do log for restaurado com sucesso, execute a consulta para verificar se os dados foram copiados para o servidor secundário:
Select * from personResultado da consulta:
Como você vê, os dados são restaurados no servidor secundário.
Conclusão
Neste artigo, explicamos o processo de envio de logs do SQL Server e como configurá-lo. Também demonstramos o processo de failover passo a passo do envio de logs.