Em meu artigo anterior, expliquei o processo passo a passo de instalação de um nó na instância de cluster de failover do SQL Server existente. Junto com isso, também demonstrei o failover manual e o failover automático.
Neste artigo, demonstrarei o processo de adicionar um disco em um cluster de failover e, em seguida, mover o banco de dados existente para uma nova unidade.
Primeiramente, para adicionar um disco no cluster, devemos realizar os seguintes passos:
1. Crie um novo disco virtual iSCSI.
2. Conecte-se ao novo disco virtual iSCSI usando o iniciador iSCSI dos nós do cluster de failover.
3. Adicione um novo disco a um armazenamento de cluster de failover existente.
4. Mova o arquivo de banco de dados de amostra para o novo disco.
Primeiro, deixe-me fazer uma breve introdução à configuração de demonstração. Eu criei quatro máquinas virtuais no meu computador. Aqui estão os detalhes:
| Máquina Virtual | Nome do host | Endereço IP | Propósito |
| Controlador de domínio | DC.Local | 192.168.1.110 | Esta máquina virtual será usada como controlador de domínio. |
| SAN | SAN.DC.Local | 192.168.1.111 | Esta máquina virtual será usada como SAN virtual. Criei dois discos virtuais iSCSI que conectarei de nós de cluster de failover usando o iniciador iSCSI. |
| Nó SQL primário | SQL01.DC.Local | 192.168.1.112 | Nesta máquina virtual, instalaremos a instância clusterizada de failover. |
| Nó SQL secundário | SQL02.DC.Local | 192.168.1.113 | Nesta máquina virtual, instalaremos o nó secundário da instância de cluster de failover. |
Em SAN.DC.Local , criei três unidades iSCSI. Os detalhes são os seguintes:
| nome da unidade iSCSI | Propósito |
| Sql-data | Nesta unidade, estamos armazenando arquivos de banco de dados de bancos de dados de usuários e arquivos TempDB. |
| Sql-log | Nesta unidade, estamos armazenando os arquivos de log dos bancos de dados do usuário. |
| quórum | Esta unidade é usada como quorum. |
Segue a captura de tela da nossa configuração:
Criar um disco iSCSI
Como mencionei acima, devemos primeiro criar uma unidade virtual iSCSI. Nesse caso, usarei o PowerShell para criar e configurar discos virtuais iSCSI de tamanho fixo. O tamanho do disco virtual é de 8 GB. Para criar uma nova unidade iSCSI, execute o seguinte comando.
New-IscsiVirtualDisk –Path F:\new-sql-data\new-sql-data.vhdx –SizeBytes (8GB) –UseFixed
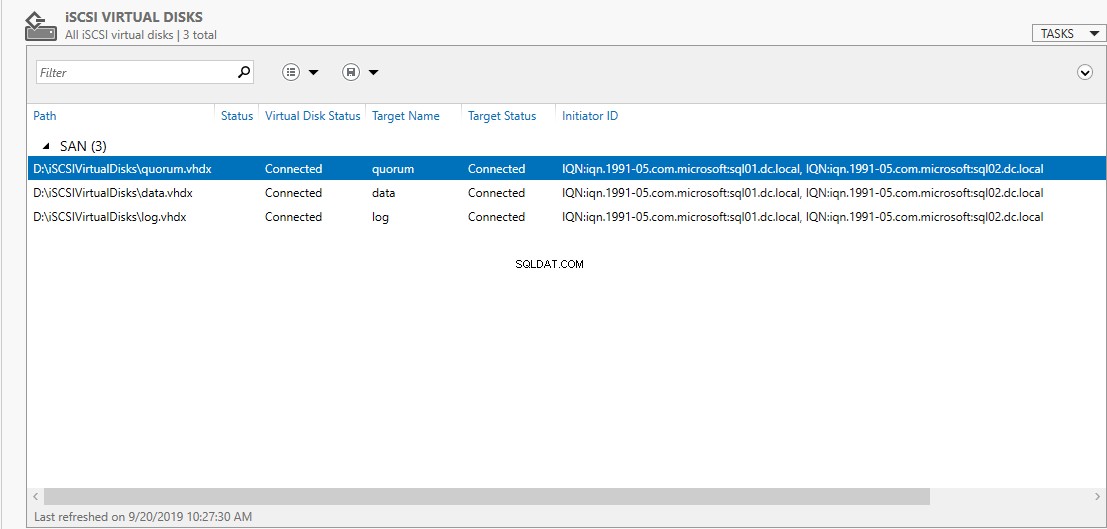
Para verificar se o disco iSCSI foi criado com sucesso, abra o S servidor M gerente e clique em discos virtuais iSCSI no painel esquerdo. Veja a seguinte imagem:
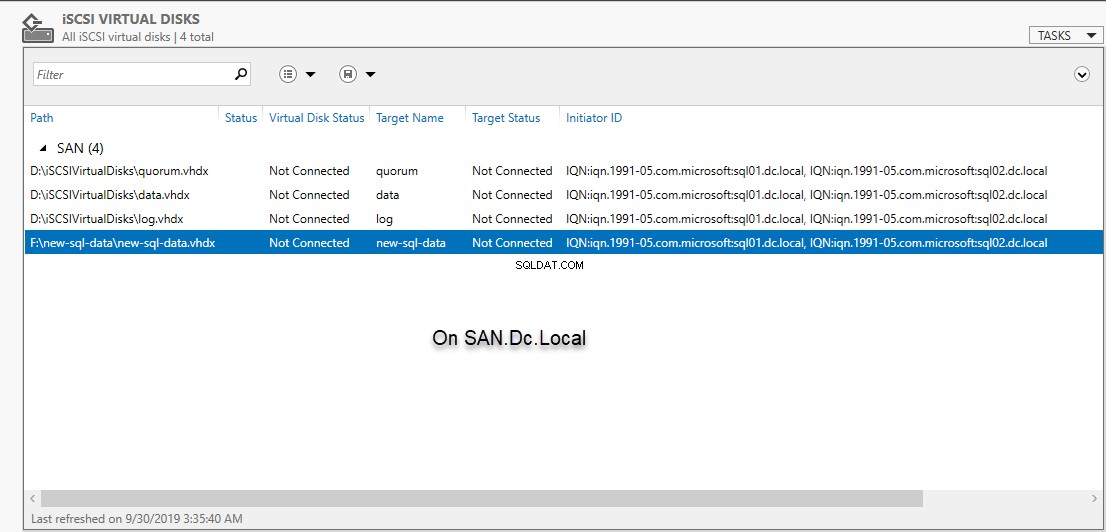
Agora devemos criar um destino iSCSI. Os servidores remotos podem se conectar a um disco virtual usando o nome de destino. Aqui, criarei um destino chamado new-sql-data . Para criar um destino iSCSI chamado “new-sql-data ” e atribua-o a SQL02.dc.Local e SQL02.dc.Local , execute o seguinte comando.
New-IscsiServerTarget -TargetName "new-sql-data" -InitiatorIds @("IQN:iqn.1991-05.com.microsoft:sql01.dc.local", "IQN:iqn.1991-05.com.microsoft:sql02.dc.local") Depois que o destino iSCSI for criado, devemos atribuir nosso disco virtual ao destino iSCSI. Para isso, execute a seguinte consulta:
Add-IscsiVirtualDiskTargetMapping -TargetName new-sql-data –Path "F:\new-sql-data\new-sql-data.vhdx"
Depois que o mapeamento de destino for concluído com êxito, atualize o painel do disco virtual iSCSI no Gerenciador do Servidor. Veja a seguinte imagem:
Conecte-se ao novo disco virtual iSCSI usando o iniciador iSCSI dos nós do cluster de failover
Agora, vamos nos conectar a esta unidade a partir do SQL01.dc.local nó usando RDP.
Para se conectar ao disco virtual iSCSI usando o iniciador iSCSI, abra o iniciador iSCSI e clique no botão Atualizar botão para descobrir o alvo. Agora você pode escolher o nome de destino apropriado em "Descobertas " caixa de texto. Selecione o destino apropriado e clique em C conectar . Veja a seguinte imagem:
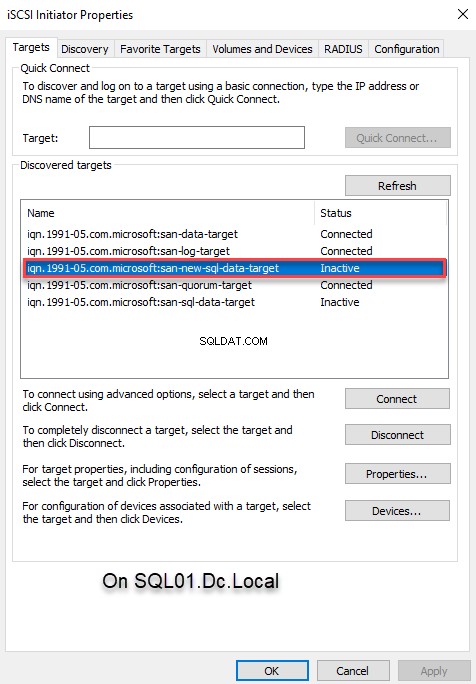
Assim que estivermos conectados ao disco virtual, você poderá ver o disco no D isco M gerente seção em C computador M administração . Para usar o disco dentro do cluster, devemos realizar as seguintes tarefas:
- Coloque o disco online. Para fazer isso, clique com o botão direito do mouse em D isco 4 e selecione On-line . Veja a imagem a seguir:
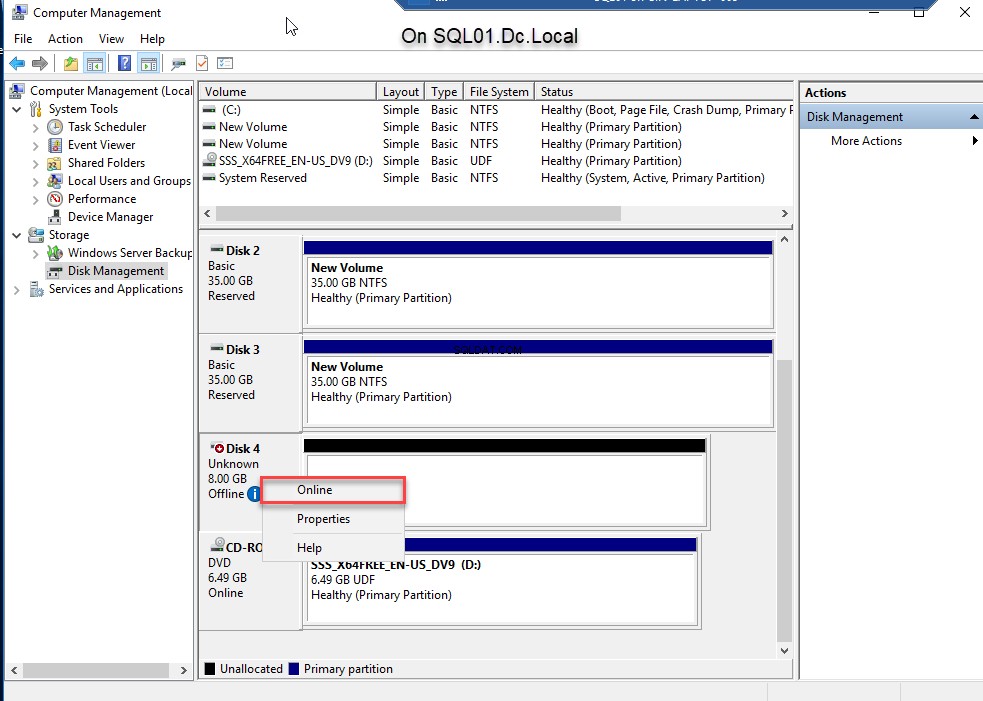
- Quando o disco estiver online, inicialize o disco. Para fazer isso, clique com o botão direito do mouse em Disco 4 e selecione Inicializar disco . Veja a imagem a seguir:
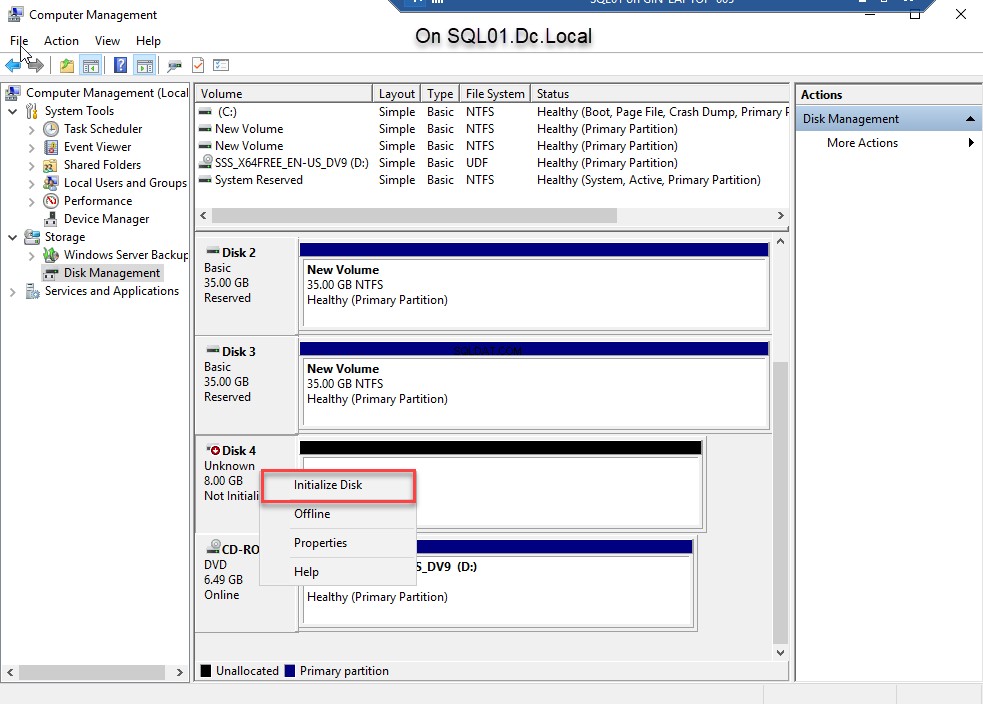
- Depois que o disco for inicializado, clique com o botão direito do mouse em Disco 4 e selecione Novo Volume Simples para criar uma partição. Veja a imagem a seguir:
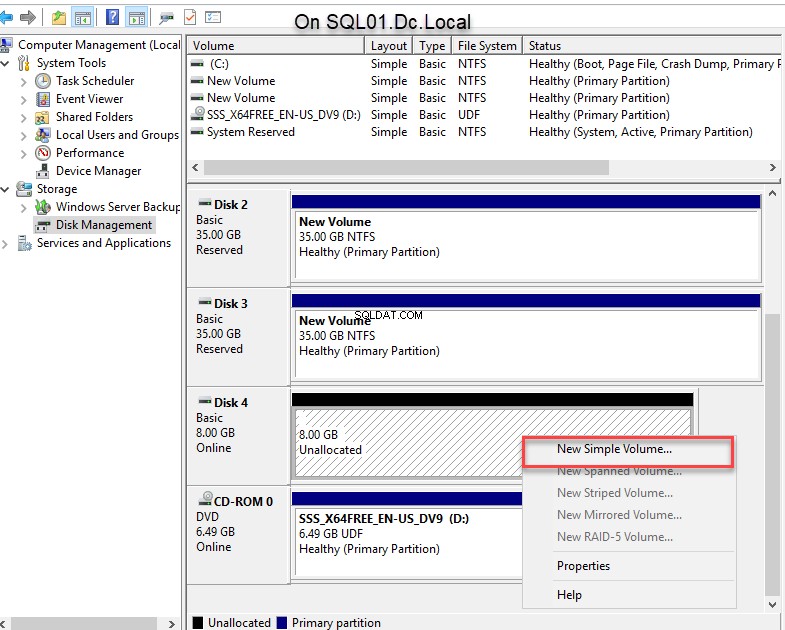
Da mesma forma, devemos conectar a unidade virtual do SQL02.dc.local nó. Para fazer isso, conecte o SQL02.dc.local nó usando RDP, abra o iniciador iSCSI e clique no botão Atualizar botão para descobrir o alvo. Agora você pode escolher o nome de destino apropriado em Destinos descobertos caixa de texto. Selecione o destino apropriado e clique em C conectar . Veja a seguinte imagem:
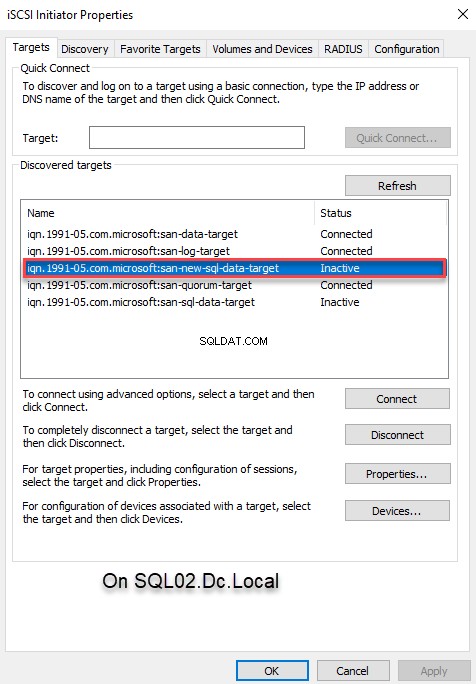
Adicione o novo disco a um armazenamento de cluster de failover existente.
Para adicionar este disco ao armazenamento do cluster, conecte-se a SQL01.Dc.Local usando RDP, abra o F além C brilho M gerente , conecte-se a SQLCluster.DC.Local , selecione D riscos no painel esquerdo e clique em A dd disco . A caixa de diálogo “Adicionar disco ao cluster” será aberta. Nesta caixa de diálogo, o novo disco clusterizado será exibido. Veja a seguinte imagem:
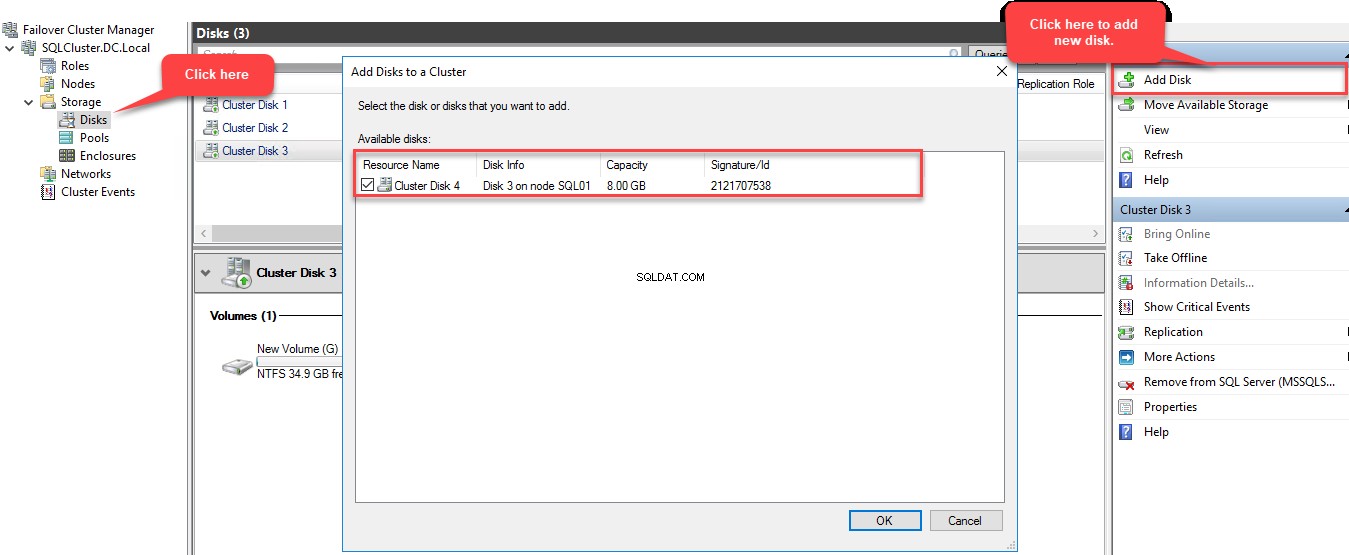
Depois que o novo disco for adicionado, você poderá vê-lo no menu de disco do Gerenciador de Cluster de Failover. Veja a seguinte imagem:
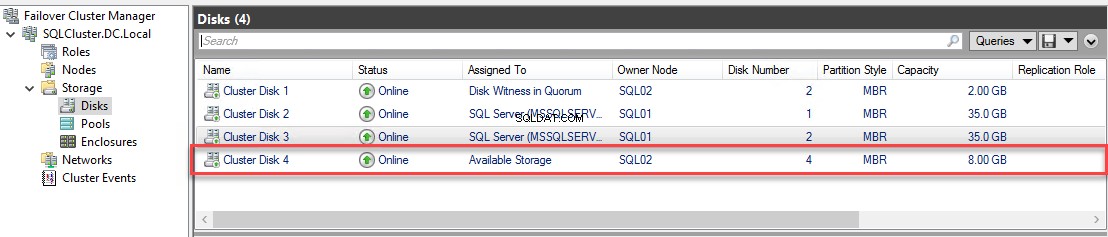
Mova o arquivo de banco de dados de amostra para o novo disco.
Depois que o disco for adicionado, vamos mover um arquivo de banco de dados de amostra para a nova unidade. Eu criei um banco de dados chamado de modabase em SQL01.dc.local . Queremos mover seu arquivo de dados para o novo disco. Para fazer isso, conecte-se ao PowerShell e, em seguida, conecte-se à instância do SQL Server usando o comando ‘SQLCmd ' comando.
Quando estiver conectado à instância, execute o comando a seguir para desanexar o banco de dados.
exec sp_detach_db [demodatabase] go
Depois que o banco de dados for desanexado, copie o arquivo de dados da unidade F (unidade antiga) para a unidade E (nova unidade) e execute o seguinte comando para anexar o banco de dados.
CREATE DATABASE demodatabase
ON (FILENAME = 'E:\SQLData\demodatabase.mdf'),
(FILENAME = 'F:\SQLLog\demodatabase_log.ldf')
FOR ATTACH;
GO Ao executar o comando acima, você receberá o seguinte erro:
Msg 5184, Level 16, State 2, Server SQLCLUST, Line 1 Cannot use file 'E:\SQLData\demodatabase.mdf' for clustered server. Only formatted files on which the cluster resource of the server has a dependency can be used. Either the disk resource containing the file is not present in the cluster group or the cluster resource of the Sql Server does not have a dependency on it.
Este erro ocorre porque não adicionamos o novo disco ao grupo de recursos do cluster e à dependência AND da função MSSQLSERVER. Veja a seguinte imagem:
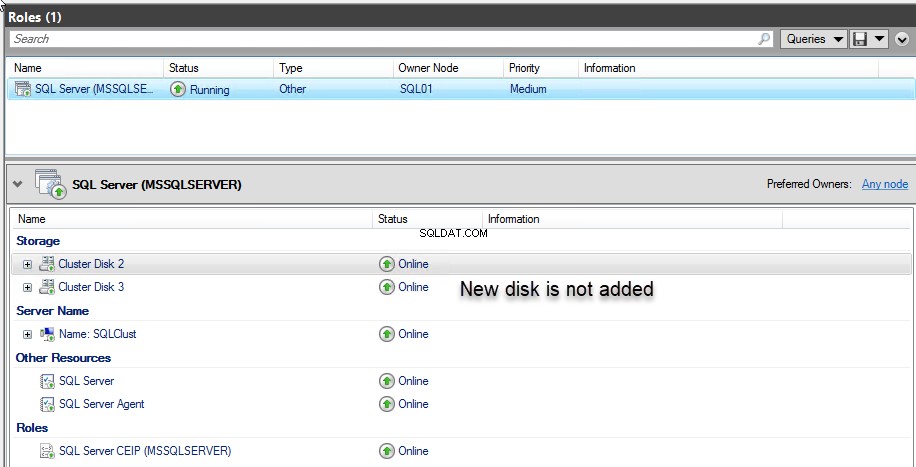
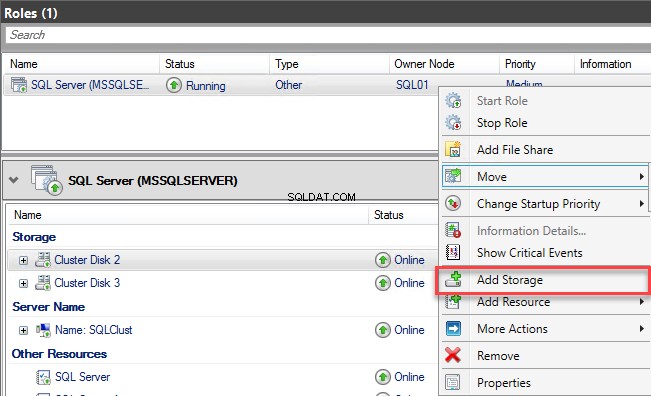
Para corrigir esse erro, devemos adicionar o novo disco à função MSSQLSERVER. Para fazer isso, abra o Failover Cluster Manager, clique em Select Roles, clique com o botão direito do mouse no SQL Server (MSSQLSERVER ) e escolha Adicionar armazenamento . Veja a seguinte imagem:
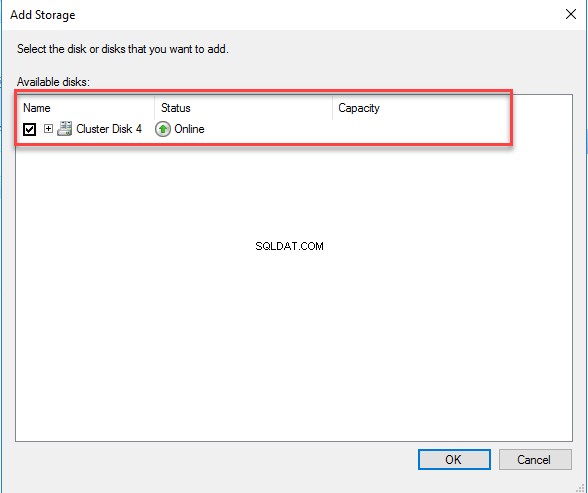
O Adicionar armazenamento caixa de diálogo será aberta. Na lista de armazenamento disponível, escolha o disco que criamos. Veja a seguinte imagem:
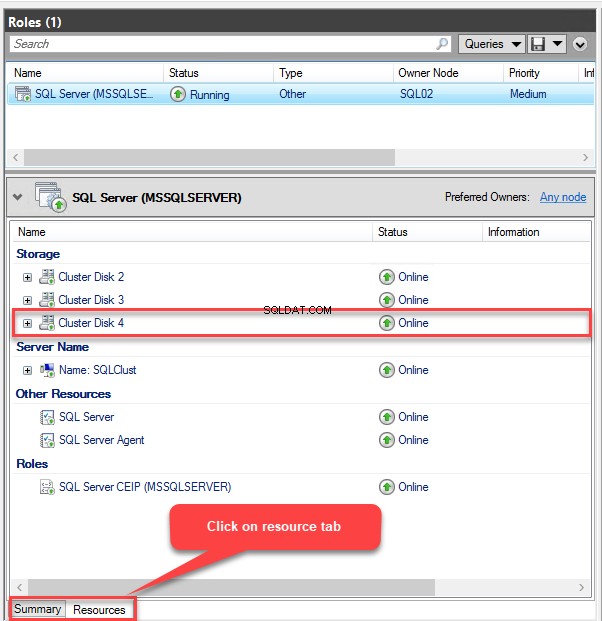
Depois de adicionar o armazenamento, podemos verificá-lo na guia de recursos da função MSSQLSERVER. Veja a seguinte imagem:
Uma vez que o disco é adicionado, precisamos também adicioná-lo à dependência do SQL Server AND . Para fazer isso, clique com o botão direito do mouse em SQL Server na lista de recursos em MSSQLSERVER função e selecione P propriedades . No P propriedades caixa de diálogo, vá para Dependências guia e selecione Disco de cluster 4 na caixa suspensa em Recursos coluna.
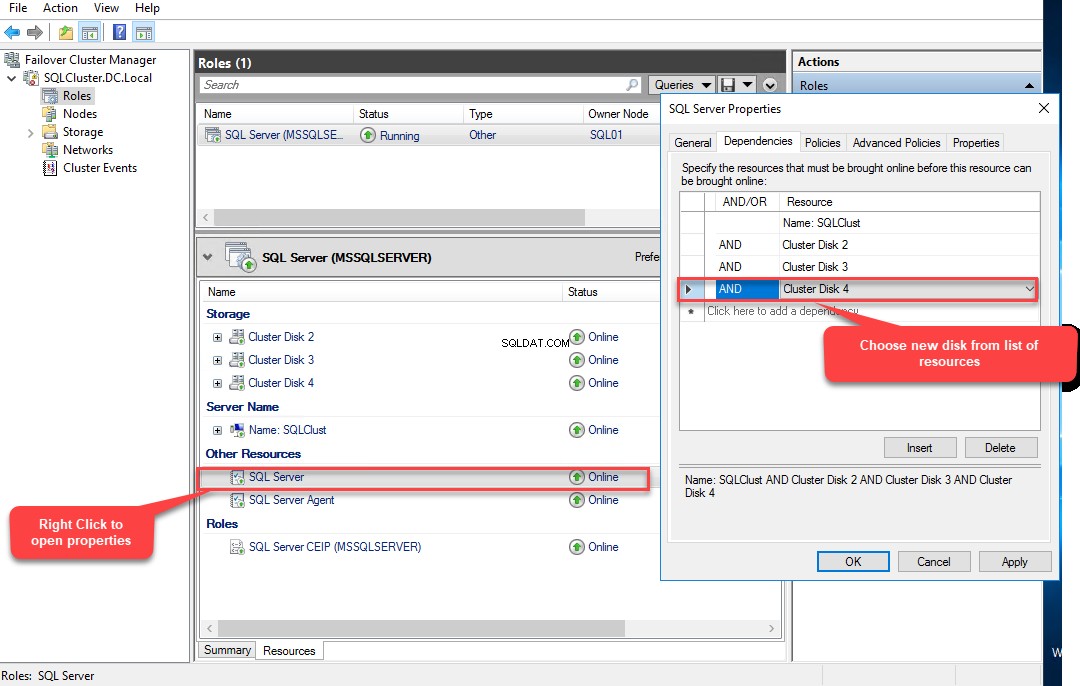
Depois que o recurso de disco for adicionado, tente anexar o banco de dados usando o seguinte comando:
CREATE DATABASE demodatabase
ON (FILENAME = 'E:\SQLData\demodatabase.mdf'),
(FILENAME = 'F:\SQLLog\demodatabase_log.ldf')
FOR ATTACH;
GO O comando será executado com sucesso. Para verificar se o arquivo foi copiado para o local apropriado, execute a seguinte consulta no PowerShell.
select db_name(database_id) as [database name], physical_name from sys.master_files where db_name(database_id) ='demodatabase'
Segue a saída:
Database Name physical_name ------------ --------------------------------- demodatabase E:\SQLData\demodatabase.mdf demodatabase F:\SQLLog\demodatabase_log.ldf
Como você pode ver, o arquivo de banco de dados foi movido para a nova unidade.
Resumo
Neste artigo, expliquei o processo passo a passo de adicionar um disco a uma instância clusterizada de failover do SQL Server existente. No próximo artigo, explicarei como mover bancos de dados do sistema para um novo disco em cluster.
Fique atento!