Introdução
Este tutorial inclui informações sobre SQL (DDL, DML) que reuni durante minha vida profissional. Este é o mínimo que você precisa saber ao trabalhar com bancos de dados. Se houver necessidade de usar construções SQL complexas, geralmente navego na biblioteca MSDN, que pode ser facilmente encontrada na internet. Na minha opinião, é muito difícil manter tudo na cabeça e, a propósito, não há necessidade disso. Recomendo que você conheça todas as principais construções utilizadas na maioria dos bancos de dados relacionais como Oracle, MySQL e Firebird. Ainda assim, eles podem diferir nos tipos de dados. Por exemplo, para criar objetos (tabelas, restrições, índices, etc.), você pode simplesmente usar o ambiente de desenvolvimento integrado (IDE) para trabalhar com bancos de dados e não há necessidade de estudar ferramentas visuais para um determinado tipo de banco de dados (MS SQL, Oracle , MySQL, Firebird, etc.). Isso é conveniente porque você pode ver todo o texto e não precisa procurar em várias guias para criar, por exemplo, um índice ou uma restrição. Se você trabalha constantemente com bancos de dados, criar, modificar e principalmente reconstruir um objeto usando scripts é muito mais rápido do que no modo visual. Além disso, na minha opinião, no modo script (com a devida precisão), é mais fácil especificar e controlar as regras de nomeação de objetos. Além disso, é conveniente usar scripts quando você precisar transferir alterações de banco de dados de um banco de dados de teste para um banco de dados de produção.
SQL é dividido em várias partes. No meu artigo, revisarei os mais importantes:
DDL – Linguagem de definição de dados
DML – Linguagem de Manipulação de Dados, que inclui as seguintes construções:
- SELECIONAR – seleção de dados
- INSERIR – inserção de novos dados
- ATUALIZAÇÃO – atualização de dados
- EXCLUIR – exclusão de dados
- MERGE – mesclagem de dados
Vou explicar todas as construções em casos de estudo. Além disso, acho que uma linguagem de programação, principalmente SQL, deve ser estudada na prática para melhor entendimento.
Este é um tutorial passo a passo, onde você precisa executar exemplos durante a leitura. No entanto, se você precisar conhecer o comando em detalhes, navegue na Internet, por exemplo, MSDN.
Ao criar este tutorial, usei o banco de dados MS SQL Server, versão 2014, e o MS SQL Server Management Studio (SSMS) para executar scripts.
Resumidamente sobre MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) é o utilitário Microsoft SQL Server para configurar, gerenciar e administrar componentes de banco de dados. Inclui um editor de scripts e um programa gráfico que trabalha com objetos e configurações do servidor. A principal ferramenta do SQL Server Management Studio é o Pesquisador de Objetos, que permite ao usuário visualizar, recuperar e gerenciar objetos do servidor. Este texto foi parcialmente retirado da Wikipedia.
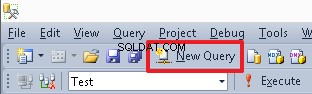
Para criar um novo editor de scripts, use o botão Nova Consulta:
Para alternar do banco de dados atual, você pode usar o menu suspenso:
Para executar um determinado comando ou conjunto de comandos, destaque-o e pressione o botão Executar ou F5. Se houver apenas um comando no editor ou você precisar executar todos os comandos, não destaque nada.
Depois de executar scripts que criam objetos (tabelas, colunas, índices), selecione o objeto correspondente (por exemplo, Tabelas ou Colunas) e clique em Atualizar no menu de atalho para ver as alterações.
Na verdade, isso é tudo o que você precisa saber para executar os exemplos fornecidos aqui.
Teoria
Um banco de dados relacional é um conjunto de tabelas vinculadas. Em geral, um banco de dados é um arquivo que armazena dados estruturados.
Database Management System (DBMS) é um conjunto de ferramentas para trabalhar com determinados tipos de banco de dados (MS SQL, Oracle, MySQL, Firebird, etc.).
Observação: Como em nosso dia a dia, dizemos “Oracle DB” ou apenas “Oracle” na verdade significando “Oracle DBMS”, então neste tutorial, usarei o termo “banco de dados”.
Uma tabela é um conjunto de colunas. Muitas vezes, você pode ouvir as seguintes definições desses termos:campos, linhas e registros, que significam o mesmo.
Uma tabela é o objeto principal do banco de dados relacional. Todos os dados são armazenados linha por linha nas colunas da tabela.
Para cada tabela, bem como para suas colunas, você precisa especificar um nome, segundo o qual você pode encontrar um item necessário.
O nome do objeto, tabela, coluna e índice podem ter o comprimento mínimo – 128 símbolos.
Observação: Em bancos de dados Oracle, um nome de objeto pode ter o comprimento mínimo – 30 símbolos. Assim, em um determinado banco de dados, é necessário criar regras personalizadas para nomes de objetos.
SQL é uma linguagem que permite executar consultas em bancos de dados via DBMS. Em um determinado SGBD, uma linguagem SQL pode ter seu próprio dialeto.
DDL e DML – a sublinguagem SQL:
- A linguagem DDL serve para criar e modificar uma estrutura de banco de dados (exclusão de tabelas e links);
- A linguagem DML permite manipular os dados da tabela, suas linhas. Ele também serve para selecionar dados de tabelas, adicionar novos dados, bem como atualizar e excluir dados atuais.
É possível usar dois tipos de comentários em SQL (de linha única e delimitados):
-- comentário de linha única
e
/* comentário delimitado */
Isso é tudo quanto à teoria.
DDL – Linguagem de definição de dados
Vamos considerar uma tabela de amostra com dados sobre funcionários representados de maneira familiar para uma pessoa que não é programadora.
| ID do funcionário | Nome Completo | Data de nascimento | Posição | Departamento | |
| 1000 | João | 19.02.1955 | exemplo@sqldat.com | CEO | Administração |
| 1001 | Daniel | 03.12.1983 | exemplo@sqldat.com | programador | TI |
| 1002 | Mike | 07.06.1976 | exemplo@sqldat.com | Contador | Departamento de contas |
| 1003 | Jordânia | 17.04.1982 | exemplo@sqldat.com | Programador sênior | TI |
Nesse caso, as colunas possuem os seguintes títulos:ID do Funcionário, Nome Completo, Data de Nascimento, E-mail, Cargo e Departamento.
Podemos descrever cada coluna desta tabela por seu tipo de dados:
- ID do funcionário – inteiro
- Nome Completo – string
- Data de nascimento – data
- E-mail – string
- Posição – string
- Departamento – string
Um tipo de coluna é uma propriedade que especifica qual tipo de dados cada coluna pode armazenar.
Para começar, você precisa se lembrar dos principais tipos de dados usados no MS SQL:
| Definição | Designação em MS SQL | Descrição |
| String de comprimento variável | varchar(N) e nvarchar(N) | Usando o número N, podemos especificar o comprimento máximo de string possível para uma coluna específica. Por exemplo, se queremos dizer que o valor da coluna Full Name pode conter 30 símbolos (no máximo), é necessário especificar o tipo de nvarchar(30). A diferença entre varchar e nvarchar é que varchar permite armazenar strings no formato ASCII, enquanto nvarchar armazena strings no formato Unicode, onde cada símbolo ocupa 2 bytes. Recomendo usar o tipo varchar apenas se tiver certeza de que você não precisará armazenar os símbolos Unicode no campo fornecido. Por exemplo, você pode usar varchar para armazenar contatos de e-mail. |
| String de comprimento fixo | char(N) e nchar(N) | Esse tipo difere da string de comprimento variável no seguinte:se o comprimento da string for menor que N símbolos, os espaços serão sempre adicionados ao comprimento N à direita. Assim, em um banco de dados, são necessários exatamente N símbolos, onde um símbolo leva 1 byte para char e 2 bytes para nchar. Na minha prática, esse tipo não é muito usado. Ainda assim, se alguém o usa, geralmente esse tipo tem o formato char(1), ou seja, quando um campo é definido por 1 símbolo. |
| Inteiro | int | Esse tipo nos permite usar apenas inteiros (positivos e negativos) em uma coluna. Nota:um intervalo de numeração para este tipo é o seguinte:de 2 147 483 648 a 2 147 483 647. Normalmente, é o tipo principal usado para identificar identificadores. |
| Número de ponto flutuante | flutuar | Números com ponto decimal. |
| Data | data | É usado para armazenar apenas uma data (data, mês e ano) em uma coluna. Por exemplo, 15/02/2014. Este tipo pode ser usado para as seguintes colunas:data de recebimento, data de nascimento, etc., quando você precisa especificar apenas uma data ou quando a hora não é importante para nós e podemos eliminá-la. |
| Hora | hora | Você pode usar este tipo se for necessário armazenar tempo:horas, minutos, segundos e milissegundos. Por exemplo, você tem 17:38:31.3231603 ou precisa adicionar o horário de partida do voo. |
| Data e hora | datahora | Este tipo permite que os usuários armazenem data e hora. Por exemplo, você tem o evento em 15/02/2014 17:38:31.323. |
| Indicador | bit | Você pode usar esse tipo para armazenar valores como 'Sim'/'Não', em que 'Sim' é 1 e 'Não' é 0. |
Além disso, não é necessário especificar o valor do campo, a menos que seja proibido. Nesse caso, você pode usar NULL.
Para executar exemplos, criaremos um banco de dados de teste chamado ‘Test’.
Para criar um banco de dados simples sem propriedades adicionais, execute o seguinte comando:
CRIAR BANCO DE DADOS
Para excluir um banco de dados, execute este comando:
Teste DROP DATABASE
Para mudar para nosso banco de dados, use o comando:
USE Teste
Como alternativa, você pode selecionar o banco de dados de teste no menu suspenso na área do menu SSMS.
Agora, podemos criar uma tabela em nosso banco de dados usando descrições, espaços e símbolos cirílicos:
CREATE TABLE [Employees]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar( 30) )
Nesse caso, precisamos colocar os nomes entre colchetes […].
Ainda assim, é melhor especificar todos os nomes de objetos em latim e não usar espaços nos nomes. Neste caso, cada palavra começa com uma letra maiúscula. Por exemplo, para o campo “EmployeeID”, podemos especificar o nome PersonnelNumber. Você também pode usar números no nome, por exemplo, PhoneNumber1.
Observação: Em alguns SGBDs, é mais conveniente usar o seguinte formato de nome «PHONE_NUMBER». Por exemplo, você pode ver esse formato em bancos de dados ORACLE. Além disso, o nome do campo não deve coincidir com as palavras-chave usadas no DBMS.
Por esse motivo, você pode esquecer a sintaxe dos colchetes e excluir a tabela Funcionários:
DROP TABLE [Funcionários]
Por exemplo, você pode nomear a tabela com funcionários como “Funcionários” e definir os seguintes nomes para seus campos:
- ID
- Nome
- Aniversário
- Posição
- Departamento
Muitas vezes, usamos ‘ID’ para o campo identificador.
Agora vamos criar uma tabela:
CREATE TABLE Employees( ID int, Name nvarchar(30), Data de aniversário, Email nvarchar(30), Cargo nvarchar(30), Department nvarchar(30) )
Para definir as colunas obrigatórias, você pode usar a opção NOT NULL.
Para a tabela atual, você pode redefinir os campos usando os seguintes comandos:
-- Campo de ID updateALTER TABLE Funcionários ALTER COLUMN ID int NOT NULL-- Campo de nome updateALTER TABLE Funcionários ALTER COLUMN Nome nvarchar(30) NOT NULL
Observação: O conceito geral da linguagem SQL para a maioria dos DBMSs é o mesmo (pela minha própria experiência). A diferença entre DDLs em diferentes SGBDs está principalmente nos tipos de dados (eles podem diferir não apenas por seus nomes, mas também por sua implementação específica). Além disso, a implementação específica do SQL (comandos) é a mesma, mas pode haver pequenas diferenças no dialeto. Conhecendo o básico do SQL, você pode alternar facilmente de um DBMS para outro. Nesse caso, você só precisará entender as especificidades da implementação de comandos em um novo SGBD.
Compare os mesmos comandos no ORACLE DBMS:
-- create table CREATE TABLE Employees( ID int, -- No ORACLE o tipo int é um valor para number(38) Name nvarchar2(30), -- no ORACLE nvarchar2 é idêntico ao nvarchar no MS SQL Data de aniversário, Email nvarchar2(30), Posição nvarchar2(30), Departamento nvarchar2(30) ); -- Atualização do campo ID e Nome (aqui usamos MODIFY(…) ao invés de ALTER COLUMNALTER TABLE Funcionários MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- adiciona PK (neste caso a construção é a mesma como no MS SQL) ALTER TABLE Funcionários ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE difere na implementação do tipo varchar2. Seu formato depende das configurações do banco de dados e você pode salvar um texto, por exemplo, em UTF-8. Além disso, você pode especificar o comprimento do campo em bytes e símbolos. Para fazer isso, você precisa usar os valores BYTE e CHAR seguidos pelo campo de comprimento. Por exemplo:
NAME varchar2(30 BYTE) – capacidade do campo é igual a 30 bytes NAME varchar2(30 CHAR) – capacidade do campo é igual a 30 símbolos
O valor (BYTE ou CHAR) a ser usado por padrão ao indicar apenas varchar2(30) no ORACLE dependerá das configurações do banco de dados. Muitas vezes, você pode ser facilmente confundido. Assim, recomendo especificar explicitamente CHAR ao usar o tipo varchar2 (por exemplo, com UTF-8) no ORACLE (já que é mais conveniente ler o comprimento da string em símbolos).
No entanto, neste caso, se houver algum dado na tabela, para executar os comandos com sucesso, é necessário preencher os campos ID e Nome em todas as linhas da tabela.
Vou mostrá-lo em um exemplo específico.
Vamos inserir dados nos campos ID, Cargo e Departamento usando o seguinte script:
INSERIR Funcionários(ID,Cargo,Departamento) VALORES (1000,'CEO,N'Administração'), (1001,N'Programador',N'IT'), (1002,N'Contador',N'Contas dept'), (1003,N'Programador Sênior',N'IT')
Nesse caso, o comando INSERT também retorna um erro. Isso acontece porque não especificamos o valor para o campo obrigatório Nome.
Se houvesse alguns dados na tabela original, então o comando “ALTER TABLE Employees ALTER COLUMN ID int NOT NULL” funcionaria, enquanto o comando “ALTER TABLE Employees ALTER COLUMN Name int NOT NULL” retornaria um erro que o campo Nome possui valores NULOS.
Vamos adicionar valores no campo Nome:
INSERIR Funcionários(ID,Cargo,Departamento,Nome) VALORES (1000,N'CEO',N'Administração',N'John'), (1001,N'Programador',N'IT',N'Daniel '), (1002,N'Contador',N'Departamento de Contas',N'Mike'), (1003,N'Programador Sênior',N'IT',N'Jordan')
Além disso, você pode usar NOT NULL ao criar uma nova tabela com a instrução CREATE TABLE.
Primeiramente, vamos deletar uma tabela:
Funcionários DROP TABLE
Agora, vamos criar uma tabela com os campos obrigatórios ID e Nome:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Data de aniversário, Email nvarchar(30), Cargo nvarchar(30), Department nvarchar(30) )
Além disso, você pode especificar NULL após um nome de coluna, o que implica que valores NULL são permitidos. Isso não é obrigatório, pois esta opção é definida por padrão.
Se você precisar tornar a coluna atual não obrigatória, use a seguinte sintaxe:
ALTER TABLE Funcionários ALTER COLUMN Nome nvarchar(30) NULL
Alternativamente, você pode usar este comando:
ALTER TABLE Funcionários ALTER COLUMN Nome nvarchar(30)
Além disso, com este comando, podemos modificar o tipo de campo para outro compatível ou alterar seu comprimento. Por exemplo, vamos estender o campo Nome para 50 símbolos:
ALTER TABLE Funcionários ALTER COLUMN Nome nvarchar(50)
Chave primária
Ao criar uma tabela, você precisa especificar uma coluna ou um conjunto de colunas exclusivo para cada linha. Usando esse valor exclusivo, você pode identificar um registro. Esse valor é chamado de chave primária. A coluna ID (que contém «o número pessoal de um funcionário» – no nosso caso este é o valor único para cada funcionário e não pode ser duplicado) pode ser a chave primária da nossa tabela Funcionários.
Você pode usar o seguinte comando para criar uma chave primária para a tabela:
ALTER TABLE Funcionários ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
‘PK_Employees’ é um nome de restrição que define a chave primária. Normalmente, o nome de uma chave primária consiste no prefixo ‘PK_’ e no nome da tabela.
Se a chave primária contiver vários campos, você precisará listar esses campos entre colchetes separados por uma vírgula:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Tenha em mente que no MS SQL, todos os campos da chave primária devem ser NOT NULL.
Além disso, você pode definir uma chave primária ao criar uma tabela. Vamos deletar a tabela:
Funcionários DROP TABLE
Em seguida, crie uma tabela usando a seguinte sintaxe:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Data de aniversário, Email nvarchar(30), Posição nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – descrever PK após todos os campos como restrição)
Adicione dados à tabela:
INSERIR Funcionários(ID,Cargo,Departamento,Nome) VALORES (1000,N'CEO',N'Administração',N'John'), (1001,N'Programador',N'IT',N'Daniel '), (1002,N'Contador',N'Departamento de contas',N'Mike'), (1003,N'Programador sênior',N'IT',N'Jordan')
Na verdade, você não precisa especificar o nome da restrição. Neste caso, será atribuído um nome de sistema. Por exemplo, «PK__Employee__3214EC278DA42077»:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Data de aniversário, Email nvarchar(30), Posição nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
ou
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Data de aniversário, Email nvarchar(30), Posição nvarchar(30), Department nvarchar(30) )
Pessoalmente, eu recomendaria especificar explicitamente o nome da restrição para tabelas permanentes, pois é mais fácil trabalhar ou excluir um valor explicitamente definido e claro no futuro. Por exemplo:
ALTER TABLE Funcionários DROP CONSTRAINT PK_Employees
Ainda assim, é mais confortável aplicar essa sintaxe curta, sem nomes de restrição ao criar tabelas de banco de dados temporárias (o nome de uma tabela temporária começa com # ou ##.
Resumo:
Já analisamos os seguintes comandos:
- CRIAR TABELA table_name (lista de campos e seus tipos, bem como restrições) – serve para criar uma nova tabela no banco de dados atual;
- DERRAR TABELA table_name – serve para deletar uma tabela do banco de dados atual;
- ALTER TABLE table_name ALTER COLUMN column_name … – serve para atualizar o tipo de coluna ou para modificar suas configurações (por exemplo, quando você precisa definir NULL ou NOT NULL);
- ALTER TABLE table_name ADICIONAR CONSTRAINT constraint_name CHAVE PRIMÁRIA (campo1, campo2,…) – usado para adicionar uma chave primária à tabela atual;
- ALTER TABLE table_name DROP CONSTRAINT constraint_name – usado para excluir uma restrição da tabela.
Tabelas temporárias
Resumo do MSDN. Existem dois tipos de tabelas temporárias no MS SQL Server:local (#) e global (##). As tabelas temporárias locais são visíveis apenas para seus criadores antes que a instância do SQL Server seja desconectada. Eles são excluídos automaticamente depois que o usuário é desconectado da instância do SQL Server. As tabelas temporárias globais ficam visíveis para todos os usuários durante qualquer sessão de conexão após a criação dessas tabelas. Essas tabelas são excluídas quando os usuários são desconectados da instância do SQL Server.
As tabelas temporárias são criadas no banco de dados do sistema tempdb, o que significa que não inundamos o banco de dados principal. Além disso, você pode excluí-los usando o comando DROP TABLE. Muitas vezes, as tabelas temporárias locais (#) são usadas.
Para criar uma tabela temporária, você pode usar o comando CREATE TABLE:
CREATE TABLE #Temp( ID int, Nome nvarchar(30) )
Você pode excluir a tabela temporária com o comando DROP TABLE:
DROP TABLE #Temp
Além disso, você pode criar uma tabela temporária e preenchê-la com os dados usando a sintaxe SELECT … INTO:
SELECT ID,Name INTO #Temp FROM Employees
Observação: Em diferentes SGBDs, a implementação de bancos de dados temporários pode variar. Por exemplo, nos SGBDs ORACLE e Firebird, a estrutura das tabelas temporárias deve ser definida antecipadamente pelo comando CREATE GLOBAL TEMPORARY TABLE. Além disso, você precisa especificar a maneira de armazenar dados. Depois disso, um usuário o vê entre as tabelas comuns e trabalha com ele como em uma tabela convencional.
Normalização de banco de dados:divisão em subtabelas (tabelas de referência) e definição de relacionamentos de tabela
Nossa atual tabela Funcionários tem uma desvantagem:um usuário pode digitar qualquer texto nos campos Cargo e Departamento, o que pode retornar erros, pois para um funcionário ele pode especificar "TI" como departamento, enquanto para outro funcionário pode especificar "TI departamento". Como resultado, não ficará claro o que o usuário quis dizer, se esses funcionários trabalham para o mesmo departamento ou se há um erro ortográfico e existem 2 departamentos diferentes. Além disso, neste caso, não poderemos agrupar corretamente os dados para um relatório, onde precisamos mostrar o número de funcionários de cada departamento.
Outra desvantagem é o volume de armazenamento e sua duplicação, ou seja, você precisa especificar um nome completo do departamento para cada funcionário, o que exige espaço nos bancos de dados para armazenar cada símbolo do nome do departamento.
A terceira desvantagem é a complexidade de atualizar dados de campo quando você precisa modificar um nome de qualquer cargo – de programador a programador júnior. Neste caso, você precisará adicionar novos dados em cada linha da tabela onde a Posição for “Programador”.
Para evitar tais situações, é recomendável usar a normalização do banco de dados – divisão em subtabelas – tabelas de referência.
Vamos criar 2 tabelas de referência “Posições” e “Departamentos”:
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departamentos( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
Observe que aqui usamos uma nova IDENTIDADE de propriedade. Isso significa que os dados da coluna ID serão listados automaticamente a partir de 1. Assim, ao adicionar novos registros, os valores 1, 2, 3, etc. serão atribuídos sequencialmente. Normalmente, esses campos são chamados de campos de incremento automático. Apenas um campo com a propriedade IDENTITY pode ser definido como chave primária em uma tabela. Normalmente, mas nem sempre, esse campo é a chave primária da tabela.
Observação: Em diferentes SGBDs, a implementação de campos com um incrementador pode ser diferente. No MySQL, por exemplo, tal campo é definido pela propriedade AUTO_INCREMENT. No ORACLE e Firebird, você pode emular esta funcionalidade por sequências (SEQUENCE). Mas até onde eu sei, a propriedade GENERATED AS IDENTITY foi adicionada no ORACLE.
Vamos preencher essas tabelas automaticamente com base nos dados atuais nos campos Cargo e Departamento da tabela Funcionários:
-- preencha o campo Nome da tabela Cargos com valores exclusivos do campo Cargo da tabela Funcionários INSERT Cargos(Nome) SELECT DISTINCT Cargo FROM Funcionários WHERE Cargo NÃO É NULO – descarta registros onde um cargo não é especificado
Você precisa fazer as mesmas etapas para a tabela Departamentos:
INSERIR Departamentos(Nome) SELECT Departamento DISTINTO DE Funcionários ONDE Departamento NÃO É NULO
Agora, se abrirmos as tabelas Cargos e Departamentos, veremos uma lista numerada de valores no campo ID:
SELECIONAR * DE Posições
| ID | Nome |
| 1 | Contador |
| 2 | CEO |
| 3 | Programador |
| 4 | Programador Sênior |
SELECIONAR * DE Departamentos
| ID | Nome |
| 1 | Administração |
| 2 | Departamento de contas |
| 3 | TI |
Essas tabelas serão as tabelas de referência para definir cargos e departamentos. Agora, vamos nos referir a identificadores de cargos e departamentos. Primeiramente, vamos criar novos campos na tabela Employees para armazenar os identificadores:
-- adiciona um campo para o ID cargo ALTER TABLE Employees ADD PositionID int -- adiciona um campo para o ID departamento ALTER TABLE Employees ADD DepartmentID int
O tipo de campos de referência deve ser o mesmo das tabelas de referência, neste caso, é int.
Além disso, você pode adicionar vários campos usando um comando listando os campos separados por vírgulas:
ALTER TABLE Funcionários ADD PositionID int, DepartmentID int
Agora, adicionaremos restrições de referência (FOREIGN KEY) a esses campos, para que um usuário não possa adicionar valores que não sejam os valores de ID das tabelas de referência.
ALTER TABLE Funcionários ADICIONAR CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
Os mesmos passos devem ser feitos para o segundo campo:
ALTER TABLE Funcionários ADICIONAR CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Agora, os usuários só podem inserir nesses campos os valores de ID da tabela de referência correspondente. Assim, para utilizar um novo departamento ou cargo, o usuário deve adicionar um novo registro na tabela de referência correspondente. Como os cargos e departamentos são armazenados em tabelas de referência em uma cópia, para alterar seu nome, você precisa alterá-lo apenas na tabela de referência.
O nome de uma restrição de referência geralmente é composto. Consiste no prefixo «FK» seguido de um nome de tabela e um nome de campo que se refere ao identificador da tabela de referência.
O identificador (ID) geralmente é um valor interno usado apenas para links. Não importa o valor que tenha. Assim, não tente se livrar de lacunas na sequência de valores que aparecem quando você trabalha com a tabela, por exemplo, quando você exclui registros da tabela de referência.
Em alguns casos, é possível construir uma referência a partir de vários campos:
ALTER TABLE tabela ADD CONSTRAINT constraint_name FOREIGN KEY(campo1,campo2,…) REFERENCES tabela de referência(campo1,campo2,…)
Neste caso, uma chave primária é representada por um conjunto de vários campos (campo1, campo2, …) na tabela “reference_table”.
Agora, vamos atualizar os campos PositionID e DepartmentID com os valores de ID das tabelas de referência.
Para fazer isso, usaremos o comando UPDATE:
UPDATE e SET PositionID=(SELECT ID FROM Cargos WHERE Nome=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
Execute a seguinte consulta:
SELECIONAR * DE Funcionários
| ID | Nome | Aniversário | Posição | Departamento | ID da posição | DepartmentID | |
| 1000 | João | NULO | NULO | CEO | Administração | 2 | 1 |
| 1001 | Daniel | NULO | NULO | Programador | TI | 3 | 3 |
| 1002 | Mike | NULO | NULO | Contador | Departamento de contas | 1 | 2 |
| 1003 | Jordânia | NULO | NULO | Programador sênior | TI | 4 | 3 |
Como você pode ver, os campos PositionID e DepartmentID correspondem a cargos e departamentos. Assim, você pode excluir os campos Cargo e Departamento da tabela Funcionários executando o seguinte comando:
ALTER TABLE Funcionários DROP COLUMN Cargo,Departamento
Agora, execute esta declaração:
SELECIONAR * DE Funcionários
| ID | Nome | Aniversário | PositionID | DepartmentID | |
| 1000 | João | NULO | NULO | 2 | 1 |
| 1001 | Daniel | NULO | NULO | 3 | 3 |
| 1002 | Mike | NULO | NULO | 1 | 2 |
| 1003 | Jordânia | NULO | NULO | 4 | 3 |
Portanto, não temos sobrecarga de informações. Podemos definir os nomes de cargos e departamentos por seus identificadores usando os valores nas tabelas de referência:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departamentos d ON d.ID=e.DepartmentID LEFT JOIN Posições p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
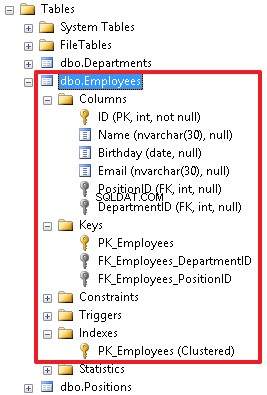
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
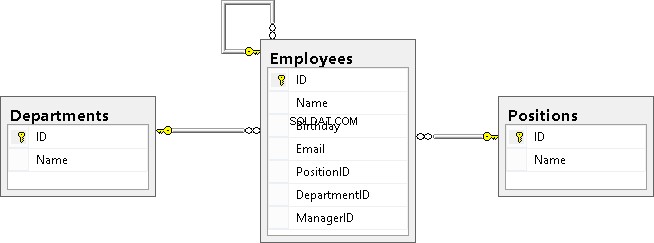
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ONINSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
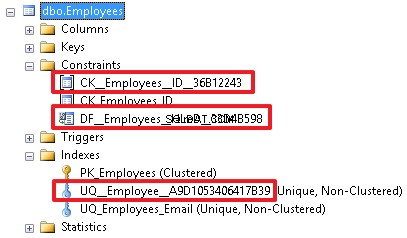
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
Resumo
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.