O foco deste artigo será a utilização de JOINs. Começaremos falando um pouco sobre como os JOINs vão acontecer e por que você precisa JOIN dados. Em seguida, vamos dar uma olhada nos tipos de JOIN que temos disponíveis e como usá-los.
PARTICIPAÇÃO BÁSICA
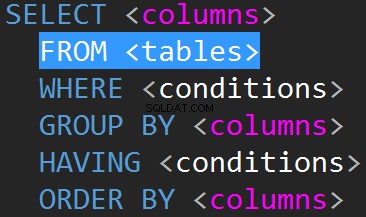
JOINs em TSQL normalmente serão feitos na linha FROM.
Antes de chegarmos a qualquer outra coisa, a verdadeira grande questão se torna – “Por que temos que fazer JOINs e como vamos realmente realizar nossos JOINs?”
Acontece que todos os bancos de dados com os quais trabalhamos terão seus dados divididos em várias tabelas. Há muitas razões diferentes para isso:
- Manter a integridade dos dados
- Economia de espaço armazenado
- Editar dados mais rapidamente
- Tornar as consultas mais flexíveis
Assim, todo banco de dados com o qual você trabalhará precisará que esses dados sejam unidos para que realmente façam sentido.
Por exemplo, você tem tabelas separadas para pedidos e para clientes. A pergunta que se torna – “Como conectamos todos os dados?” Isso é exatamente o que os JOINs vão fazer.
COMO FUNCIONAM AS LIGAÇÕES
Imagine o caso, quando temos duas mesas separadas e essas mesas serão reunidas criando uma costura.
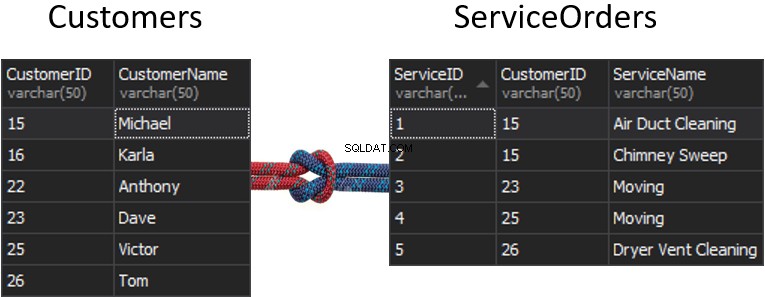
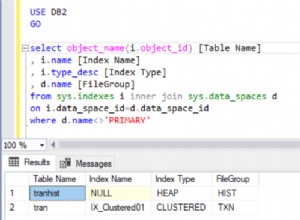
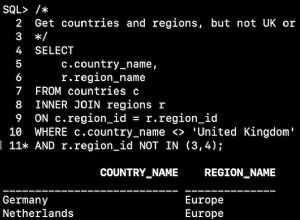
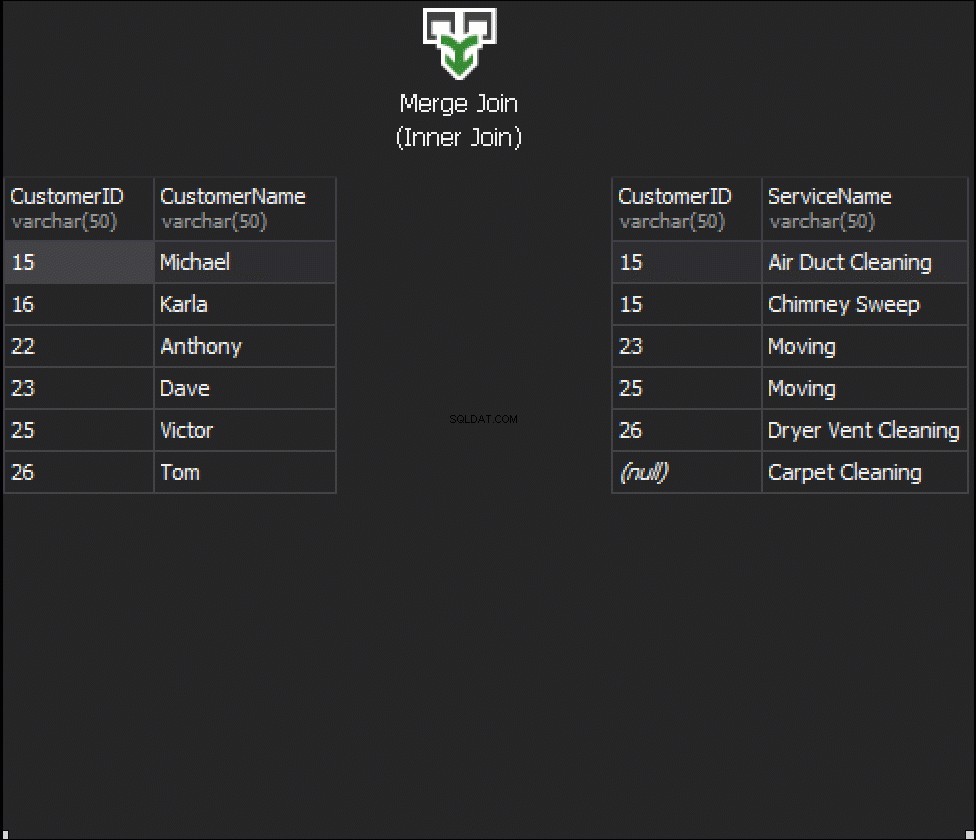
O que acontecerá com a emenda, se obtivermos uma coluna de cada tabela que será usada para correspondência, e isso determinará quais linhas serão ou não retornadas? Por exemplo, temos Clientes à esquerda e Pedidos de Serviço à direita. Se quisermos obter todos os clientes e seus pedidos, precisamos unir essas duas tabelas. Para isso, precisamos escolher uma coluna que funcionará como costura, e obviamente, claro, a coluna que vamos usar é CustomerID.
A propósito, o CustomerID é conhecido como Chave primária para a tabela à esquerda, que identifica exclusivamente cada linha dentro da tabela Customers.
Na tabela ServiceOrders, também temos a coluna CustomerID, conhecida como Foreign Key . Uma chave estrangeira é simplesmente uma coluna projetada para apontar para outra tabela. No nosso caso, está apontando de volta para a tabela Clientes. Portanto, é assim que vamos reunir todos esses dados, fornecendo essa costura.
Nessas tabelas, temos as seguintes correspondências:2 pedidos de 15 e 1 pedido de 23, 25 e 26. Ficam de fora 16 e 22.
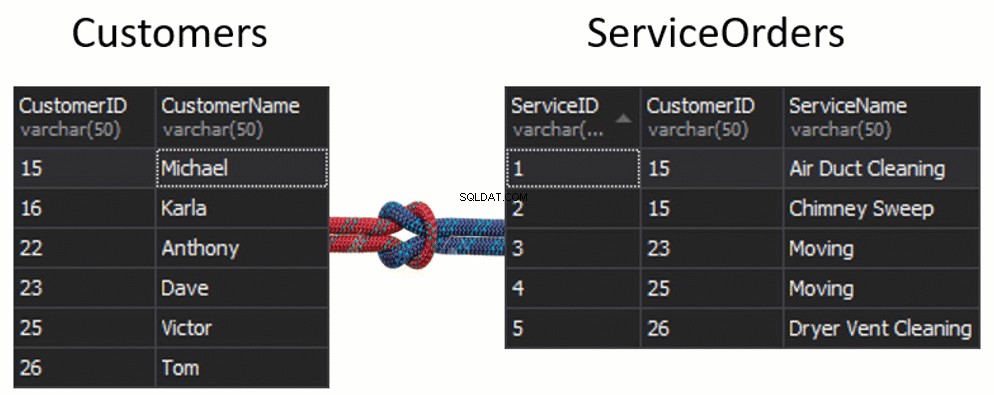
Uma coisa importante a ser observada aqui é que podemos JOIN em várias tabelas . Na verdade, é bastante comum JOIN várias tabelas juntas, a fim de obter qualquer forma de informação. Se você der uma olhada no banco de dados mais comum, você pode ter que JUNTAR quatro, cinco, seis e mais tabelas apenas para obter as informações que você está procurando. Ter um diagrama de banco de dados será útil.
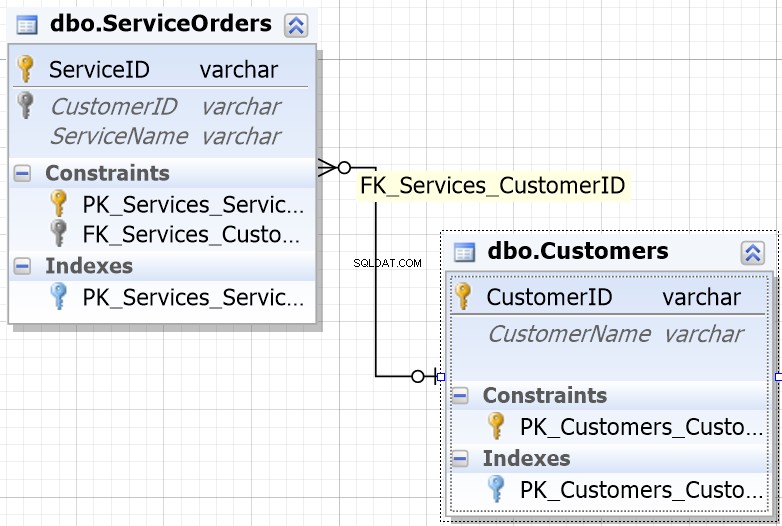
Para ajudá-lo na maioria dos ambientes de banco de dados, você notará que as colunas projetadas para serem unidas têm o mesmo nome.
SINTAXE DE PARTICIPAÇÃO
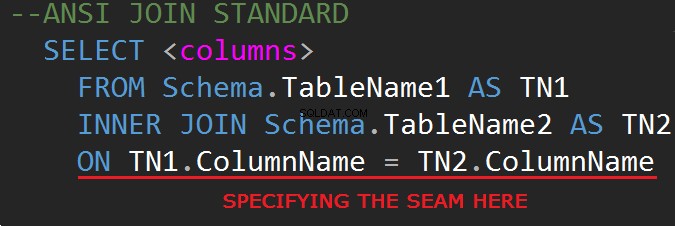
A terceira revisão da linguagem de consulta do banco de dados SQL (SQL-92) regula a sintaxe JOIN:
É possível fazer JOINs na linha WHERE:
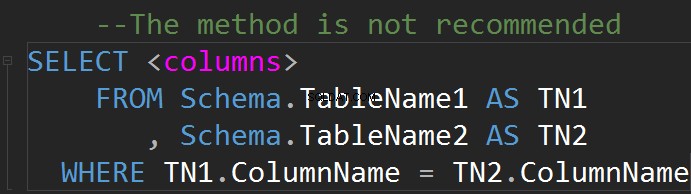
Uma relação geralmente tem uma interpretação gráfica simples na forma de uma tabela.
Práticas recomendadas e convenções
- Nomes de tabelas de alias.
- Usar nomenclatura de duas partes para colunas
- Coloque cada JOIN em uma linha separada
- Coloque as tabelas em uma ordem lógica
TIPOS DE PARTICIPAÇÃO
O SQL Server fornece os seguintes tipos de JOINs:
- INNER JOIN
- JUNÇÃO EXTERNA
- AUTO PARTICIPAR
- CROSS JOIN
Para mais informações sobre o tema, fique à vontade para conferir este artigo sobre os tipos de joins no SQL Server e saiba como é fácil escrever tais consultas com a ajuda do SQL Complete.
INNER JOIN
O primeiro tipo de JOINs que podemos querer executar é o INNER JOIN. Normalmente, os autores se referem a esse tipo de JOINs do SQL Server como JOIN regular ou simples. Eles apenas omitem o prefixo INNER. Esse tipo de JOIN combina duas tabelas e somente retorna linhas de ambos os lados que correspondem .
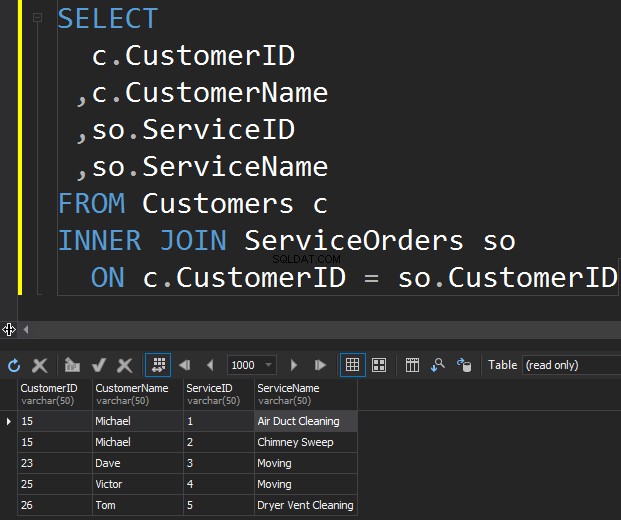
Não vemos Klara e Anthony aqui porque seu CustomerID não corresponde em ambas as tabelas. Também quero destacar o fato de que a operação JOIN retorna um cliente sempre que corresponde ao pedido . Há dois pedidos para Michael e um pedido para Dave, Victor e Tom cada.
Resumo:
- INNER JOIN retorna linhas somente quando há pelo menos uma linha em ambas as tabelas que corresponde à condição JOIN.
- INNER JOIN elimina as linhas que não correspondem a uma linha da outra tabela
JUNÇÃO EXTERNA
Os JOINs externos são diferentes porque retornam linhas de tabelas ou exibições, mesmo que não correspondam. Esse tipo de JOIN é útil se você precisar recuperar todos os clientes que nunca fizeram um pedido. Ou, por exemplo, se procura um produto que nunca foi encomendado.
A maneira como fazemos nossos OUTER JOINs é indicando LEFT ou RIGHT, ou FULL.
Não há diferenças entre as seguintes cláusulas:
- LEFT OUTER JOIN =LEFT JOIN
- RIGHT OUTER JOIN =RIGHT JOIN
- FULL OUTER JOIN =FULL JOIN
No entanto, eu recomendaria escrever a cláusula completa porque torna o código mais legível.
Usando LEFT OUTER JOIN
Não há diferença entre LEFT ou RIGHT, exceto o fato de que apenas apontamos a tabela da qual queremos obter as linhas extras. No exemplo a seguir, listamos os clientes e seus pedidos. Utilizamos a ESQUERDA para obter todos os clientes que nunca fizeram pedidos. Pedimos ao SQL Server para obter linhas extras da tabela à esquerda.
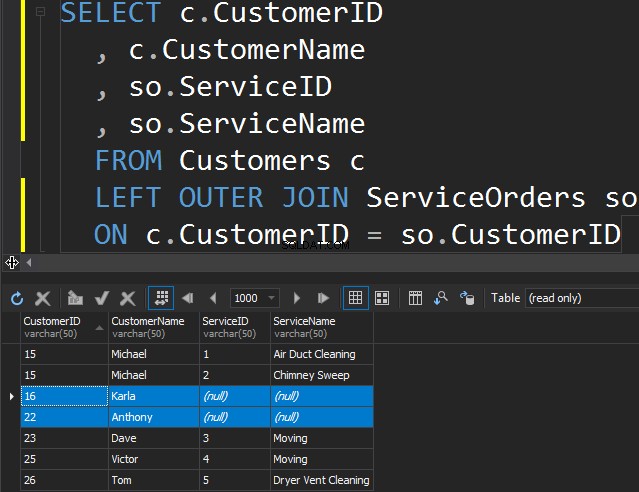
Observe que Karla e Anthony não fizeram nenhum pedido e, como resultado, obtemos valores NULL para ServiceName e ServiceID. O SQL Server não sabe o que colocar lá e coloca NULLs.
Usando RIGHT OUTER JOIN
Para obter o serviço menos popular da tabela ServiceOrders, precisamos usar a direção DIREITA.
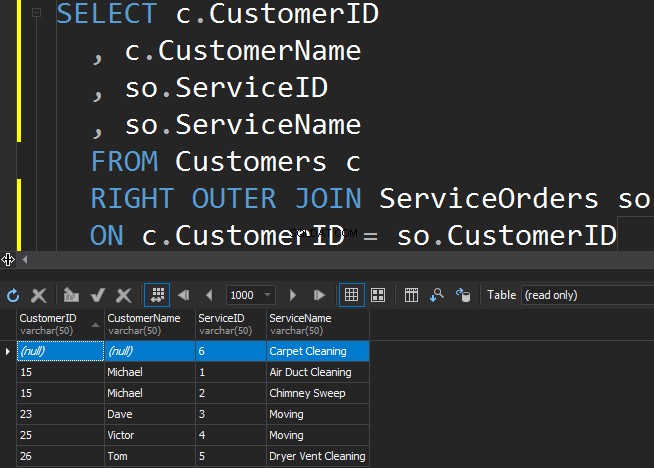
Vemos que, nesse caso, o SQL Server retornou linhas extras da tabela correta e o serviço de limpeza de carpetes nunca foi solicitado.
Usando FULL OUTER JOIN
Esse tipo de JOIN permite que você obtenha as informações não correspondentes incluindo linhas não correspondentes de ambas as tabelas.
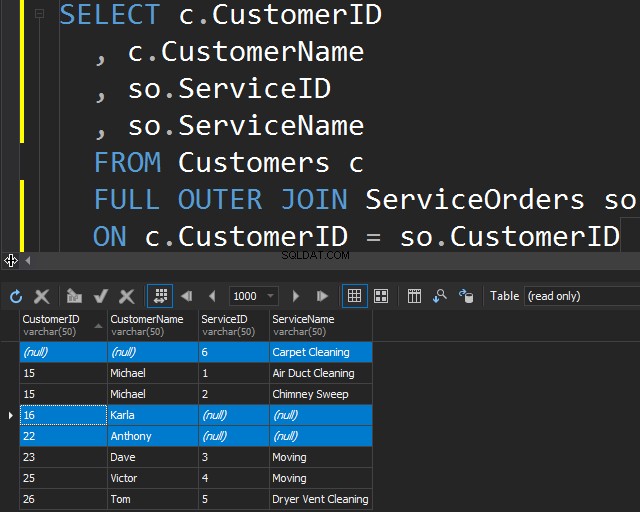
Isso também pode ser útil se você precisar fazer uma limpeza de dados.
Resumo:
JUNÇÃO EXTERNA COMPLETA
- Retorna linhas de ambas as tabelas, mesmo que não correspondam à instrução JOIN
Esquerda ou direita
- Nenhuma diferença, exceto na ordem das tabelas na cláusula FROM
- Pontos de direção em uma tabela para recuperar linhas não correspondentes
AUTO PARTICIPAR
O próximo tipo de JOINs que temos é SELF JOIN. Este é provavelmente o segundo tipo menos comum de JOIN que você irá executar. Um SELF JOIN é quando você está juntando uma tabela em si mesma. De um modo geral, isso é um sinal de design ruim. Para usar a mesma tabela duas vezes em uma única consulta, a tabela deve ter um alias. O alias ajuda o processador de consultas a identificar se as colunas devem apresentar dados do lado direito ou esquerdo. Além disso, você precisa eliminar as filas que marcham sozinhas. Isso geralmente é feito com uma junção não-equi.
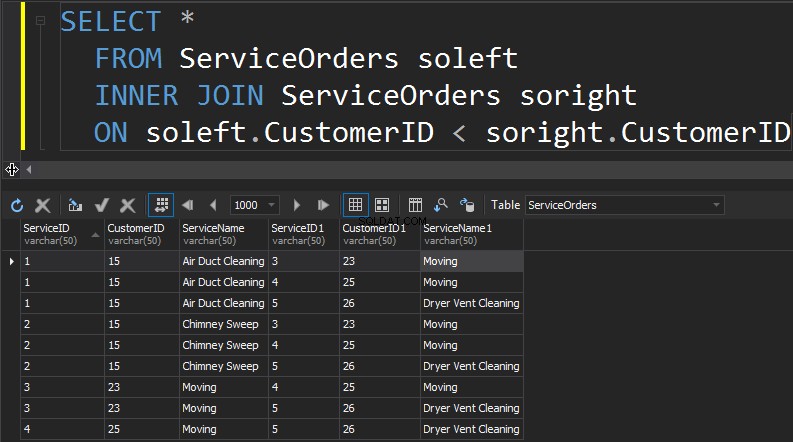
Resumo:
- Junta uma tabela a si mesma
- Geralmente um sinal de design e normalização ruins
- As tabelas devem ter alias
- Precisa filtrar linhas que correspondam a si mesmas
JUNÇÕES CRUZADAS
Este tipo de JOINs não tem o ON demonstração. Cada linha de cada tabela vai corresponder. Isso também é conhecido como Produto Cartesiano (caso um CROSS JOIN não tenha uma cláusula WHERE). Dificilmente você usará esse tipo de JOIN em cenários do mundo real, no entanto, é uma boa maneira de gerar dados de teste.
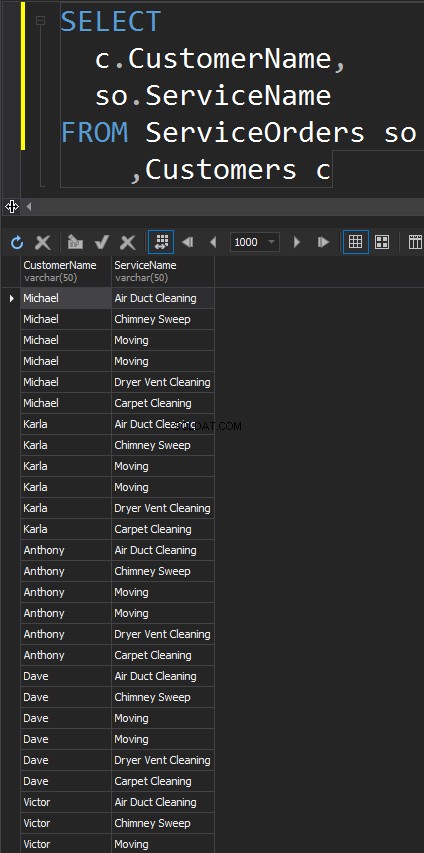
O resultado é um conjunto de dados, onde o número de linhas na tabela esquerda é multiplicado pelo número de linhas na tabela direita. Eventualmente, vemos que cada cliente corresponde a cada serviço.
Obtemos o mesmo resultado ao usar a cláusula CROSS JOIN explicitamente.
Resumo:
- Todas as linhas correspondem a cada tabela
- Sem declaração ON
- Pode ser usado para gerar dados de teste
UNIR ALGORITMOS
Na primeira parte do artigo, discutimos lógico Operadores JOIN que o SQL Server usa durante a análise e associação de consultas. Eles estão:
- INNER JOIN
- JUNÇÃO EXTERNA
- CROSS JOIN
Os operadores lógicos são conceituais e diferem dos físicos JOINs. Caso contrário, os JOINs lógicos não se unem colunas de tabela específicas. Um único JOIN lógico pode corresponder a muitos JOINs físicos. O SQL Server substitui JOINs lógicos por JOINs físicos durante a otimização. O SQL Server tem os seguintes operadores físicos de JOIN:
- LOOP Aninhado
- MERGURAR
- HASH
Um usuário não grava ou usa esses tipos de JOINS. Eles fazem parte do mecanismo do SQL Server e o SQL Server os usa internamente para implementar JOINs lógicos. Ao explorar o plano de execução, você pode observar que o SQL Server substitui os operadores lógicos JOIN por um dos três operadores físicos.
União de loop aninhado
Vamos começar com o operador mais simples, que é o Nested Loop. O algoritmo compara cada linha de uma tabela (tabela externa) com cada linha da outra tabela (tabela interna) procurando linhas que atendam ao predicado JOIN.
O pseudocódigo a seguir descreve o algoritmo de loop de junção aninhado interno:

O pseudocódigo a seguir descreve o algoritmo de loop de junção aninhado externo:
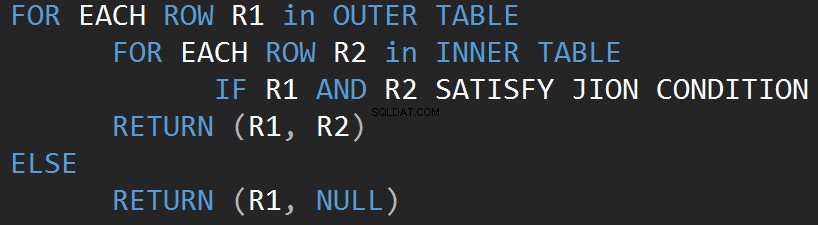
O tamanho da entrada afeta diretamente o custo do algoritmo. O insumo cresce o custo cresce também. Este tipo de algoritmo JOIN é eficiente no caso de entrada pequena. O SQL Server estima um predicado JOIN para cada linha em ambas as entradas.
Considere a consulta a seguir como exemplo, que obtém clientes e seus pedidos.
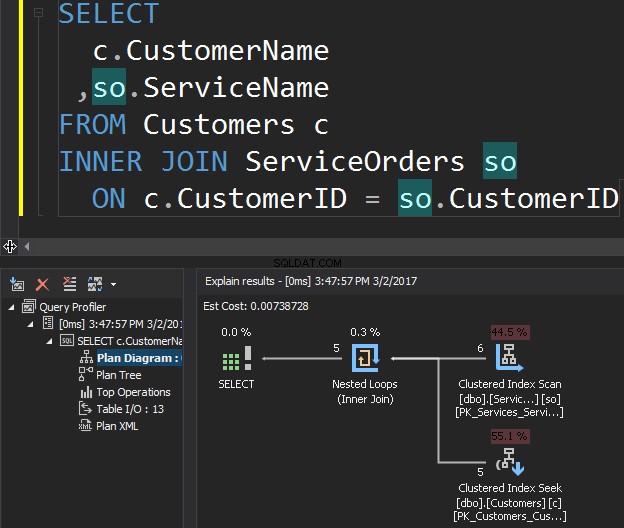
O operador Clustered Index Scan é a entrada externa e a Busca de Índice Agrupado é a entrada interna . O operador Nested Loop, na verdade, encontra correspondência. O operador procura cada registro na entrada externa e encontra as linhas correspondentes na entrada interna. O SQL Server executa a operação Clustered Index Scan (entrada externa) apenas uma vez para obter todos os registros relevantes. Clustered Index Seek é executado para cada registro da entrada externa. Para confirmar isso, navegue o cursor até o ícone do operador e examine a dica de ferramenta.
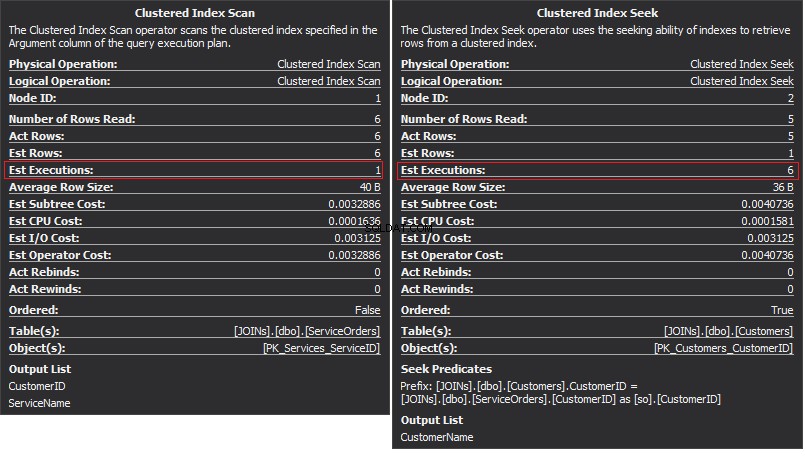
Vamos falar sobre a complexidade. Suponha N é o número da linha para a saída externa. M é o número total da linha em SalesOrders tabela. Assim, a complexidade da consulta é O(NLogM) onde LogM é a complexidade de cada busca na entrada interna. O otimizador selecionará este operador toda vez que a entrada externa for pequena e a entrada interna contiver um índice na coluna que atua como costura. Portanto, índices e estatísticas são essenciais para esse tipo de JOIN, caso contrário, o SQL Server pode pensar acidentalmente que não há tantas linhas em uma das entradas. É melhor executar uma varredura de tabela em vez de executar a Busca de Índice 100K vezes. Especialmente quando o tamanho da entrada interna é superior a 100K.
Resumo:
Loops aninhados
- Complexidade:O(NlogM)
- Aplicado geralmente quando uma tabela é pequena
- A tabela maior contém um índice que permite procurá-lo usando a chave de junção
Mesclar associação
Alguns desenvolvedores não entendem completamente os JOINs de Hash e Merge e frequentemente os associam a consultas de baixo desempenho.
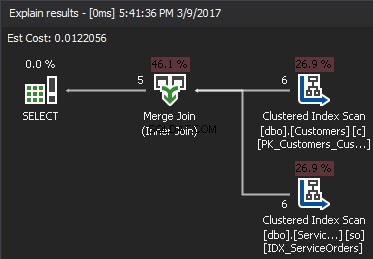
Ao contrário do Nested Loop que aceita qualquer predicado JOIN, o Merge Join requer pelo menos um equi join. Além disso, ambas as entradas devem ser classificadas nas teclas JOIN.
O pseudo-código para o algoritmo MERGE JOIN:
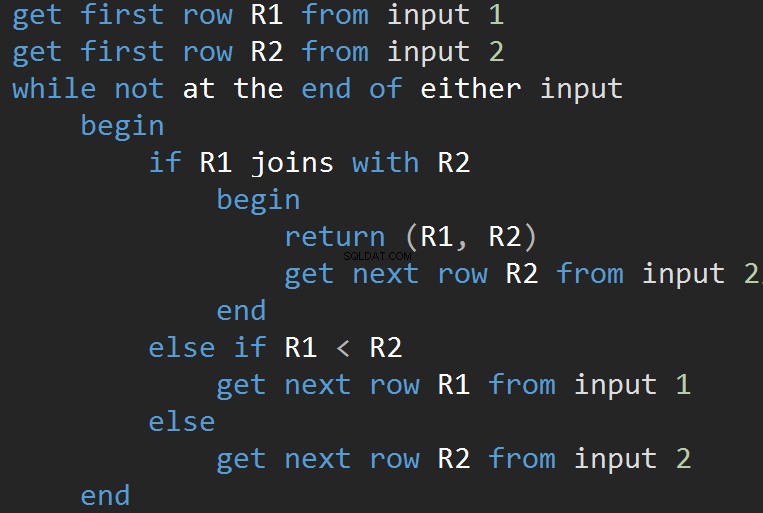
O algoritmo compara duas entradas classificadas. Uma fileira de cada vez. Caso haja uma igualdade entre duas linhas, o algoritmo gera as saídas de junção de linhas e continua. Caso contrário, o algoritmo descarta a menor das duas entradas e continua. Ao contrário do Nested Loop, o custo aqui é proporcional à soma do número de linhas de entrada. Em termos de complexidade – O(N+M). Portanto, esse tipo de JOIN geralmente é melhor para grandes entradas.
A animação a seguir demonstra como o algoritmo MERGE JOIN realmente une as linhas da tabela.
Resumo
- Complexidade:O(N+M)
- Ambas as entradas devem ser classificadas na chave de junção
- Um operador de igualdade é usado
- Excelente para mesas grandes
União de hash
Hash Join é adequado para tabelas grandes sem índice utilizável. Na primeira etapa – fase de construção o algoritmo cria um índice de hash na memória na entrada do lado esquerdo. A segunda etapa é chamada de fase de sondagem . O algoritmo passa pela entrada do lado direito e encontra correspondências usando o índice criado durante a fase de construção. Se for verdade, não é um bom sinal quando o otimizador escolhe esse tipo de algoritmo JOIN.
Existem dois conceitos importantes subjacentes a este tipo de JOINs:Função Hash e Tabela Hash.
Uma função de hash é qualquer função que pode ser usada para mapear dados de tamanho variável para dados de tamanho fixo.
Uma tabela de hash é uma estrutura de dados usada para implementar uma matriz associativa, uma estrutura que pode mapear chaves para valores. Uma tabela de hash usa uma função de hash para calcular um índice em uma matriz de buckets ou slots, a partir dos quais o valor desejado pode ser encontrado.
Com base nas estatísticas disponíveis, o SQL Server escolhe a menor entrada como entrada de compilação e a usa para criar uma tabela de hash na memória. Se não houver memória suficiente, o SQL Server usará espaço em disco físico no TempDB. Depois que a tabela de hash é criada, o SQL Server obtém os dados da entrada do probe (tabela maior) e os compara com a tabela de hash usando uma função de correspondência de hash. Como resultado, ele retorna as linhas correspondentes.
Se observarmos o plano de execução, o elemento superior direito é a entrada de construção , e o elemento inferior direito é a entrada de sonda . Caso ambos os insumos sejam extremamente grandes, o custo é muito alto.
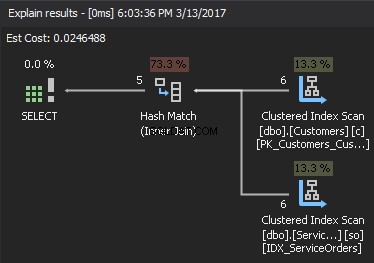
Para estimar a complexidade, suponha o seguinte:
hc – complexidade da criação da tabela de hash
hm – complexidade da função de correspondência de hash
N - mesa menor
M - mesa maior
J – adição de complexidade para o cálculo dinâmico e criação da função hash
A complexidade será:O(N*hc + M*hm + J)
O otimizador usa estatísticas para determinar a cardinalidade do valor. Em seguida, ele cria dinamicamente uma função de hash que divide os dados em vários buckets com tamanhos iguais. Muitas vezes é difícil estimar a complexidade do processo de criação da tabela de hash, bem como a complexidade de cada correspondência de hash devido à natureza dinâmica. O plano de execução pode até apresentar estimativas incorretas porque o otimizador realiza todas essas operações dinâmicas durante o tempo de execução. Em alguns casos, o plano de execução pode mostrar que o Nested Loop é mais caro que o Hash Join, mas, na verdade, o Hash Join é executado mais lentamente devido à estimativa de custo incorreta.
Resumo
- Complexidade:O(N*hc +M*hm +J)
- Tipo de associação de último recurso
- Usa uma tabela de hash e uma função de correspondência de hash dinâmica para corresponder linhas
Produtos úteis:
SQL Complete – escreva, embeleze, refatore seu código facilmente e aumente sua produtividade.