Você já deve ter ouvido falar sobre o termo “cérebro dividido”. O que é isso? Como isso afeta seus clusters? Nesta postagem do blog, discutiremos o que exatamente é, que perigo pode representar para seu banco de dados, como podemos evitá-lo e, se tudo der errado, como se recuperar dele.
Longe vão os dias das instâncias únicas, hoje em dia quase todos os bancos de dados são executados em grupos ou clusters de replicação. Isso é ótimo para alta disponibilidade e escalabilidade, mas um banco de dados distribuído apresenta novos perigos e limitações. Um caso que pode ser mortal é uma divisão de rede. Imagine um cluster de vários nós que, devido a problemas de rede, foi dividido em duas partes. Por razões óbvias (consistência de dados), ambas as partes não devem lidar com o tráfego ao mesmo tempo, pois estão isoladas uma da outra e os dados não podem ser transferidos entre elas. Também está errado do ponto de vista do aplicativo - mesmo que, eventualmente, haja uma maneira de sincronizar os dados (embora a reconciliação de 2 conjuntos de dados não seja trivial). Por um tempo, parte do aplicativo não saberia das alterações feitas por outros hosts de aplicativos, que acessam a outra parte do cluster de banco de dados. Isso pode levar a problemas sérios.
A condição na qual o cluster foi dividido em duas ou mais partes que estão dispostas a aceitar gravações é chamada de “split brain”.
O maior problema com o cérebro dividido é a deriva de dados, pois as gravações acontecem em ambas as partes do cluster. Nenhum dos sabores do MySQL fornece meios automatizados de mesclar conjuntos de dados que divergiram. Você não encontrará esse recurso na replicação do MySQL, replicação de grupo ou Galera. Uma vez que os dados divergiram, a única opção é usar uma das partes do cluster como fonte de verdade e descartar as alterações executadas na outra parte - a menos que possamos seguir algum processo manual para mesclar os dados.
É por isso que começaremos com como evitar que o cérebro dividido aconteça. Isso é muito mais fácil do que ter que corrigir qualquer discrepância de dados.
Como prevenir o cérebro dividido
A solução exata depende do tipo de banco de dados e da configuração do ambiente. Vamos dar uma olhada em alguns dos casos mais comuns para Galera Cluster e MySQL Replication.
Conjunto Galera
O Galera possui um “disjuntor” embutido para lidar com o cérebro dividido:ele depende de um mecanismo de quorum. Se a maioria (50% + 1) dos nós estiver disponível no cluster, o Galera funcionará normalmente. Se não houver maioria, o Galera deixará de atender ao tráfego e mudará para o chamado estado “não primário”. Isso é praticamente tudo o que você precisa para lidar com uma situação de cérebro dividido ao usar o Galera. Claro, existem métodos manuais para forçar o Galera ao estado “Primário”, mesmo que não haja maioria. A coisa é, a menos que você faça isso, você deve estar seguro.
A maneira como o quorum é calculado tem repercussões importantes - em um único nível de datacenter, você deseja ter um número ímpar de nós. Três nós fornecem uma tolerância para a falha de um nó (2 nós atendem ao requisito de mais de 50% dos nós no cluster estarem disponíveis). Cinco nós lhe darão uma tolerância para falha de dois nós (5 - 2 =3 que é mais de 50% de 5 nós). Por outro lado, usar quatro nós não melhorará sua tolerância em um cluster de três nós. Ele ainda trataria apenas uma falha de um nó (4 - 1 =3, mais de 50% de 4), enquanto a falha de dois nós tornaria o cluster inutilizável (4 - 2 =2, apenas 50%, não mais).
Ao implantar o cluster Galera em um único datacenter, lembre-se de que, idealmente, você gostaria de distribuir nós em várias zonas de disponibilidade (fonte de energia separada, rede etc.) - desde que existam em seu datacenter, ou seja, . Uma configuração simples pode ter a seguinte aparência:
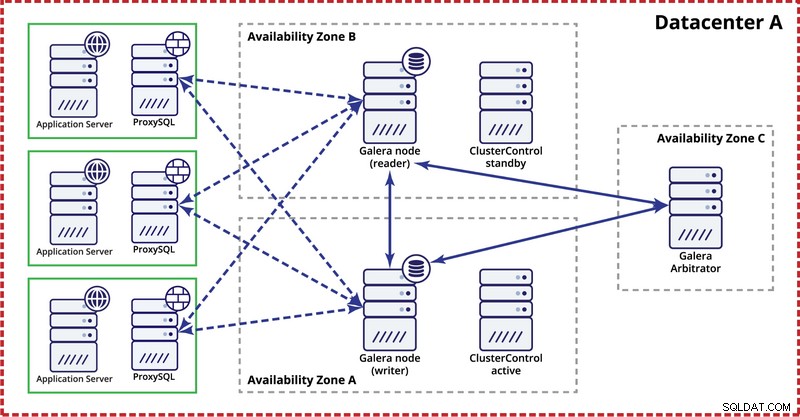
No nível de vários datacenters, essas considerações também são aplicáveis. Se você deseja que o cluster Galera lide automaticamente com falhas de datacenter, você deve usar um número ímpar de datacenters. Para reduzir custos, você pode usar um árbitro Galera em um deles em vez de um nó de banco de dados. O árbitro Galera (garbd) é um processo que participa do cálculo do quorum, mas não contém dados. Isso torna possível usá-lo mesmo em instâncias muito pequenas, pois não consome muitos recursos - embora a conectividade de rede tenha que ser boa, pois "vê" todo o tráfego de replicação. A configuração de exemplo pode se parecer com um diagrama abaixo:
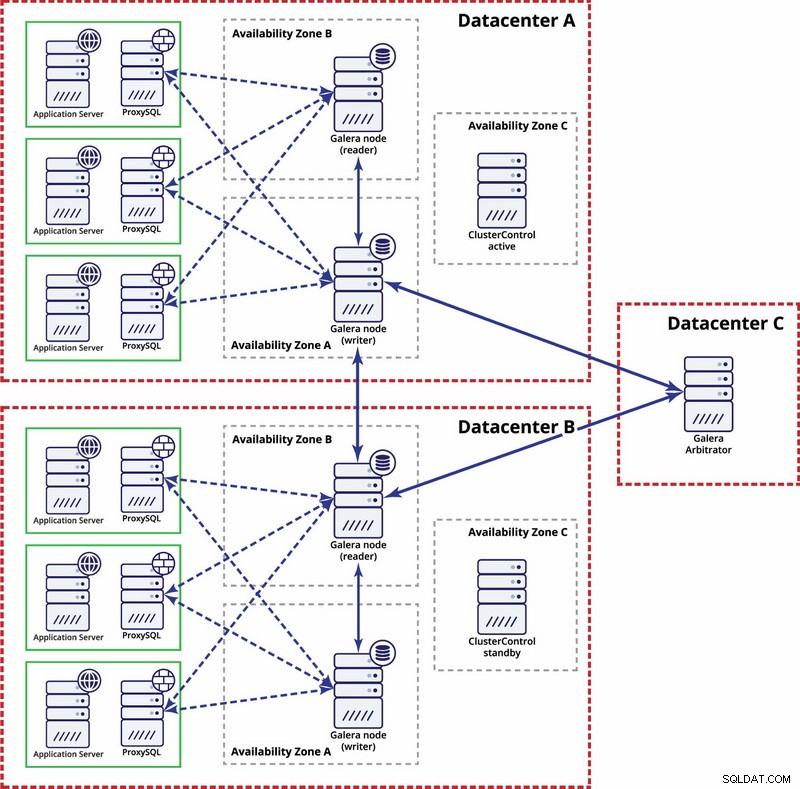
Replicação MySQL
Com a replicação do MySQL, o maior problema é que não há um mecanismo de quorum embutido, como no cluster Galera. Portanto, mais etapas são necessárias para garantir que sua configuração não seja afetada por um cérebro dividido.
Um método é evitar failovers automatizados entre datacenters. Você pode configurar sua solução de failover (pode ser por meio do ClusterControl, MHA ou Orchestrator) para failover apenas em um único datacenter. Se houvesse uma interrupção total do datacenter, caberia ao administrador decidir como fazer o failover e como garantir que os servidores no datacenter com falha não serão usados.
Existem opções para torná-lo mais automatizado. Você pode usar o Consul para armazenar dados sobre os nós na configuração de replicação e qual deles é o mestre. Em seguida, caberá ao administrador (ou por meio de algum script) atualizar essa entrada e mover as gravações para o segundo datacenter. Você pode se beneficiar de uma configuração de orquestrador/raft em que os nós do orquestrador podem ser distribuídos em vários datacenters e detectar cérebro dividido. Com base nisso, você pode realizar diferentes ações como, como mencionamos anteriormente, atualizar entradas em nosso Consul ou etcd. A questão é que este é um ambiente muito mais complexo para configurar e automatizar do que o cluster Galera. Abaixo, você pode encontrar um exemplo de configuração de vários datacenters para replicação do MySQL.
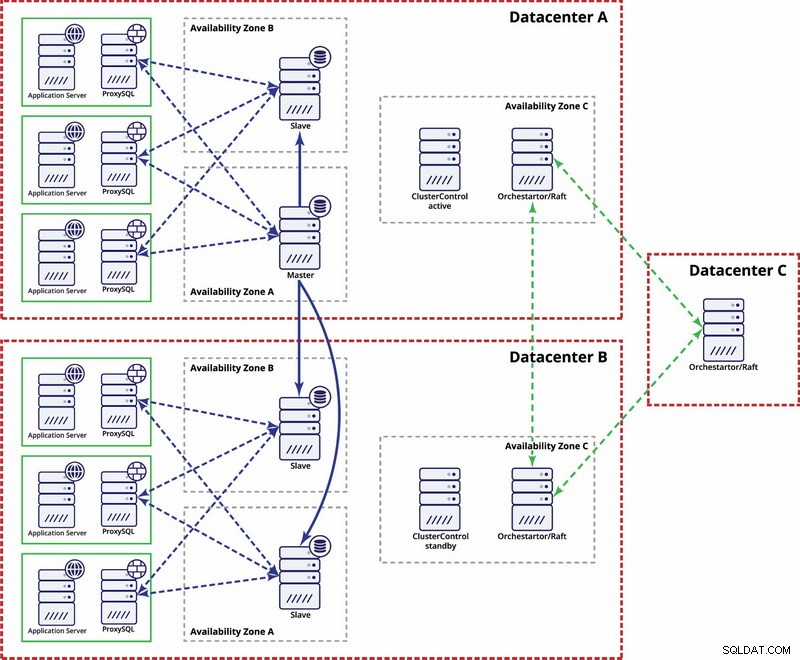
Lembre-se de que você ainda precisa criar scripts para fazê-lo funcionar, ou seja, monitorar os nós do orquestrador para um cérebro dividido e tomar as ações necessárias para implementar o STONITH e garantir que o mestre no datacenter A não seja usado quando a rede convergir e a conectividade for ser restaurado.
Aconteceu o cérebro dividido - O que fazer a seguir?
O pior cenário aconteceu e temos um desvio de dados. Vamos tentar dar algumas dicas do que pode ser feito aqui. Infelizmente, as etapas exatas dependerão principalmente do design do esquema, portanto, não será possível escrever um guia de instruções preciso.
O que você deve ter em mente é que o objetivo final será copiar os dados de um mestre para o outro e recriar todas as relações entre as tabelas.
Antes de tudo, você precisa identificar qual nó continuará servindo dados como mestre. Este é um conjunto de dados ao qual você mesclará os dados armazenados na outra instância “mestre”. Feito isso, você deve identificar os dados do mestre antigo que estão faltando no mestre atual. Este será um trabalho manual. Se você tiver carimbos de data/hora em suas tabelas, poderá aproveitá-los para identificar os dados ausentes. Em última análise, os logs binários conterão todas as modificações de dados para que você possa confiar neles. Você também pode ter que confiar em seu conhecimento da estrutura de dados e das relações entre as tabelas. Se seus dados forem normalizados, um registro em uma tabela pode estar relacionado a registros em outras tabelas. Por exemplo, seu aplicativo pode inserir dados na tabela “user” relacionada à tabela “address” usando user_id. Você terá que encontrar todas as linhas relacionadas e extraí-las.
O próximo passo será carregar esses dados no novo mestre. Aqui vem a parte complicada - se você preparou suas configurações de antemão, isso pode ser simplesmente uma questão de executar algumas inserções. Se não, isso pode ser bastante complexo. É tudo sobre chave primária e valores de índice exclusivos. Se seus valores de chave primária são gerados como únicos em cada servidor usando algum tipo de gerador de UUID ou usando as configurações auto_increment_increment e auto_increment_offset no MySQL, você pode ter certeza de que os dados do antigo mestre que você precisa inserir não causarão chave primária ou exclusiva conflito de chave com dados no novo mestre. Caso contrário, pode ser necessário modificar manualmente os dados do mestre antigo para garantir que eles possam ser inseridos corretamente. Parece complexo, então vamos dar uma olhada em um exemplo.
Vamos imaginar que inserimos linhas usando auto_increment no nó A, que é um mestre. Por uma questão de simplicidade, vamos nos concentrar apenas em uma única linha. Existem colunas 'id' e 'valor'.
Se o inserirmos sem nenhuma configuração específica, veremos entradas como abaixo:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Aqueles serão replicados para o escravo (B). Se o cérebro dividido acontecer e as gravações forem executadas no mestre antigo e no novo, terminaremos com a seguinte situação:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Como você pode ver, não há como simplesmente despejar registros com id de 1004, 1005 e 1006 do nó A e armazená-los no nó B porque terminaremos com entradas de chave primária duplicadas. O que precisa ser feito é alterar os valores da coluna id nas linhas que serão inseridas para um valor maior que o valor máximo da coluna id da tabela. Isso é tudo o que é necessário para linhas únicas. Para relações mais complexas, onde várias tabelas estão envolvidas, talvez seja necessário fazer as alterações em vários locais.
Por outro lado, se tivéssemos antecipado esse problema em potencial e configurado nossos nós para armazenar ids ímpares no nó A e ids pares no nó B, o problema teria sido muito mais fácil de resolver.
O nó A foi configurado com auto_increment_offset =1 e auto_increment_increment =2
O nó B foi configurado com auto_increment_offset =2 e auto_increment_increment =2
É assim que os dados ficariam no nó A antes do cérebro dividido:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Quando o cérebro dividido aconteceu, será como abaixo.
Nó A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Nó B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Agora podemos copiar facilmente os dados ausentes do nó A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’E carregue-o no nó B terminando com o seguinte conjunto de dados:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Claro, as linhas não estão na ordem original, mas isso deve estar correto. Na pior das hipóteses, você terá que ordenar pela coluna 'valor' nas consultas e talvez adicionar um índice nela para tornar a classificação mais rápida.
Agora, imagine centenas ou milhares de linhas e uma estrutura de tabela altamente normalizada - restaurar uma linha pode significar que você terá que restaurar várias delas em tabelas adicionais. Com a necessidade de alterar os id's (porque você não tinha configurações de proteção) em todas as linhas relacionadas e tudo isso sendo um trabalho manual, você pode imaginar que essa não é a melhor situação para se estar. é um processo propenso a erros. Felizmente, como discutimos no início, existem meios para minimizar as chances de que o cérebro dividido afete seu sistema ou para reduzir o trabalho que precisa ser feito para sincronizar de volta seus nós. Certifique-se de usá-los e fique preparado.