Um dos recursos interessantes do Galera é o provisionamento automático de nós e o controle de associação. Se um nó falhar ou perder a comunicação, ele será automaticamente despejado do cluster e permanecerá inoperante. Enquanto a maioria dos nós ainda estiver se comunicando (o Galera chama esse PC de componente primário), há uma chance muito alta de que o nó com falha possa se juntar novamente, ressincronizar e retomar a replicação assim que a conectividade estiver de volta.
Geralmente, todos os nós Galera são iguais. Eles possuem o mesmo conjunto de dados e a mesma função dos mestres, capazes de lidar com leitura e gravação simultaneamente, graças à comunicação do grupo Galera e ao plug-in de replicação baseado em certificação. Portanto, na verdade não há failover do ponto de vista do banco de dados devido a esse equilíbrio. Somente do lado do aplicativo que exigiria failover, para ignorar os nós não operacionais enquanto o cluster é particionado.
Nesta postagem do blog, vamos entender como o Galera Cluster executa a recuperação de nó e cluster no caso de ocorrer partição de rede. Apenas como uma nota lateral, abordamos um tópico semelhante nesta postagem do blog há algum tempo. Codership explicou o conceito de recuperação do Galera em grandes detalhes na página de documentação, Node Failure and Recovery.
Falha e remoção do nó
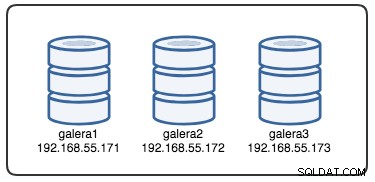
Para entender a recuperação, primeiro precisamos entender como o Galera detecta a falha do nó e o processo de despejo. Vamos colocar isso em um cenário de teste controlado para que possamos entender melhor o processo de despejo. Suponha que tenhamos um Galera Cluster de três nós, conforme ilustrado abaixo:
O comando a seguir pode ser usado para recuperar nossas opções de provedor Galera:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GÉ uma lista longa, mas precisamos apenas nos concentrar em alguns dos parâmetros para explicar o processo:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Em primeiro lugar, o Galera segue a formatação ISO 8601 para representar a duração. P1D significa que a duração é de um dia, enquanto PT15S significa que a duração é de 15 segundos (observe o designador de tempo, T, que precede o valor de tempo). Por exemplo, se alguém quiser aumentar evs.view_forget_timeout para 1 dia e meio, seria definido P1DT12H, ou PT36H.
Considerando que todos os hosts não foram configurados com nenhuma regra de firewall, usamos o seguinte script chamado block_galera.sh na galera2 para simular uma falha de rede de/para este nó:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateAo executar o script, obtemos a seguinte saída:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018O timestamp relatado pode ser considerado como o início do particionamento do cluster, onde perdemos a galera2, enquanto a galera1 e a galera3 ainda estão online e acessíveis. Neste ponto, nossa arquitetura Galera Cluster está parecida com isto:
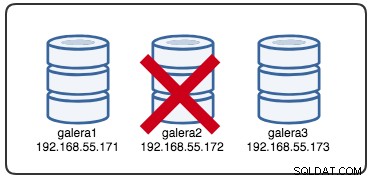
Da perspectiva do nó particionado
Na galera2, você verá algumas impressões dentro do log de erros do MySQL. Vamos dividi-los em várias partes. O tempo de inatividade começou por volta das 16:46:02, horário UTC, e após gmcast.peer_timeout=PT3S , aparece o seguinte:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Como passou evs.suspect_timeout =PT5S , ambos os nós galera1 e galera3 são suspeitos de mortos pela galera2:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveEm seguida, o Galera revisará a visualização do cluster atual e a posição deste nó:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})Com a nova visualização de cluster, o Galera realizará o cálculo de quorum para decidir se este nó faz parte do componente primário. Se o novo componente ver "primary =no", o Galera rebaixará o estado do nó local de SYNCED para OPEN:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Com a última alteração na visualização do cluster e no estado do nó, o Galera retorna a visualização do cluster pós-remoção e o estado global conforme abaixo:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Você pode ver o seguinte status global da galera2 mudou durante este período:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+Neste ponto, o servidor MySQL/MariaDB na galera2 ainda está acessível (o banco de dados está escutando em 3306 e Galera em 4567) e você pode consultar as tabelas do sistema mysql e listar os bancos de dados e tabelas. No entanto, quando você entra nas tabelas que não são do sistema e faz uma consulta simples como esta:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useVocê receberá imediatamente um erro indicando que o WSREP está carregado, mas não está pronto para uso por este nó, conforme relatado por wsrep_ready status. Isso ocorre porque o nó perde sua conexão com o Componente Primário e entra no estado não operacional (o status do nó local foi alterado de SYNCED para OPEN). As leituras de dados de nós em um estado não operacional são consideradas obsoletas, a menos que você defina wsrep_dirty_reads=ON para permitir leituras, embora o Galera ainda rejeite qualquer comando que modifique ou atualize o banco de dados.
Por fim, Galera continuará ouvindo e se reconectando a outros membros em segundo plano infinitamente:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60O fluxo do processo de despejo pela comunicação do grupo Galera para o nó particionado durante o problema de rede pode ser resumido conforme abaixo:
- Desconecta-se do cluster após gmcast.peer_timeout .
- Suspeita de outros nós após evs.suspect_timeout .
- Recupera a nova visualização de cluster.
- Realiza o cálculo de quorum para determinar o estado do nó.
- Rebaixa o nó de SYNCED para OPEN.
- Tenta se reconectar ao componente principal (outros nós do Galera) em segundo plano.
Da perspectiva do componente primário
Na galera1 e na galera3 respectivamente, depois de gmcast.peer_timeout=PT3S , o seguinte aparecerá no log de erros do MySQL:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Depois que passou evs.suspect_timeout =PT5S , galera2 é suspeito de morto pela galera3 (e galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera verifica se os outros nós respondem à comunicação do grupo na galera3, descobre que a galera1 está em estado primário e estável:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera revisa a visualização de cluster deste nó (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera então remove o nó particionado do Componente Primário:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)O novo Componente Primário agora consiste em dois nós, galera1 e galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2O Componente Primário trocará o estado entre si para concordar com a nova visualização do cluster e o estado global:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera calcula e verifica o quórum da troca de estados entre os membros online:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera atualiza a nova visualização de cluster e estado global após o despejo da galera2:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)Neste ponto, tanto a galera1 quanto a galera3 estarão relatando um status global semelhante:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Eles listam o membro problemático no wsrep_evs_delayed status. Como o estado local é "Sincronizado", esses nós estão operacionais e você pode redirecionar as conexões do cliente da galera2 para qualquer um deles. Se esta etapa for inconveniente, considere usar um balanceador de carga posicionado na frente do banco de dados para simplificar o endpoint de conexão dos clientes.
Recuperação e junção de nós
Um nó Galera particionado continuará tentando estabelecer conexão com o Componente Primário infinitamente. Vamos liberar as regras do iptables no galera2 para deixá-lo se conectar com os nós restantes:
# on galera2
$ iptables -FAssim que o nó for capaz de se conectar a um dos nós, o Galera começará a restabelecer a comunicação do grupo automaticamente:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableO nó galera2 se conectará a um dos Componentes Primários (neste caso é galera1, ID do nó 737422d6) para obter a visualização do cluster atual e o estado dos nós:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera então realizará a troca de estados com o restante dos membros que podem formar o Componente Primário:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)A troca de estado permite que a galera2 calcule o quorum e produza o seguinte resultado:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera irá então promover o estado do nó local de OPEN para PRIMARY, para iniciar e estabelecer a conexão do nó com o Componente Primário:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Conforme relatado pela linha acima, o Galera calcula a distância de quanto o nó está atrás do cluster. Este nó requer transferência de estado para alcançar o número do conjunto de gravações 2836958 de 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera prepara o ouvinte IST na porta 4568 neste nó e pede a qualquer nó sincronizado no cluster para se tornar um doador. Nesse caso, Galera automaticamente escolhe galera3 (192.168.55.173), ou também pode escolher um doador da lista em wsrep_sst_donor (se definido) para a operação de sincronização:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Ele então mudará o estado do nó local de PRIMARY para JOINER. Nesta fase, a galera2 recebe a solicitação de transferência de estado e começa a armazenar em cache os conjuntos de gravação:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetO nó galera2 começa a receber os writesets ausentes do gcache do doador selecionado (galera3):
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Assim que todos os writesets ausentes forem recebidos e aplicados, o Galera promoverá a galera2 como JOINED até o seqno 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.O nó aplica quaisquer conjuntos de gravação em cache em sua fila de escravos e termina de alcançar o cluster. Sua fila de escravos agora está vazia. A Galera promoverá a galera2 para SYNCED, indicando que o nó já está operacional e pronto para atender os clientes:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsNeste ponto, todos os nós estão novamente operacionais. Você pode verificar usando as seguintes declarações na galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+O wsrep_cluster_size relatado como 3 e o status do cluster é Primário, indicando que a galera2 faz parte do Componente Primário. O wsrep_evs_delayed também foi limpo e o estado local agora está sincronizado.
O fluxo do processo de recuperação para o nó particionado durante o problema de rede pode ser resumido conforme abaixo:
- Restabelece a comunicação do grupo com outros nós.
- Recupera a visualização de cluster de um dos componentes principais.
- Realiza troca de estado com o Componente Primário e calcula o quorum.
- Altera o estado do nó local de OPEN para PRIMARY.
- Calcula a diferença entre o nó local e o cluster.
- Altera o estado do nó local de PRIMARY para JOINER.
- Prepara o ouvinte/receptor IST na porta 4568.
- Solicita transferência de estado via IST e escolhe um doador.
- Começa a receber e aplicar o conjunto de gravação ausente do gcache do doador escolhido.
- Altera o estado do nó local de JOINER para JOINED.
- Acompanha o cluster aplicando os conjuntos de gravação em cache na fila escrava.
- Altera o estado do nó local de JOINED para SYNCED.
Falha de cluster
Um Galera Cluster é considerado com falha se nenhum componente primário (PC) estiver disponível. Considere um Galera Cluster de três nós semelhante, conforme ilustrado no diagrama abaixo:
Um cluster é considerado operacional se todos os nós ou a maioria dos nós estiverem online. Online significa que eles podem ver uns aos outros através do tráfego de replicação do Galera ou comunicação de grupo. Se nenhum tráfego estiver entrando e saindo do nó, o cluster enviará um sinal de pulsação para que o nó responda em tempo hábil. Caso contrário, ele será colocado na lista de atrasos ou suspeitos de acordo com a resposta do nó.
Se um nó ficar inativo, digamos o nó C, o cluster permanecerá operacional porque os nós A e B ainda estão em quorum com 2 votos de 3 para formar um componente primário. Você deve obter o seguinte estado de cluster em A e B:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Se, digamos, um switch primário foi kaput, conforme ilustrado no diagrama a seguir:
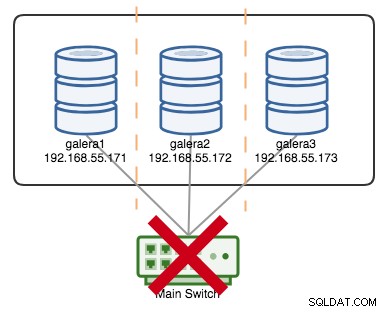
Nesse ponto, cada nó perde a comunicação entre si, e o estado do cluster será relatado como não primário em todos os nós (como o que aconteceu com a galera2 no caso anterior). Cada nó calcularia o quorum e descobriria que é a minoria (1 voto em 3) perdendo assim o quorum, o que significa que nenhum Componente Primário é formado e, consequentemente, todos os nós se recusam a fornecer quaisquer dados. Isso é considerado como falha de cluster.
Uma vez resolvido o problema da rede, o Galera restabelecerá automaticamente a comunicação entre os membros, trocará os estados dos nós e determinará a possibilidade de reformar o componente primário comparando o estado dos nós, UUIDs e seqnos. Se a probabilidade existir, o Galera mesclará os componentes primários conforme mostrado nas linhas a seguir:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
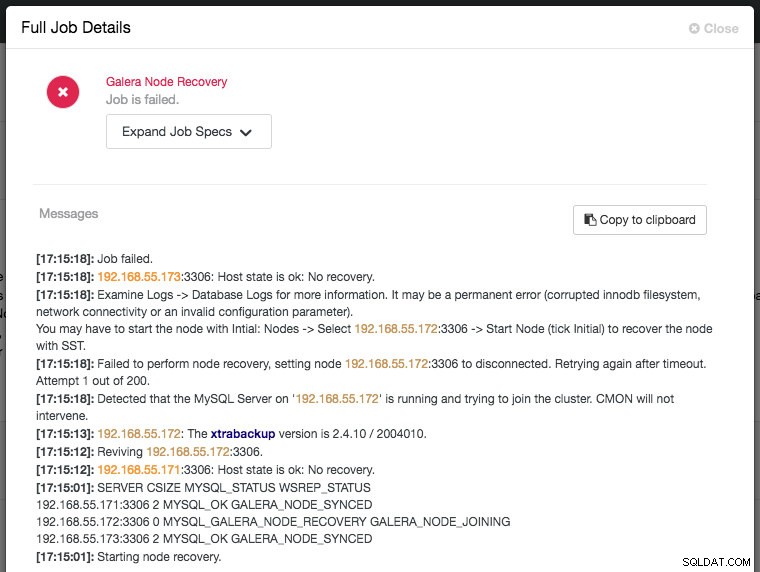
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Conclusão
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.