Mysqldump é a ferramenta de backup lógico mais popular para MySQL. Ele está incluído na distribuição do MySQL, portanto, está pronto para uso em todas as instâncias do MySQL.
Os backups lógicos não são, no entanto, a maneira mais rápida nem a mais eficiente em termos de espaço para fazer backup de bancos de dados MySQL, mas têm uma enorme vantagem sobre os backups físicos.
Os backups físicos geralmente são do tipo tudo ou nada. Embora seja possível criar backup parcial com o Xtrabackup (descrevemos isso em uma de nossas postagens de blog anteriores), restaurar esse backup é complicado e demorado.
Basicamente, se quisermos restaurar uma única tabela, temos que interromper toda a cadeia de replicação e realizar a recuperação em todos os nós de uma vez. Este é um problema importante - hoje em dia você raramente pode parar todos os bancos de dados.
Outro problema é que o nível da tabela é o nível de granularidade mais baixo que você pode alcançar com o Xtrabackup:você pode restaurar uma única tabela, mas não pode restaurar parte dela. O backup lógico, no entanto, pode ser restaurado na forma de executar instruções SQL, portanto, pode ser facilmente executado em um cluster em execução e você pode (não o chamaríamos facilmente, mas ainda assim) escolher quais instruções SQL executar para que você possa fazer uma restauração parcial de uma tabela.
Vamos dar uma olhada em como isso pode ser feito no mundo real.
Restaurando uma única tabela MySQL usando mysqldump
No início, lembre-se de que os backups parciais não fornecem uma visão consistente dos dados. Ao fazer backups de tabelas separadas, você não pode restaurar esse backup para uma posição conhecida no tempo (por exemplo, para provisionar o escravo de replicação), mesmo se você restaurar todos os dados do backup. Tendo isso atrás de nós, vamos prosseguir.
Temos um mestre e um escravo:
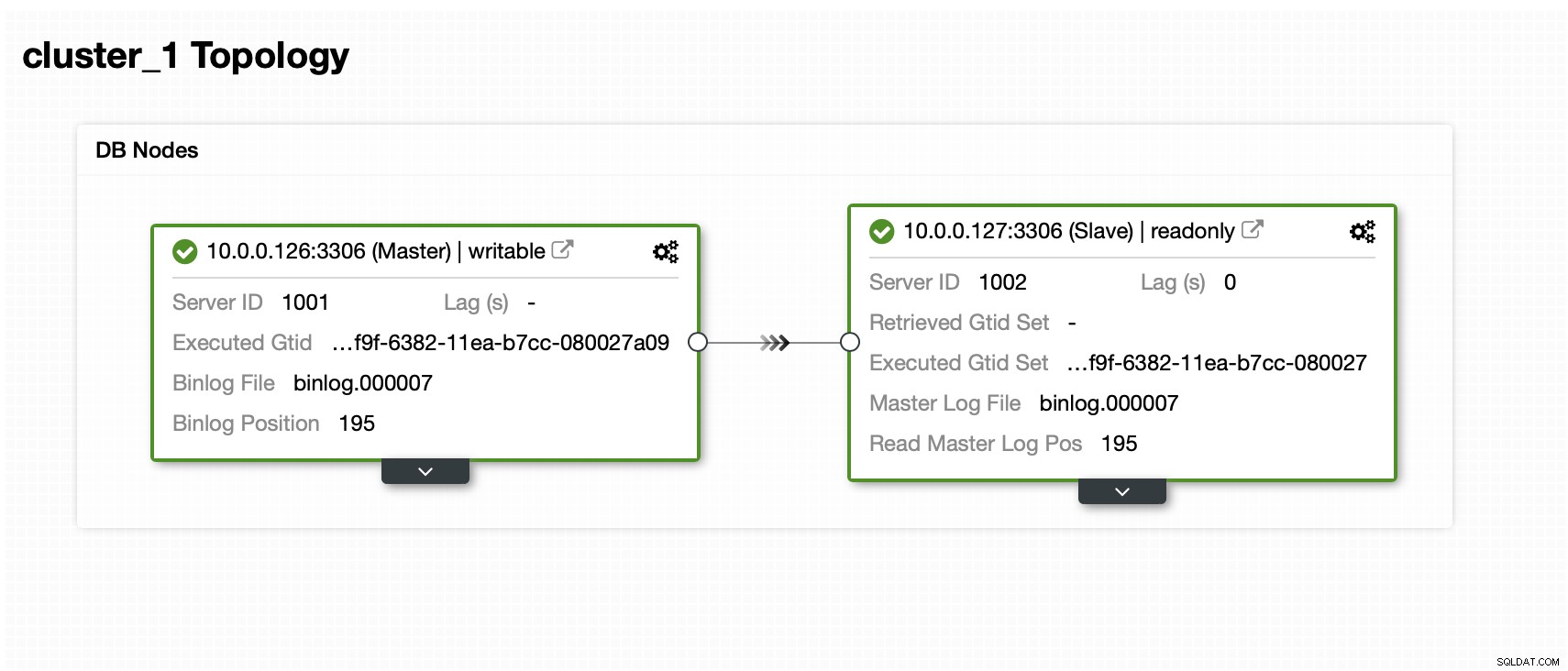
O conjunto de dados contém um esquema e várias tabelas:
mysql> SHOW SCHEMAS;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sbtest |
| sys |
+--------------------+
5 rows in set (0.01 sec)
mysql> SHOW TABLES FROM sbtest;
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest11 |
| sbtest12 |
| sbtest13 |
| sbtest14 |
| sbtest15 |
| sbtest16 |
| sbtest17 |
| sbtest18 |
| sbtest19 |
| sbtest2 |
| sbtest20 |
| sbtest21 |
| sbtest22 |
| sbtest23 |
| sbtest24 |
| sbtest25 |
| sbtest26 |
| sbtest27 |
| sbtest28 |
| sbtest29 |
| sbtest3 |
| sbtest30 |
| sbtest31 |
| sbtest32 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
+------------------+
32 rows in set (0.00 sec)Agora, temos que fazer um backup. Existem várias maneiras pelas quais podemos abordar essa questão. Podemos apenas fazer um backup consistente de todo o conjunto de dados, mas isso gerará um único arquivo grande com todos os dados. Para restaurar a tabela única, teríamos que extrair dados para a tabela desse arquivo. É claro que é possível, mas é bastante demorado e é praticamente uma operação manual que pode ser roteirizada, mas se você não tiver scripts adequados, escrever código ad hoc quando seu banco de dados estiver inativo e você estiver sob forte pressão é não necessariamente a ideia mais segura.
Em vez disso, podemos preparar o backup de forma que cada tabela seja armazenada em um arquivo separado:
example@sqldat.com:~/backup# d=$(date +%Y%m%d) ; db='sbtest'; for tab in $(mysql -uroot -ppass -h127.0.0.1 -e "SHOW TABLES FROM ${db}" | grep -v Tables_in_${db}) ; do mysqldump --set-gtid-purged=OFF --routines --events --triggers ${db} ${tab} > ${d}_${db}.${tab}.sql ; doneObserve que definimos --set-gtid-purged=OFF. Precisamos dele se formos carregar esses dados posteriormente no banco de dados. Caso contrário, o MySQL tentará definir @@GLOBAL.GTID_PURGED, o que provavelmente falhará. O MySQL também definiria SET @@SESSION.SQL_LOG_BIN=0; que definitivamente não é o que queremos. Essas configurações são necessárias se fizermos um backup consistente de todo o conjunto de dados e quisermos usá-lo para provisionar um novo nó. No nosso caso, sabemos que não é um backup consistente e não há como reconstruir nada a partir dele. Tudo o que queremos é gerar um dump que possamos carregar no mestre e deixá-lo replicar para os escravos.
Esse comando gerou uma boa lista de arquivos sql que podem ser enviados para o cluster de produção:
example@sqldat.com:~/backup# ls -alh
total 605M
drwxr-xr-x 2 root root 4.0K Mar 18 14:10 .
drwx------ 9 root root 4.0K Mar 18 14:08 ..
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest10.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest11.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest12.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest13.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest14.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest15.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest16.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest17.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest18.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest19.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest1.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest20.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest21.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest22.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest23.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest24.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest25.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest26.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest27.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest28.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest29.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest2.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest30.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest31.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest32.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest3.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest4.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest5.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest6.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest7.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest8.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest9.sqlQuando quiser restaurar os dados, tudo o que você precisa fazer é carregar o arquivo SQL no nó mestre:
example@sqldat.com:~/backup# mysql -uroot -ppass sbtest < 20200318_sbtest.sbtest11.sqlOs dados serão carregados no banco de dados e replicados para todos os escravos.
Como restaurar uma única tabela MySQL usando o ClusterControl?
Atualmente, o ClusterControl não fornece uma maneira fácil de restaurar apenas uma única tabela, mas ainda é possível fazê-lo com apenas algumas ações manuais. Existem duas opções que você pode usar. Primeiro, adequado para um pequeno número de tabelas, você pode basicamente criar um agendamento onde você realiza backups parciais de tabelas separadas uma a uma:
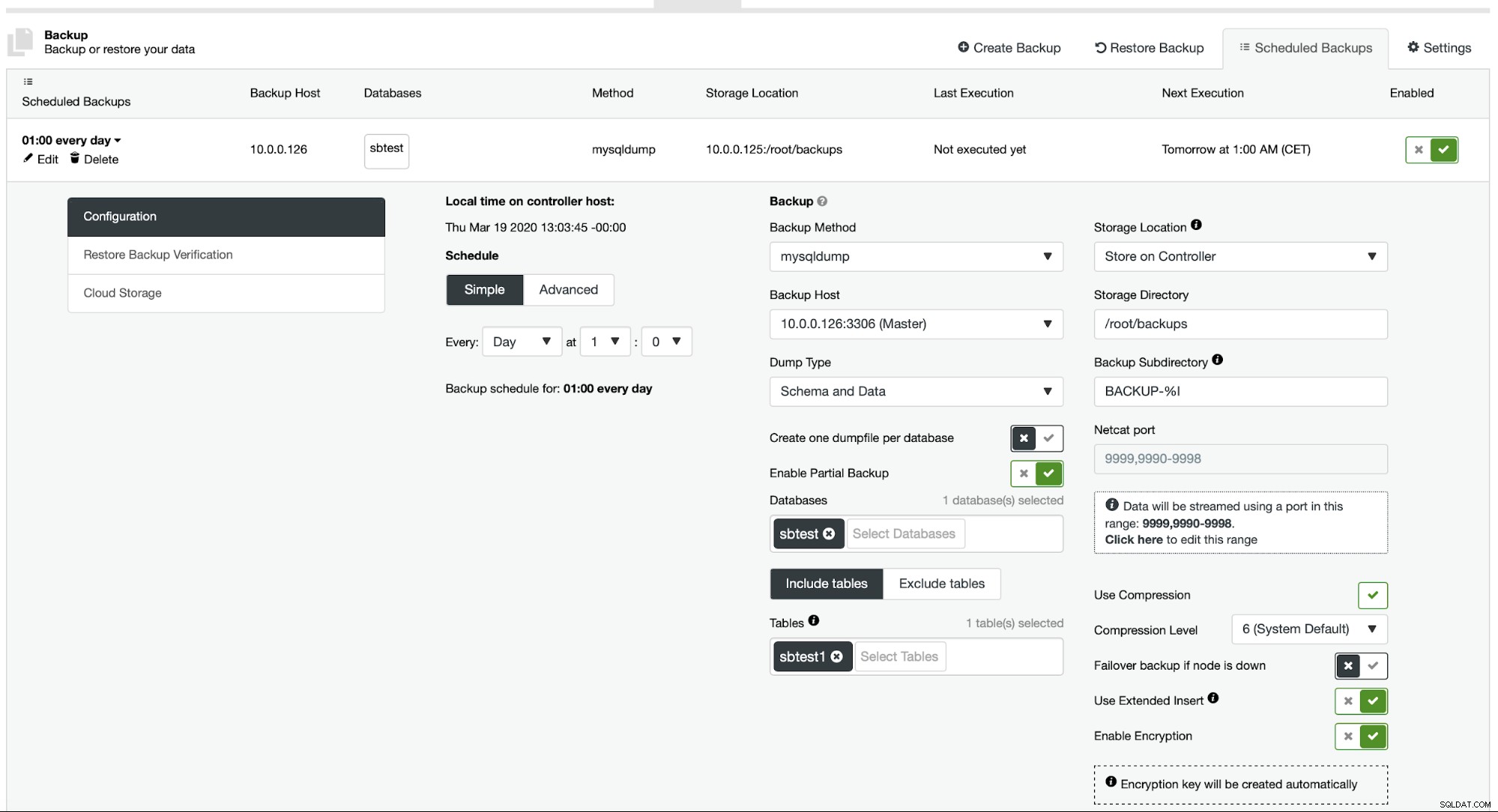
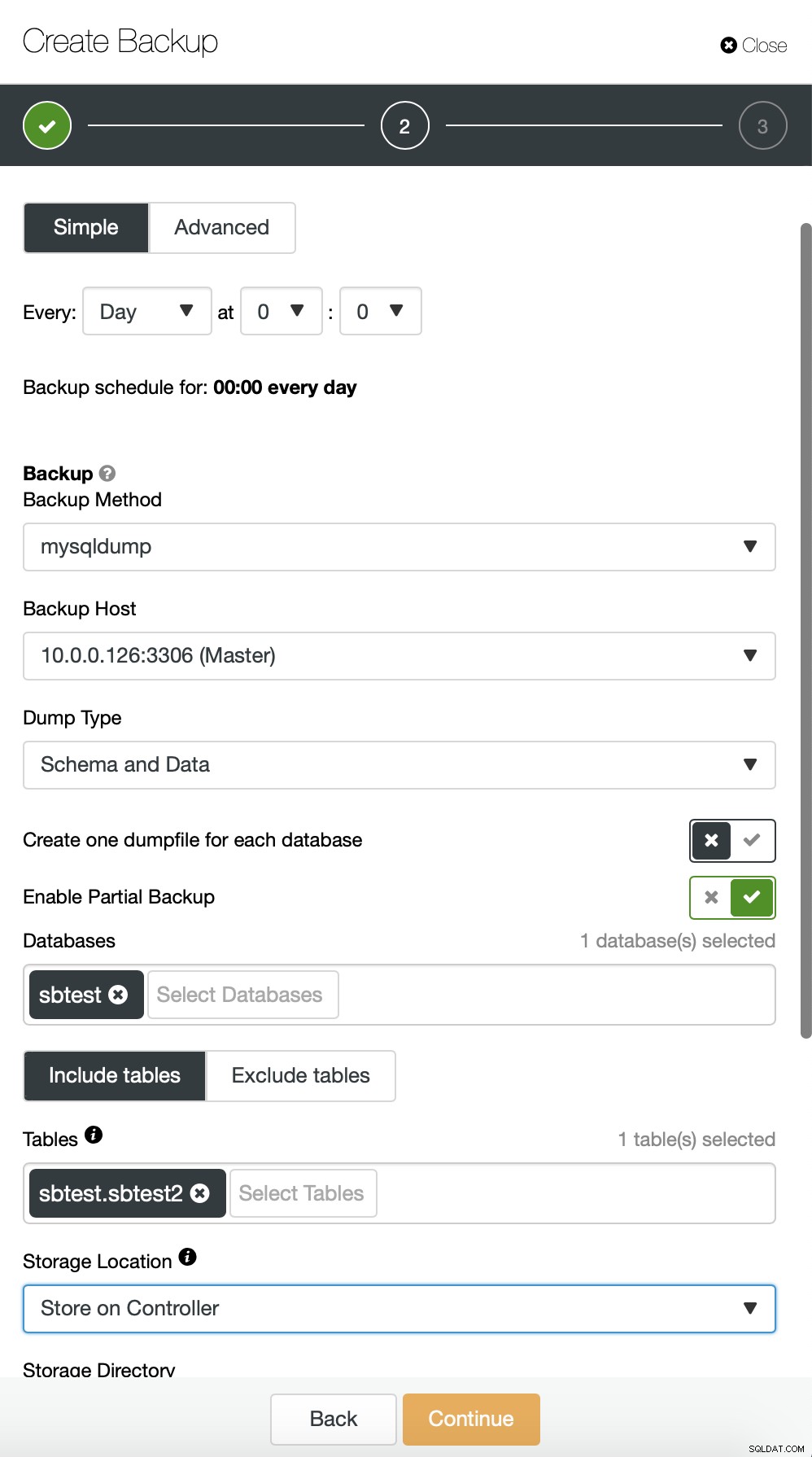
Aqui, estamos fazendo um backup da tabela sbtest.sbtest1. Podemos agendar facilmente outro backup para a tabela sbtest2:
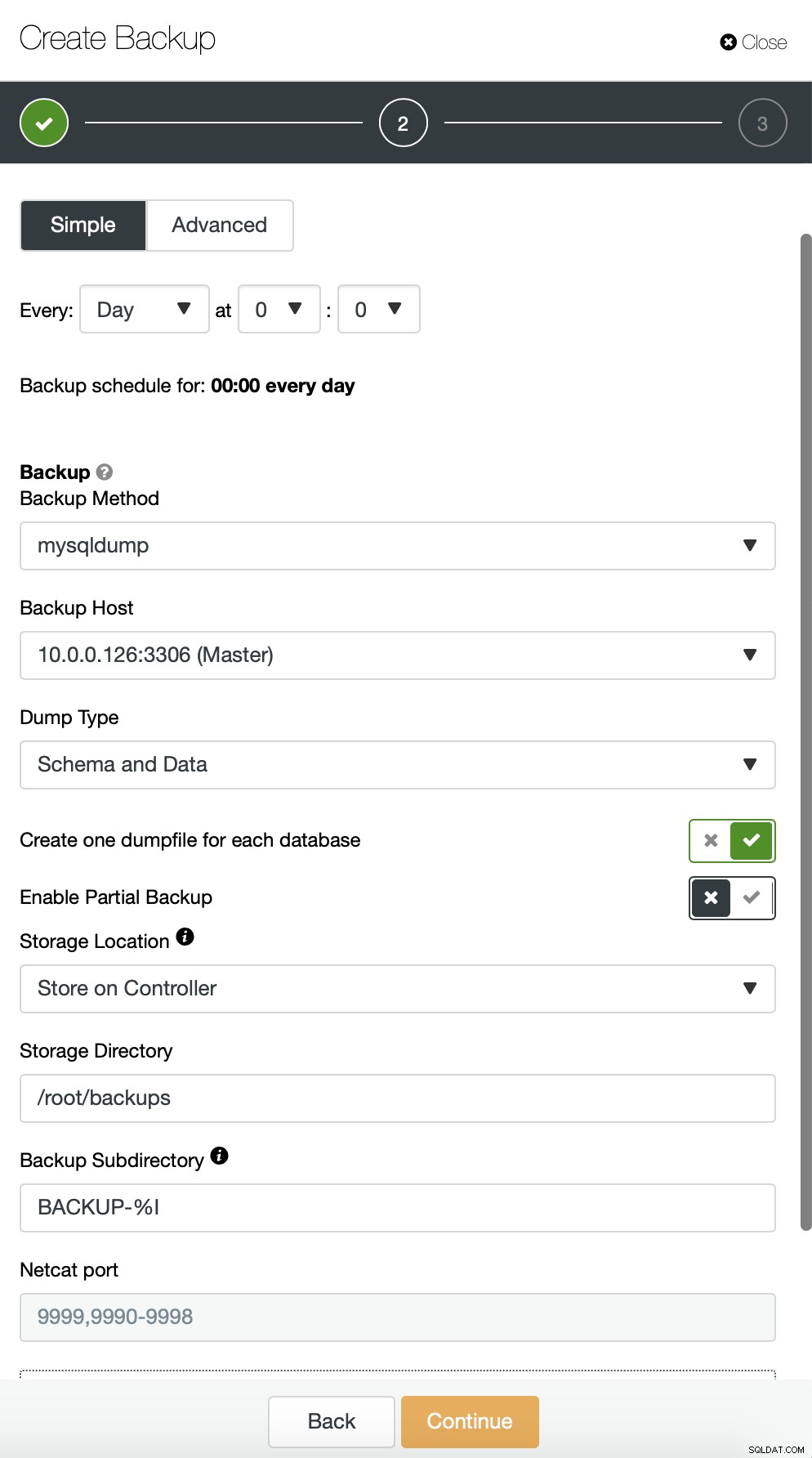
Alternativamente, podemos realizar um backup e colocar dados de um único esquema em um arquivo separado:
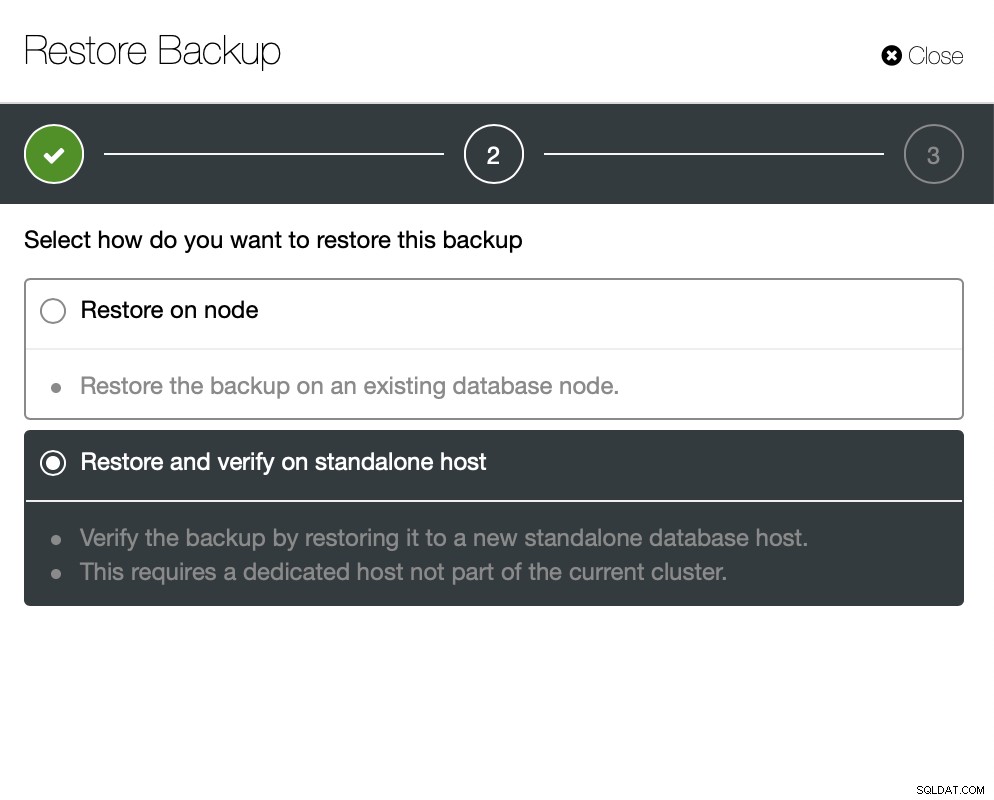
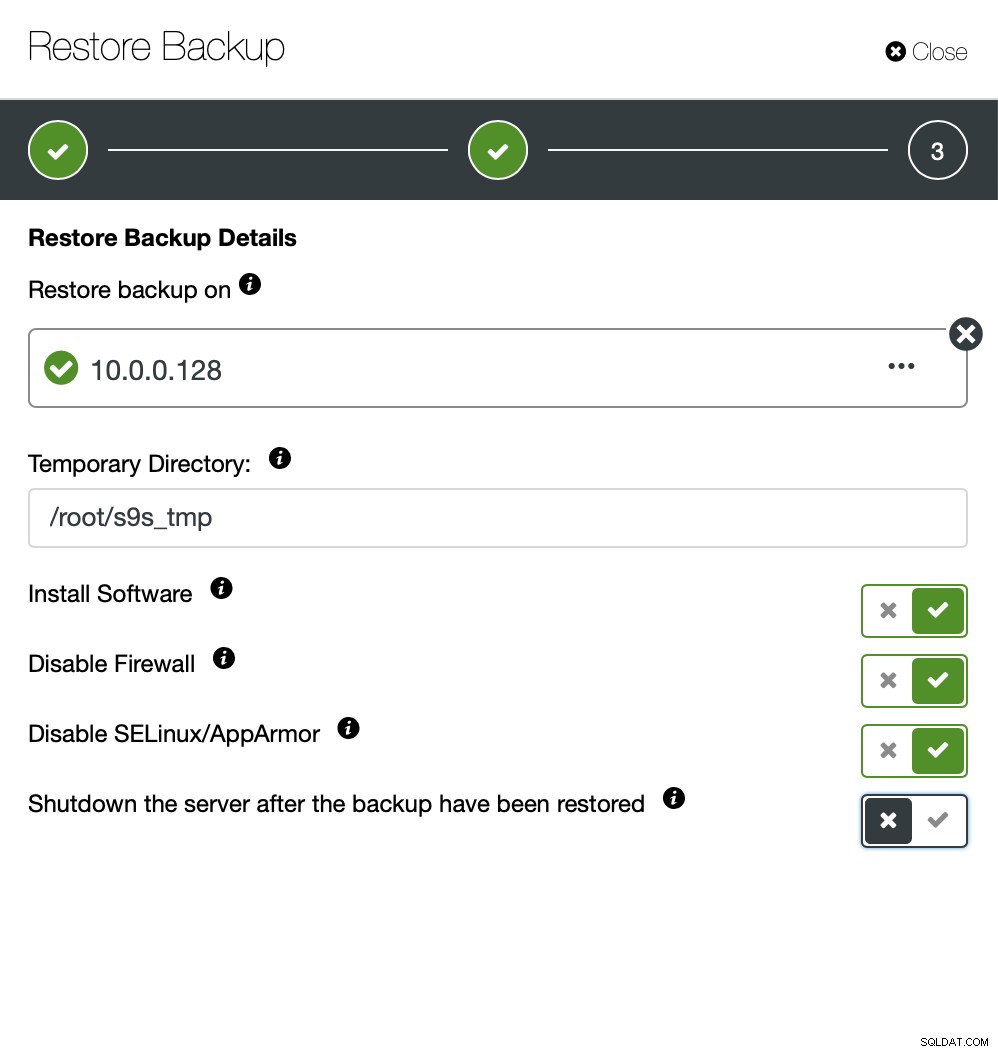
Agora você pode encontrar os dados ausentes manualmente no arquivo, restaurar este backup para um servidor separado ou deixe o ClusterControl fazer isso:
Você mantém o servidor funcionando e pode extrair os dados que você queria restaurar usando mysqldump ou SELECT … INTO OUTFILE. Esses dados extraídos estarão prontos para serem aplicados no cluster de produção.