Este artigo usa uma consulta simples para explorar alguns detalhes internos sobre consultas de atualização.
Dados de amostra e configuração
O script de criação de dados de exemplo abaixo requer uma tabela de números. Se você ainda não possui um desses, o script abaixo pode ser usado para criar um de forma eficiente. A tabela de números resultante conterá uma única coluna inteira com números de um a um milhão:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); O script abaixo cria uma tabela de dados de amostra agrupada com 10.000 IDs, com cerca de 100 datas de início diferentes por ID. A coluna de data de término é inicialmente definida com o valor fixo '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Embora os pontos apresentados neste artigo se apliquem geralmente a todas as versões atuais do SQL Server, as informações de configuração abaixo podem ser usadas para garantir que você veja planos de execução e efeitos de desempenho semelhantes:
- SQL Server 2012 Service Pack 3 Edição de desenvolvedor x64
- Memória máxima do servidor definida para 2.048 MB
- Quatro processadores lógicos disponíveis para a instância
- Nenhum sinalizador de rastreamento ativado
- Nível de isolamento confirmado de leitura padrão
- Opções de banco de dados RCSI e SI desativadas
Derramamento de agregados de hash
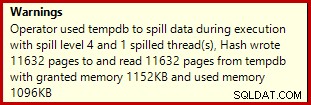
Se você executar o script de criação de dados acima com os planos de execução reais ativados, a agregação de hash pode ser derramada no tempdb, gerando um ícone de aviso:

Quando executado no SQL Server 2012 Service Pack 3, informações adicionais sobre o spill são mostradas na dica de ferramenta:
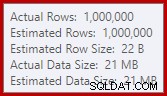
Esse derramamento pode ser surpreendente, já que as estimativas de linha de entrada para o Hash Match estão exatamente corretas:
Estamos acostumados a comparar estimativas na entrada para classificações e junções de hash (somente entrada de compilação), mas as agregações de hash ansiosas são diferentes. Uma agregação de hash funciona acumulando linhas de resultados agrupadas na tabela de hash, portanto, é o número de saída linhas que é importante:
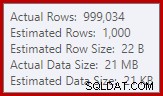
O estimador de cardinalidade no SQL Server 2012 faz uma estimativa bastante ruim do número de valores distintos esperados (1.000 versus 999.034 reais); o agregado de hash se espalha recursivamente para o nível 4 em tempo de execução como consequência. O 'novo' estimador de cardinalidade disponível no SQL Server 2014 em diante produz uma estimativa mais precisa para a saída de hash nesta consulta, portanto, você não verá um derramamento de hash nesse caso:

O número de linhas reais pode ser ligeiramente diferente para você, devido ao uso de um gerador de números pseudo-aleatórios no script. O ponto importante é que os spills do Hash Aggregate dependem do número de saída de valores exclusivos, não do tamanho da entrada.
A Especificação de Atualização
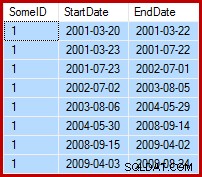
A tarefa em mãos é atualizar os dados de exemplo de forma que as datas de término sejam definidas para o dia anterior à data de início seguinte (por SomeID). Por exemplo, as primeiras linhas dos dados de amostra podem ter esta aparência antes da atualização (todas as datas de término definidas como 9999-12-31):

Então assim após a atualização:
1. Consulta de atualização da linha de base
Uma maneira razoavelmente natural de expressar a atualização necessária no T-SQL é a seguinte:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); O plano de execução pós-execução (real) é:
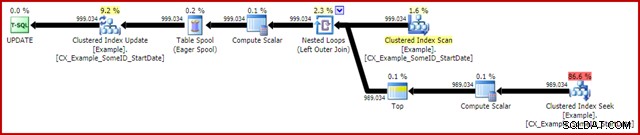
A característica mais notável é o uso de um Eager Table Spool para fornecer proteção de Halloween. Isso é necessário para a operação correta aqui devido à auto-junção da tabela de destino de atualização. O efeito é que tudo à direita do spool é executado até a conclusão, armazenando todas as informações necessárias para fazer alterações em uma tabela de trabalho tempdb. Depois que a operação de leitura for concluída, o conteúdo da tabela de trabalho será reproduzido para aplicar as alterações no iterador de atualização de índice clusterizado.
Desempenho
Para focar no potencial de desempenho máximo desse plano de execução, podemos executar a mesma consulta de atualização várias vezes. Claramente, apenas a primeira execução resultará em alterações nos dados, mas isso acaba sendo uma consideração menor. Se isso incomoda você, sinta-se à vontade para redefinir a coluna de data de término antes de cada execução usando o código a seguir. Os pontos gerais que farei não dependem do número de alterações de dados realmente feitas.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Com a coleta do plano de execução desativada, todas as páginas necessárias no buffer pool e sem redefinição dos valores de data de término entre as execuções, essa consulta normalmente é executada em torno de 5700 ms no meu laptop. A saída de E/S de estatísticas é a seguinte:(leituras antecipadas e contadores LOB eram zero e são omitidos por motivos de espaço)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
A contagem de varredura representa o número de vezes que uma operação de varredura foi iniciada. Para a tabela de exemplo, isso é 1 para a varredura de índice clusterizado e 999.034 para cada vez que a busca de índice clusterizado correlacionada é recuperada. A mesa de trabalho usada pelo Eager Spool tem uma operação de digitalização iniciada apenas uma vez.
Leituras lógicas
A informação mais interessante na saída de E/S é o número de leituras lógicas:mais de 6 milhões para a tabela de exemplo e quase 3 milhões para a mesa de trabalho.
As leituras lógicas da tabela de exemplo são principalmente associadas à busca e à atualização. O Seek incorre em 3 leituras lógicas para cada iteração:1 para cada nível raiz, intermediário e folha do índice. A atualização também custa 3 leituras cada vez que uma linha é atualizado, à medida que o mecanismo navega pela árvore b para localizar a linha de destino. O Clustered Index Scan é responsável por apenas alguns milhares de leituras, uma por página leitura.
A mesa de trabalho Spool também é estruturada internamente como uma b-tree e conta várias leituras à medida que o spool localiza a posição de inserção enquanto consome sua entrada. Talvez contra-intuitivamente, o spool não conta nenhuma leitura lógica enquanto está sendo lido para conduzir a Atualização do Índice Clusterizado. Isso é simplesmente uma consequência da implementação:uma leitura lógica é contada sempre que o código executa o BPool::Get método. A gravação no spool chama esse método em cada nível do índice; a leitura do spool segue um caminho de código diferente que não chama BPool::Get de forma alguma.
Observe também que a saída de E/S de estatísticas relata um único total para a tabela de exemplo, apesar de ser acessada por três iteradores diferentes no plano de execução (Scan, Seek e Update). Este último fato torna difícil correlacionar leituras lógicas ao iterador que as causou. Espero que essa limitação seja abordada em uma versão futura do produto.
2. Atualizar usando números de linha
Outra maneira de expressar a consulta de atualização envolve numerar as linhas por ID e unir:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); O plano pós-execução é o seguinte:
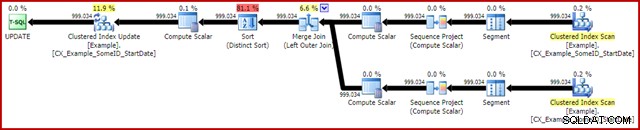
Essa consulta normalmente é executada em 2950 ms no meu laptop, que se compara favoravelmente com os 5700ms (nas mesmas circunstâncias) vistos para a declaração de atualização original. A saída de IO de estatísticas é:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Isso mostra duas varreduras iniciadas para a tabela de exemplo (uma para cada iterador de varredura de índice clusterizado). As leituras lógicas são novamente uma agregação sobre todos os iteradores que acessam essa tabela no plano de consulta. Como antes, a falta de um detalhamento torna impossível determinar qual iterador (dos dois Scans e o Update) foi responsável pelos 3 milhões de leituras.
No entanto, posso dizer que os Clustered Index Scans contam apenas alguns milhares de leituras lógicas cada. A grande maioria das leituras lógicas é causada pela atualização do índice clusterizado navegando pela árvore b do índice para encontrar a posição de atualização para cada linha processada. Você terá que aceitar minha palavra por enquanto; mais explicações serão divulgadas em breve.
As desvantagens
Isso é praticamente o fim das boas notícias para esta forma de consulta. Ele tem um desempenho muito melhor do que o original, mas é muito menos satisfatório por várias outras razões. O principal problema é causado por uma limitação do otimizador, o que significa que ele não reconhece que a operação de numeração de linha produz um número exclusivo para cada linha em uma partição SomeID.
Este simples fato leva a uma série de consequências indesejáveis. Por um lado, a junção de mesclagem está configurada para ser executada no modo de junção muitos para muitos. Esse é o motivo da tabela de trabalho (não usada) no IO de estatísticas (a mesclagem de muitos para muitos requer uma tabela de trabalho para retrocessos de chave de junção duplicados). Esperar uma junção de muitos para muitos também significa que a estimativa de cardinalidade para a saída da junção está irremediavelmente errada:
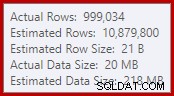
Como consequência disso, o Sort solicita muita concessão de memória. As propriedades do nó raiz mostram que a classificação teria gostado de 812.752 KB de memória, embora tenha recebido apenas 379.440 KB devido à configuração de memória máxima do servidor restrita (2.048 MB). A classificação realmente usou um máximo de 58.968 KB em tempo de execução:
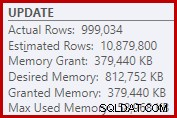
As concessões de memória excessivas roubam a memória de outros usos produtivos e podem levar a consultas esperando até que a memória fique disponível. Em muitos aspectos, concessões excessivas de memória podem ser mais um problema do que subestimar.
A limitação do otimizador também explica por que uma dica de junção de mesclagem foi necessária na consulta para obter melhor desempenho. Sem essa dica, o otimizador avalia incorretamente que uma junção de hash seria mais barata do que a junção de mesclagem muitos para muitos. O plano de junção de hash é executado em 3350ms em média.
Como consequência negativa final, observe que a classificação no plano é uma classificação distinta. Agora, existem algumas razões para esse tipo (até porque ele pode fornecer a proteção de Halloween necessária), mas é apenas um distinto Classifique porque o otimizador perde as informações de exclusividade. No geral, é difícil gostar muito desse plano de execução além do desempenho.
3. Atualizar usando a função analítica LEAD
Como este artigo se destina principalmente ao SQL Server 2012 e posterior, podemos expressar a consulta de atualização de forma bastante natural usando a função analítica LEAD. Em um mundo ideal, poderíamos usar uma sintaxe muito compacta como:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Infelizmente, isso não é legal. Isso resulta na mensagem de erro 4108, "Funções em janela só podem aparecer nas cláusulas SELECT ou ORDER BY". Isso é um pouco frustrante porque esperávamos um plano de execução que pudesse evitar uma auto-inscrição (e a atualização associada Proteção de Halloween).
A boa notícia é que ainda podemos evitar a autojunção usando uma expressão de tabela comum ou uma tabela derivada. A sintaxe é um pouco mais detalhada, mas a ideia é praticamente a mesma:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); O plano pós-execução é:

Isso normalmente é executado em cerca de 3400 ms no meu laptop, que é mais lento que a solução de número de linha (2950ms), mas ainda muito mais rápido que o original (5700ms). Uma coisa que se destaca do plano de execução é o derramamento de classificação (novamente, informações adicionais sobre derramamento, cortesia das melhorias no SP3):
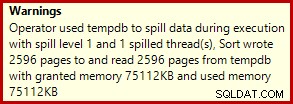
Este é um pequeno vazamento, mas ainda pode estar afetando o desempenho até certo ponto. O estranho é que a estimativa de entrada para o Sort está exatamente correta:
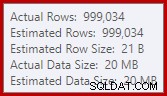
Felizmente, há uma "correção" para essa condição específica no SQL Server 2012 SP2 CU8 (e outras versões – consulte o artigo da base de conhecimento para obter detalhes). Executar a consulta com a correção e o sinalizador de rastreamento necessário 7470 ativado significa que a Classificação solicita memória suficiente para garantir que ela nunca seja derramada no disco se o tamanho de classificação de entrada estimado não for excedido.
Consulta de atualização LEAD sem derramamento de classificação
Para variar, a consulta habilitada para correção abaixo usa sintaxe de tabela derivada em vez de um CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); O novo plano pós-execução é:

A eliminação do pequeno derramamento melhora o desempenho de 3.400 ms para 3.250 ms . A saída de IO de estatísticas é:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Se você comparar isso com as leituras lógicas para a consulta numerada de linha, verá que as leituras lógicas diminuíram de 3.001.808 para 2.999.455 – uma diferença de 2.353 leituras. Isso corresponde exatamente à remoção de um único Clustered Index Scan (uma leitura por página).
Você deve se lembrar de que mencionei que a grande maioria das leituras lógicas para essas consultas de atualização estão associadas à atualização de índice clusterizado e que as verificações estavam associadas a "apenas alguns milhares de leituras". Agora podemos ver isso um pouco mais diretamente executando uma consulta simples de contagem de linhas na tabela Exemplo:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
A saída de E/S mostra exatamente a diferença de 2.353 leituras lógicas entre o número da linha e as atualizações do lead:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Melhorias adicionais?
A consulta de lead com correção de spill (3250ms) ainda é um pouco mais lenta do que a consulta numerada de linha dupla (2950ms), o que pode ser um pouco surpreendente. Intuitivamente, pode-se esperar que uma única varredura e função analítica (Window Spool e Stream Aggregate) sejam mais rápidas do que duas varreduras, dois conjuntos de numeração de linhas e uma junção.
Independentemente disso, o que salta do plano de execução da consulta principal é o Sort. Ele também estava presente na consulta numerada por linha, onde contribuiu com a Proteção do Dia das Bruxas, bem como uma ordem de classificação otimizada para a Atualização do Índice Agrupado (que tem o conjunto de propriedades DMLRequestSort).
O problema é que esse Sort é completamente desnecessário no plano de consulta do lead. Não é necessário para a Proteção do Dia das Bruxas porque a auto-inscrição desapareceu. Também não é necessário para a ordem de classificação de inserção otimizada:as linhas estão sendo lidas na ordem de chave agrupada e não há nada no plano que perturbe essa ordem. O problema real pode ser visto observando as propriedades Sort:

Observe a seção Ordenar por lá. A classificação é ordenada por SomeID e StartDate (as chaves de índice clusterizadas), mas também por [Uniq1002], que é o unificador. Isso é uma consequência de não declarar o índice clusterizado como exclusivo, embora tenhamos realizado etapas na consulta de preenchimento de dados para garantir que a combinação de SomeID e StartDate seja de fato exclusiva. (Isso foi deliberado, para que eu pudesse falar sobre isso.)
Mesmo assim, isso é uma limitação. As linhas são lidas do Índice Agrupado em ordem e as garantias internas necessárias existem para que o otimizador possa evitar com segurança essa Classificação. É simplesmente um descuido que o otimizador não reconhece que o fluxo de entrada é classificado por unificador, bem como por SomeID e StartDate. Ele reconhece que a ordem (SomeID, StartDate) pode ser preservada, mas não (SomeID, StartDate, uniquifier). Novamente, espero que isso seja abordado em uma versão futura.
Para contornar isso, podemos fazer o que deveríamos ter feito em primeiro lugar:construir o índice clusterizado como exclusivo:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
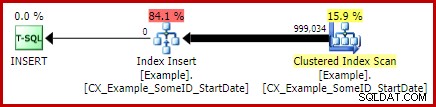
Vou deixar como exercício para o leitor mostrar que as duas primeiras consultas (não LEAD) não se beneficiam dessa mudança de indexação (omitida puramente por questões de espaço – há muito o que cobrir).
O formulário final da consulta de atualização do lead
Com o único índice clusterizado em vigor, a mesma consulta LEAD exata (CTE ou tabela derivada como você quiser) produz o plano estimado (pré-execução) que esperamos:

Isso parece bastante ideal. Uma única operação de leitura e gravação com um mínimo de operadores entre elas. Certamente, parece muito melhor do que a versão anterior com o desnecessário Sort, que foi executado em 3250ms uma vez que o vazamento evitável foi removido (ao custo de aumentar um pouco a concessão de memória).
O plano de pós-execução (real) é quase exatamente o mesmo que o plano de pré-execução:

Todas as estimativas estão exatamente corretas, exceto a saída do Window Spool, que está desalinhada por 2 linhas. As informações de IO de estatísticas são exatamente as mesmas de antes da remoção da classificação, como seria de esperar:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Para resumir brevemente, a única diferença aparente entre este novo plano e o imediatamente anterior é que o Sort (com uma contribuição de custo estimada de quase 80%) foi removido.
Pode ser uma surpresa, então, saber que a nova consulta – sem o Sort – é executada em 5000ms . Isso é muito pior do que os 3250ms com o Sort, e quase tão longo quanto a consulta de junção de loop original de 5700ms. A solução de numeração de linha dupla ainda está muito à frente em 2950ms.
Explicação
A explicação é um tanto esotérica e está relacionada à maneira como as travas são tratadas para a consulta mais recente. Podemos mostrar esse efeito de várias maneiras, mas a mais simples provavelmente é observar as estatísticas de espera e trava usando DMVs:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Quando o índice clusterizado não é exclusivo e há uma classificação no plano, não há esperas significativas, apenas algumas esperas PAGEIOLATCH_UP e os SOS_SCHEDULER_YIELDs esperados.
Quando o índice clusterizado é exclusivo e o Sort é removido, as esperas são:
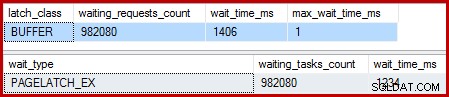
Existem 982.080 travas de página exclusivas, com um tempo de espera que explica praticamente todo o tempo extra de execução. Para enfatizar, isso é quase uma espera de trava por linha atualizada! Podemos esperar uma alteração de trava por linha, mas não uma trava esperar , especialmente quando a consulta de teste é a única atividade na instância. As esperas das travas são curtas, mas são muitas.
Travas preguiçosas
Após a execução da consulta com um depurador e analisador anexado, a explicação é a seguinte.
A Verificação de Índice Agrupado usa travas lentas – uma otimização que significa que as travas são liberadas apenas quando outro encadeamento requer acesso à página. Normalmente, as travas são liberadas imediatamente após a leitura ou escrita. As travas preguiçosas otimizam o caso em que a digitalização de uma página inteira adquiriria e liberaria a mesma trava de página para cada linha. Quando o latching lento é usado sem contenção, apenas um único latch é usado para a página inteira.
O problema é que a natureza em pipeline do plano de execução (sem operadores de bloqueio) significa que as leituras se sobrepõem às gravações. Quando a atualização de índice clusterizado tenta adquirir uma trava EX para modificar uma linha, quase sempre descobrirá que a página já está travada SH (a trava lenta obtida pela varredura de índice clusterizado). Essa situação resulta em uma espera de trava.
Como parte da preparação para aguardar e alternar para o próximo item executável no agendador, o código tem o cuidado de liberar quaisquer travas preguiçosas. Liberar a trava lenta sinaliza o primeiro garçom elegível, que por acaso é ele mesmo. Então, temos a estranha situação em que um thread se bloqueia, libera seu latch preguiçoso e sinaliza a si mesmo que está executável novamente. O encadeamento recomeça e continua, mas somente depois que todo o trabalho desperdiçado de suspender e alternar, sinalizar e retomar o trabalho foi feito. Como eu disse antes, as esperas são curtas, mas são muitas.
Pelo que sei, essa estranha sequência de eventos é intencional e por boas razões internas. Mesmo assim, não há como fugir do fato de que tem um efeito bastante dramático no desempenho aqui. Farei algumas perguntas sobre isso e atualizarei o artigo se houver uma declaração pública a ser feita. Enquanto isso, esperas excessivas de autotravamento podem ser algo a ser observado com consultas de atualização em pipeline, embora não esteja claro o que deve ser feito sobre isso do ponto de vista do escritor de consulta.
Isso significa que a abordagem de numeração de linha dupla é o melhor que podemos fazer para essa consulta? Não exatamente.
4. Proteção manual do Dia das Bruxas
Esta última opção pode soar e parecer um pouco louca. A ideia geral é escrever todas as informações necessárias para fazer as alterações em uma variável de tabela e, em seguida, realizar a atualização como uma etapa separada.
Por falta de uma descrição melhor, chamo isso de abordagem "HP manual" porque é conceitualmente semelhante a gravar todas as informações de alteração em um Eager Table Spool (como visto na primeira consulta) antes de conduzir a atualização desse Spool.
De qualquer forma, o código é o seguinte:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Esse código usa deliberadamente uma variável de tabela para evitar o custo de estatísticas criadas automaticamente que o uso de uma tabela temporária incorreria. Isso é bom aqui porque eu conheço a forma do plano que eu quero, e isso não depende de estimativas de custos ou informações estatísticas.
A única desvantagem da variável de tabela (sem um sinalizador de rastreamento) é que o otimizador normalmente estimará uma única linha e escolherá loops aninhados para a atualização. Para evitar isso, usei uma dica de junção de mesclagem. Novamente, isso é impulsionado por saber exatamente a forma do plano a ser alcançado.
O plano de pós-execução para a inserção da variável de tabela parece exatamente o mesmo que a consulta que teve o problema com as esperas de trava:

A vantagem desse plano é que ele não altera a mesma tabela da qual está lendo. Nenhuma proteção de Halloween é necessária e não há chance de interferência de trava. Além disso, há otimizações internas significativas para objetos tempdb (bloqueio e registro) e outras otimizações normais de carregamento em massa também são aplicadas. Lembre-se de que as otimizações em massa estão disponíveis apenas para inserções, não para atualizações ou exclusões.
O plano pós-execução para a instrução de atualização é:
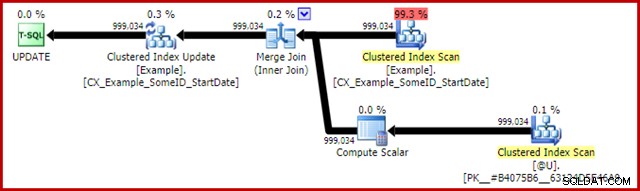
O Merge Join aqui é o tipo um-para-muitos eficiente. Mais precisamente, esse plano se qualifica para uma otimização especial que significa que a Verificação de Índice Clusterizado e a Atualização de Índice Clusterizado compartilham o mesmo conjunto de linhas. A consequência importante é que o Update não precisa mais localizar a linha a ser atualizada – ela já está posicionada corretamente pela leitura. Isso economiza uma quantidade enorme de leituras lógicas (e outras atividades) na atualização.
Não há nada nos planos de execução normal para mostrar onde essa otimização do conjunto de linhas compartilhado é aplicada, mas habilitar o sinalizador de rastreamento não documentado 8666 expõe propriedades extras na atualização e verificação que mostram que o compartilhamento do conjunto de linhas está em uso e que etapas são executadas para garantir que a atualização seja segura do problema do Dia das Bruxas.
A saída de E/S de estatísticas para as duas consultas é a seguinte:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Ambas as leituras da tabela de exemplo envolvem uma única varredura e uma leitura lógica por página (consulte a consulta de contagem de linhas simples anteriormente). A tabela #B9C034B8 é o nome do objeto tempdb interno que suporta a variável de tabela. O total de leituras lógicas para ambas as consultas é 3 * 2353 =7.059. A mesa de trabalho é o armazenamento interno na memória usado pelo Window Spool.
O tempo de execução típico para esta consulta é de 2300ms . Por fim, temos algo que supera a consulta de numeração de linha dupla (2950ms), por mais improvável que possa parecer.
Considerações finais
Pode haver maneiras ainda melhores de escrever esta atualização com desempenho ainda melhor do que a solução "HP manual" acima. Os resultados de desempenho podem até ser diferentes em sua configuração de hardware e SQL Server, mas nenhum deles é o ponto principal deste artigo. Isso não quer dizer que eu não esteja interessado em ver melhores consultas ou comparações de desempenho – estou.
A questão é que há muito mais coisas acontecendo dentro do SQL Server do que o exposto nos planos de execução. Espero que alguns dos detalhes discutidos neste artigo bastante longo sejam interessantes ou até úteis para algumas pessoas.
É bom ter expectativas de desempenho e saber quais formas e propriedades de plano geralmente são benéficas. Esse tipo de experiência e conhecimento servirá bem para 99% ou mais das consultas que você será solicitado a ajustar. Às vezes, porém, é bom tentar algo um pouco estranho ou incomum apenas para ver o que acontece e validar essas expectativas.



