Plano de fundo
Uma das primeiras coisas que observo quando estou solucionando um problema de desempenho são as estatísticas de espera por meio do DMV sys.dm_os_wait_stats. Para ver o que o SQL Server está esperando, uso a consulta do conjunto atual de consultas de diagnóstico do SQL Server de Glenn Berry. Dependendo da saída, começo a explorar áreas específicas no SQL Server.
Como exemplo, se eu ver altas esperas de CXPACKET, verifico o número de núcleos no servidor, o número de nós NUMA e os valores de grau máximo de paralelismo e limite de custo para paralelismo. Esta é a informação de fundo que eu uso para entender a configuração. Antes mesmo de considerar fazer qualquer alteração, reúno mais dados quantitativos, pois um sistema com esperas CXPACKET não necessariamente tem uma configuração incorreta para o grau máximo de paralelismo.
Da mesma forma, um sistema que tem altas esperas para tipos de espera relacionados a E/S, como PAGEIOLATCH_XX, WRITELOG e IO_COMPLETION, não tem necessariamente um subsistema de armazenamento inferior. Quando vejo os tipos de espera relacionados a E/S enquanto os principais aguardam, imediatamente quero entender mais sobre o armazenamento subjacente. É armazenamento de conexão direta ou uma SAN? Qual é o nível de RAID, quantos discos existem na matriz e qual é a velocidade dos discos? Também quero saber se outros arquivos ou bancos de dados compartilham o armazenamento. E embora seja importante entender a configuração, uma próxima etapa lógica é examinar as estatísticas do arquivo virtual por meio do DMV sys.dm_io_virtual_file_stats.
Introduzido no SQL Server 2005, este DMV é um substituto para a função fn_virtualfilestats que aqueles que executaram no SQL Server 2000 e anteriores provavelmente conhecem e adoram. O DMV contém informações de E/S cumulativas para cada arquivo de banco de dados, mas os dados são redefinidos na reinicialização da instância, quando um banco de dados é fechado, colocado offline, desconectado e reanexado etc. performance – é um snapshot que é uma agregação de dados de E/S desde a última limpeza por um dos eventos mencionados. Mesmo que os dados não sejam pontuais, eles ainda podem ser úteis. Se as esperas mais altas para uma instância estiverem relacionadas a E/S, mas o tempo médio de espera for inferior a 10 ms, o armazenamento provavelmente não é um problema, mas correlacionar a saída com o que você vê em sys.dm_io_virtual_stats ainda vale a pena confirmar a baixa latências. Além disso, mesmo que você veja altas latências em sys.dm_io_virtual_stats, ainda não provou que o armazenamento é um problema.
A configuração
Para examinar as estatísticas do arquivo virtual, configurei duas cópias do banco de dados AdventureWorks2012, que você pode baixar do Codeplex. Para a primeira cópia, daqui em diante conhecida como EX_AdventureWorks2012, executei o script de Jonathan Kehayias para expandir as tabelas Sales.SalesOrderHeader e Sales.SalesOrderDetail para 1,2 milhão e 4,9 milhões de linhas, respectivamente. Para o segundo banco de dados, BIG_AdventureWorks2012, usei o script do meu post de particionamento anterior para criar uma cópia da tabela Sales.SalesOrderHeader com 123 milhões de linhas. Ambos os bancos de dados foram armazenados em uma unidade USB externa (Seagate Slim 500GB), com tempdb no meu disco local (SSD).
Antes de testar, criei quatro procedimentos armazenados personalizados em cada banco de dados (Create_Custom_SPs.zip), que serviriam como minha carga de trabalho "normal". Meu processo de teste foi o seguinte para cada banco de dados:
- Reinicie a instância.
- Capturar estatísticas de arquivos virtuais.
- Execute a carga de trabalho "normal" por dois minutos (procedimentos chamados repetidamente por meio de um script do PowerShell).
- Capturar estatísticas de arquivos virtuais.
- Reconstrua todos os índices para as tabelas SalesOrder apropriadas.
- Capturar estatísticas de arquivos virtuais.
Os dados
Para capturar estatísticas de arquivos virtuais, criei uma tabela para armazenar informações históricas e usei uma variação da consulta de Jimmy May de seu script DMV All-Stars para o instantâneo:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Reiniciei a instância e imediatamente capturei as estatísticas do arquivo. Quando filtrei a saída para visualizar apenas os arquivos de banco de dados EX_AdventureWorks2012 e tempdb, apenas os dados de tempdb foram capturados, pois nenhum dado foi solicitado do banco de dados EX_AdventureWorks2012:

Saída da captura inicial de sys.dm_os_virtual_file_stats
Em seguida, executei a carga de trabalho "normal" por dois minutos (o número de execuções de cada procedimento armazenado variou um pouco) e depois de concluir as estatísticas do arquivo capturado novamente:

Saída de sys.dm_os_virtual_file_stats após carga de trabalho normal
Vemos uma latência de 57ms para o arquivo de dados EX_AdventureWorks2012. Não é o ideal, mas com o tempo, com minha carga de trabalho normal, isso provavelmente se igualaria. Há latência mínima para tempdb, o que é esperado, pois a carga de trabalho que executei não gera muita atividade de tempdb. Em seguida, reconstruí todos os índices para as tabelas Sales.SalesOrderHeaderEnlarged e Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
As reconstruções levaram menos de um minuto e observe o pico na latência de leitura para o arquivo de dados EX_AdventureWorks2012 e os picos na latência de gravação para os dados EX_AdventureWorks2012 e arquivos de registro:

Saída de sys.dm_os_virtual_file_stats após a reconstrução do índice
De acordo com esse instantâneo das estatísticas do arquivo, a latência é horrível; mais de 600ms para gravações! Se eu visse esse valor para um sistema de produção, seria fácil suspeitar imediatamente de problemas com armazenamento. No entanto, também vale a pena notar que AvgBPerWrite também aumentou, e gravações de blocos maiores demoram mais para serem concluídas. O aumento AvgBPerWrite é esperado para a tarefa de reconstrução do índice.
Entenda que, ao analisar esses dados, você não está obtendo uma visão completa. Uma maneira melhor de analisar as latências usando estatísticas de arquivos virtuais é tirar instantâneos e calcular a latência para o período de tempo decorrido. Por exemplo, o script abaixo usa dois instantâneos (Atual e Anterior) e calcula o número de leituras e gravações nesse período de tempo, a diferença nos valores io_stall_read_ms e io_stall_write_ms e, em seguida, divide o delta de io_stall_read_ms pelo número de leituras e o delta de io_stall_write_ms por número de gravações. Com esse método, calculamos a quantidade de tempo que o SQL Server estava aguardando na E/S para leituras ou gravações e, em seguida, dividimos pelo número de leituras ou gravações para determinar a latência.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Quando executamos isso para calcular a latência durante a reconstrução do índice, obtemos o seguinte:

Latência calculada de sys.dm_io_virtual_file_stats durante a reconstrução do índice para EX_AdventureWorks2012
Agora podemos ver que a latência real durante esse período foi alta – o que seria de esperar. E se voltássemos à nossa carga de trabalho normal e a executássemos por algumas horas, os valores médios calculados a partir das estatísticas do arquivo virtual diminuiriam com o tempo. De fato, se observarmos os dados PerfMon que foram capturados durante o teste (e depois processados por meio de PAL), veremos picos significativos no Avg. Disco seg/Leitura e Avg. Disk sec/Write que se correlaciona com o tempo em que a reconstrução do índice estava em execução. Mas em outros momentos, os valores de latência estão bem abaixo dos valores aceitáveis:
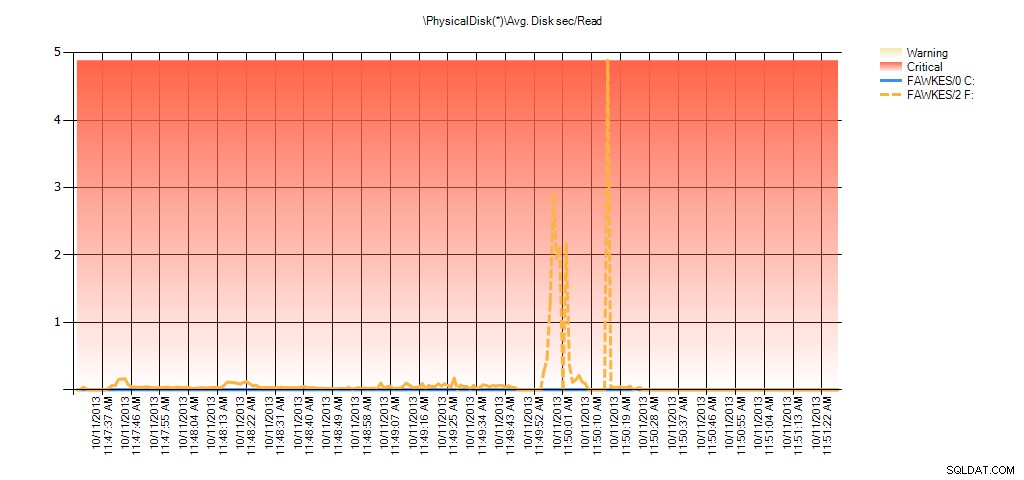
Resumo do Avg Disk Sec/Read do PAL para EX_AdventureWorks2012 durante o teste
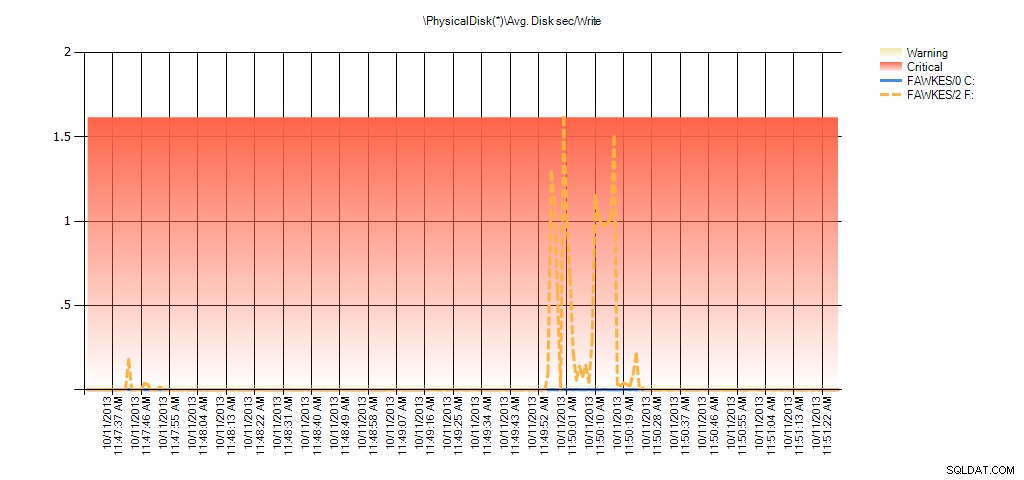
Resumo do Avg Disk Sec/Write de PAL para EX_AdventureWorks2012 durante o teste
Você pode ver o mesmo comportamento para o banco de dados BIG_AdventureWorks 2012. Aqui estão as informações de latência com base no instantâneo de estatísticas do arquivo virtual antes e depois da reconstrução do índice:

Latência calculada de sys.dm_io_virtual_file_stats durante a reconstrução do índice para BIG_AdventureWorks2012
E os dados do Monitor de Desempenho mostram os mesmos picos durante a reconstrução:
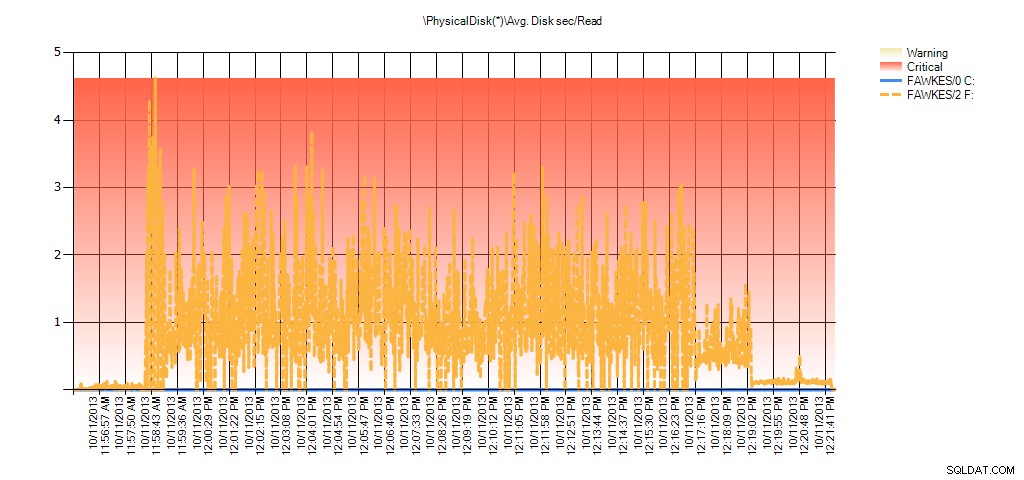
Resumo do Avg Disk Sec/Read do PAL para BIG_AdventureWorks2012 durante o teste
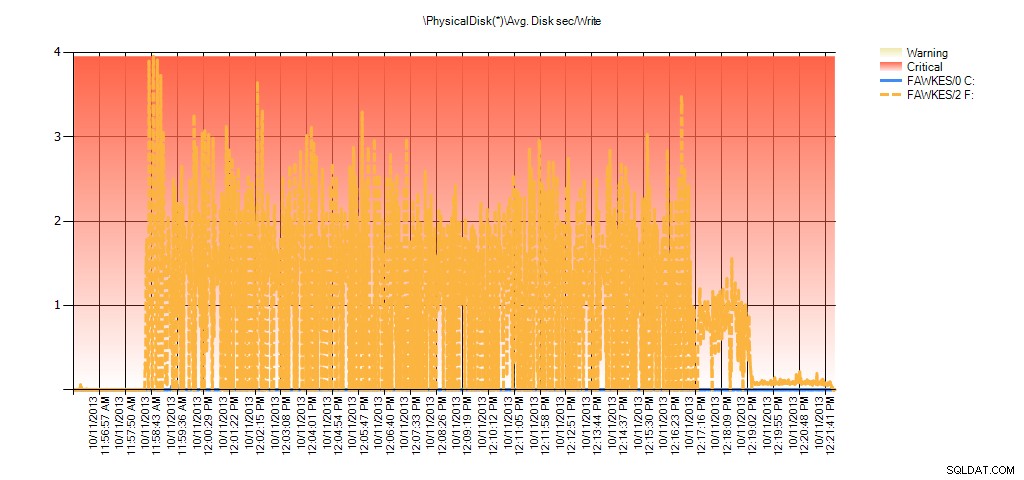
Resumo do Avg Disk Sec/Write de PAL para BIG_AdventureWorks2012 durante o teste
Conclusão
As estatísticas de arquivos virtuais são um ótimo ponto de partida quando você deseja entender o desempenho de E/S de uma instância do SQL Server. Se você vir esperas relacionadas a E/S ao examinar as estatísticas de espera, examinar sys.dm_io_virtual_file_stats é uma próxima etapa lógica. No entanto, entenda que os dados que você está visualizando são um agregado desde que as estatísticas foram limpas pela última vez por um dos eventos associados (reinicialização da instância, off-line do banco de dados, etc). Se você vir baixas latências, o subsistema de E/S está acompanhando a carga de desempenho. No entanto, se você observar latências altas, não é uma conclusão precipitada que o armazenamento é um problema. Para saber realmente o que está acontecendo, você pode começar a fazer um instantâneo das estatísticas do arquivo, como mostrado aqui, ou simplesmente usar o Monitor de desempenho para ver a latência em tempo real. É muito fácil criar um conjunto de coletores de dados no PerfMon que capture os contadores de disco físico Avg. Disco Sec/Leitura e Avg. Disk Sec/Read para todos os discos que hospedam arquivos de banco de dados. Programe o Data Collector para iniciar e parar regularmente e amostrar a cada n segundos (por exemplo, 15), e depois de capturar os dados PerfMon por um tempo apropriado, execute-o por meio de PAL para examinar a latência ao longo do tempo.
Se você achar que a latência de E/S ocorre durante sua carga de trabalho normal, e não apenas durante as tarefas de manutenção que conduzem a E/S, você ainda não pode apontar para o armazenamento como o problema subjacente. A latência de armazenamento pode existir por vários motivos, como:
- O SQL Server precisa ler muitos dados como resultado de planos de consulta ineficientes ou índices ausentes
- Muito pouca memória é alocada para a instância e os mesmos dados são lidos do disco repetidamente porque não podem permanecer na memória
- As conversões implícitas causam verificações de índice ou tabela
- As consultas executam SELECT * quando nem todas as colunas são obrigatórias
- Problemas de registro encaminhados em heaps causam E/S adicional
- Baixas densidades de página devido à fragmentação do índice, divisões de página ou configurações incorretas do fator de preenchimento causam E/S adicional
Seja qual for a causa raiz, o que é essencial entender sobre o desempenho – principalmente no que se refere à E/S – é que raramente há um ponto de dados que você possa usar para identificar o problema. Encontrar o verdadeiro problema exige vários fatos que, quando reunidos, ajudam a descobrir o problema.
Por fim, observe que, em alguns casos, a latência de armazenamento pode ser completamente aceitável. Antes de exigir armazenamento mais rápido ou alterações no código, revise os padrões de carga de trabalho e o Contrato de Nível de Serviço (SLA) do banco de dados. No caso de um Data Warehouse que atende a relatórios para usuários, o SLA para consultas provavelmente não é os mesmos valores de subsegundos que você esperaria para um sistema OLTP de alto volume. Na solução DW, as latências de E/S superiores a um segundo podem ser perfeitamente aceitáveis e esperadas. Entenda as expectativas da empresa e de seus usuários e, em seguida, determine qual ação, se houver, deve ser tomada. E se forem necessárias alterações, reúna os dados quantitativos necessários para dar suporte ao seu argumento, ou seja, estatísticas de espera, estatísticas de arquivos virtuais e latências do Monitor de desempenho.