PostgreSQL é um projeto incrível e evolui a uma velocidade incrível. Vamos nos concentrar na evolução dos recursos de tolerância a falhas no PostgreSQL em todas as suas versões com uma série de postagens no blog. Este é o segundo post da série e falaremos sobre replicação e sua importância na tolerância a falhas e confiabilidade do PostgreSQL.
Se você quiser testemunhar o progresso da evolução desde o início, confira a primeira postagem do blog da série:Evolução da tolerância a falhas no PostgreSQL
Replicação PostgreSQL
Replicação de banco de dados é o termo que usamos para descrever a tecnologia usada para manter uma cópia de um conjunto de dados em um remoto sistema. Manter uma cópia confiável de um sistema em execução é uma das maiores preocupações da redundância e todos nós gostamos de cópias estáveis, fáceis de usar e sustentáveis de nossos dados.
Vejamos a arquitetura básica. Normalmente, os servidores de banco de dados individuais são chamados de nós . Todo o grupo de servidores de banco de dados envolvidos na replicação é conhecido como cluster . Um servidor de banco de dados que permite que um usuário faça alterações é conhecido como mestre ou primário , ou pode ser descrito como uma fonte de mudanças. Um servidor de banco de dados que somente permite acesso somente leitura é conhecido como Hot Standby . (O termo Hot Standby é explicado em detalhes no título Modos de espera. )
O aspecto chave da replicação é que as alterações de dados são capturadas em um mestre e depois transferidas para outros nós. Em alguns casos, um nó pode enviar alterações de dados para outros nós, o que é um processo conhecido como em cascata ou retransmissão . Assim, o mestre é um nó emissor, mas nem todos os nós emissores precisam ser mestres. A replicação geralmente é categorizada pela permissão de mais de um nó mestre; nesse caso, ela será conhecida como replicação multimestre .
Vamos ver como o PostgreSQL está lidando com a replicação ao longo do tempo e qual é o estado da arte para tolerância a falhas pelos termos de replicação.
Histórico de replicação do PostgreSQL
Historicamente (por volta do ano 2000-2005), o Postgres se concentrava apenas na tolerância/recuperação de falhas de um único nó, que é alcançada principalmente pelo WAL, log de transações. A tolerância a falhas é tratada parcialmente pelo MVCC (sistema de simultaneidade de várias versões), mas é principalmente uma otimização.
O registro write-ahead foi e ainda é o maior método de tolerância a falhas no PostgreSQL. Basicamente, basta ter arquivos WAL onde você escreve tudo e pode se recuperar em termos de falha reproduzindo-os. Isso foi suficiente para arquiteturas de nó único e a replicação é considerada a melhor solução para alcançar a tolerância a falhas com vários nós.
A comunidade Postgres costumava acreditar há muito tempo que a replicação é algo que o Postgres não deveria fornecer e deveria ser tratado por ferramentas externas, por isso ferramentas como Slony e Londiste passaram a existir. (Vamos abordar soluções de replicação baseadas em gatilhos nas próximas postagens do blog da série.)
Eventualmente, ficou claro que, uma tolerância de servidor não é suficiente e mais pessoas exigiram tolerância a falhas adequada do hardware e maneira adequada de comutação, algo embutido no Postgres. Foi quando a replicação física (depois de streaming físico) ganhou vida.
Passaremos por todos os métodos de replicação posteriormente no post, mas vamos ver os eventos cronológicos do histórico de replicação do PostgreSQL por versões principais:
- PostgreSQL 7.x (~2000)
- A replicação não deve fazer parte do núcleo do Postgres
- Londiste – Slony (replicação lógica baseada em gatilho)
- PostgreSQL 8.0 (2005)
- Recuperação pontual (WAL)
- PostgreSQL 9.0 (2010)
- Replicação de streaming (física)
- PostgreSQL 9.4 (2014)
- Decodificação lógica (extração do conjunto de alterações)
Replicação física
O PostgreSQL resolveu a necessidade de replicação central com o que a maioria dos bancos de dados relacionais faz; pegou o WAL e possibilitou enviá-lo pela rede. Em seguida, esses arquivos WAL são aplicados em uma instância separada do Postgres que está executando somente leitura.
A instância de espera somente leitura apenas aplica as alterações (pelo WAL) e as únicas operações de gravação vir novamente do mesmo log WAL. É basicamente assim que a replicação de streaming mecanismo funciona. No início, a replicação estava originalmente enviando todos os arquivos –log shipping- , mas depois evoluiu para streaming.
No envio de logs, estávamos enviando arquivos inteiros por meio do archive_command . A lógica é bem simples:basta enviar o arquivo e registrar para algum lugar - como todo o arquivo WAL de 16 MB - e então você aplica para algum lugar e então você busca o próximo e aplicar aquele e vai assim. Mais tarde, tornou-se streaming pela rede usando o protocolo libpq no PostgreSQL versão 9.0.
A replicação existente é mais conhecida como Physical Streaming Replication, já que estamos transmitindo uma série de mudanças físicas de um nó para outro. Isso significa que quando inserimos uma linha em uma tabela, geramos registros de alteração para ainserção mais todas as entradas de índice .
Quando
VACUUM uma tabela, também geramos registros de alterações. Além disso, a replicação de streaming físico registra todas as alterações no nível de byte/bloco , tornando muito difícil fazer qualquer coisa além de apenas reproduzir tudo
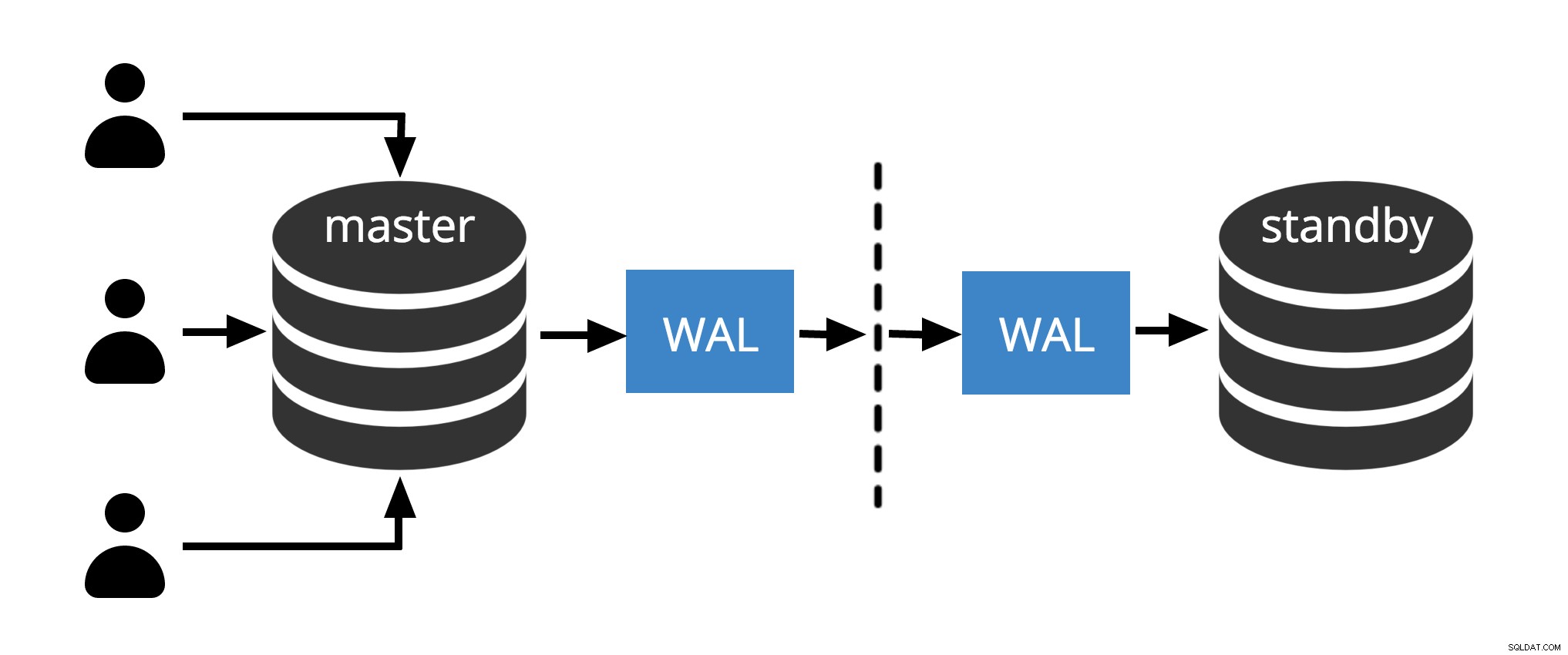
Fig.1 Replicação Física
A Fig.1 mostra como a replicação física funciona com apenas dois nós. O cliente executa consultas no nó mestre, as alterações são gravadas em um log de transações (WAL) e copiadas pela rede para WAL no nó em espera. O processo de recuperação no nó de espera lê as alterações do WAL e as aplica aos arquivos de dados como durante a recuperação de falhas. Se o modo de espera estiver em espera ativa modo, os clientes podem emitir consultas somente leitura no nó enquanto isso está acontecendo.
Observação: A Replicação Física refere-se simplesmente ao envio de arquivos WAL pela rede do mestre para o nó em espera. Os arquivos podem ser enviados por diferentes protocolos como scp, rsync, ftp… A diferença entre Replicação Física e Replicação de streaming físico is Streaming Replication usa um protocolo interno para enviar arquivos WAL (remetente e processos do receptor )
Modos de espera
Vários nós fornecem alta disponibilidade. Por esse motivo, as arquiteturas modernas geralmente têm nós de espera. Existem diferentes modos para nós de espera (espera a quente e a quente). A lista abaixo explica as diferenças básicas entre os diferentes modos de espera e também mostra o caso da arquitetura multimestre.
Modo de espera
Pode ser ativado imediatamente, mas não pode realizar trabalho útil até ser ativado. Se alimentarmos continuamente a série de arquivos WAL para outra máquina que foi carregada com o mesmo arquivo de backup básico, teremos um sistema de espera quente:a qualquer momento, podemos abrir a segunda máquina e ela terá uma cópia quase atual do o banco de dados. Warm standby não permite consultas somente leitura, a Fig.2 simplesmente representa este fato.
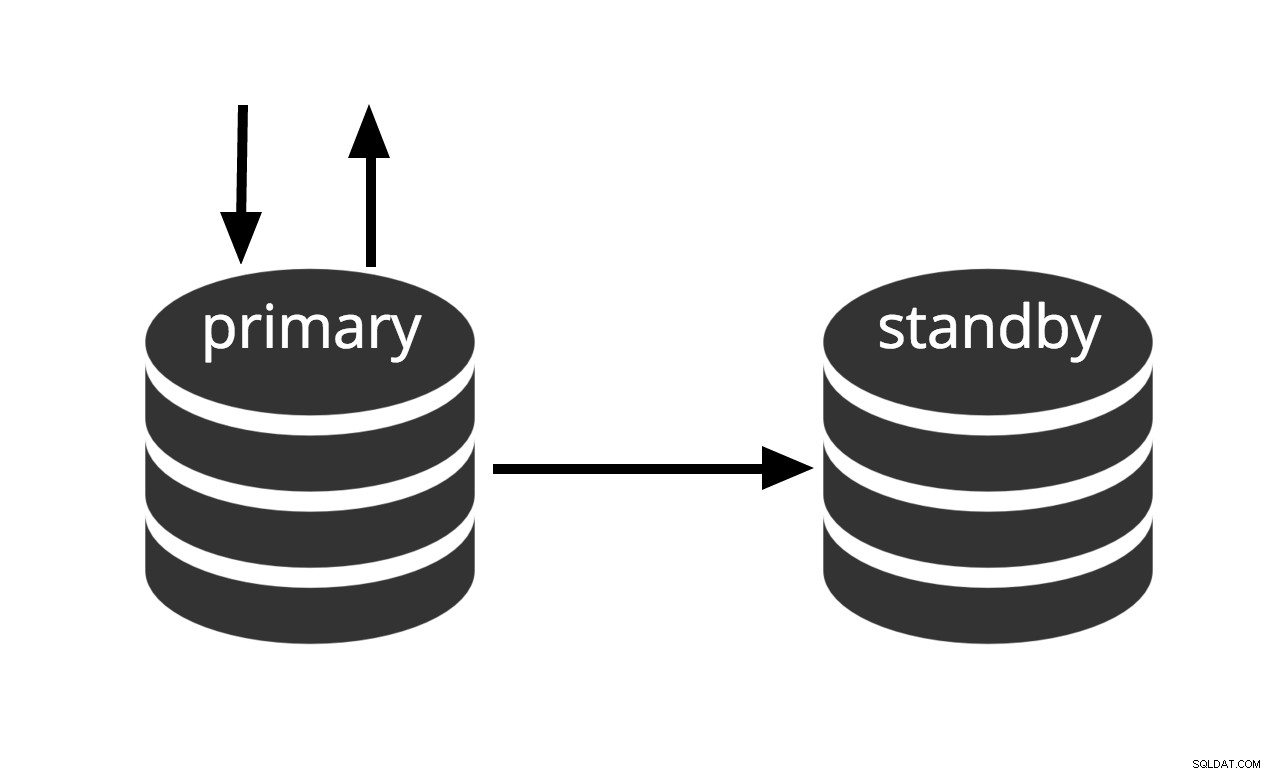
Fig.2 Warm Standby
O desempenho de recuperação de um modo de espera quente é suficientemente bom para que o modo de espera normalmente esteja a apenas alguns momentos da disponibilidade total depois de ativado. Como resultado, isso é chamado de configuração de espera quente que oferece alta disponibilidade.
Hot Standby
Hot standby é o termo usado para descrever a capacidade de se conectar ao servidor e executar consultas somente leitura enquanto o servidor está em recuperação de arquivo ou modo de espera. Isso é útil tanto para fins de replicação quanto para restaurar um backup para um estado desejado com grande precisão.
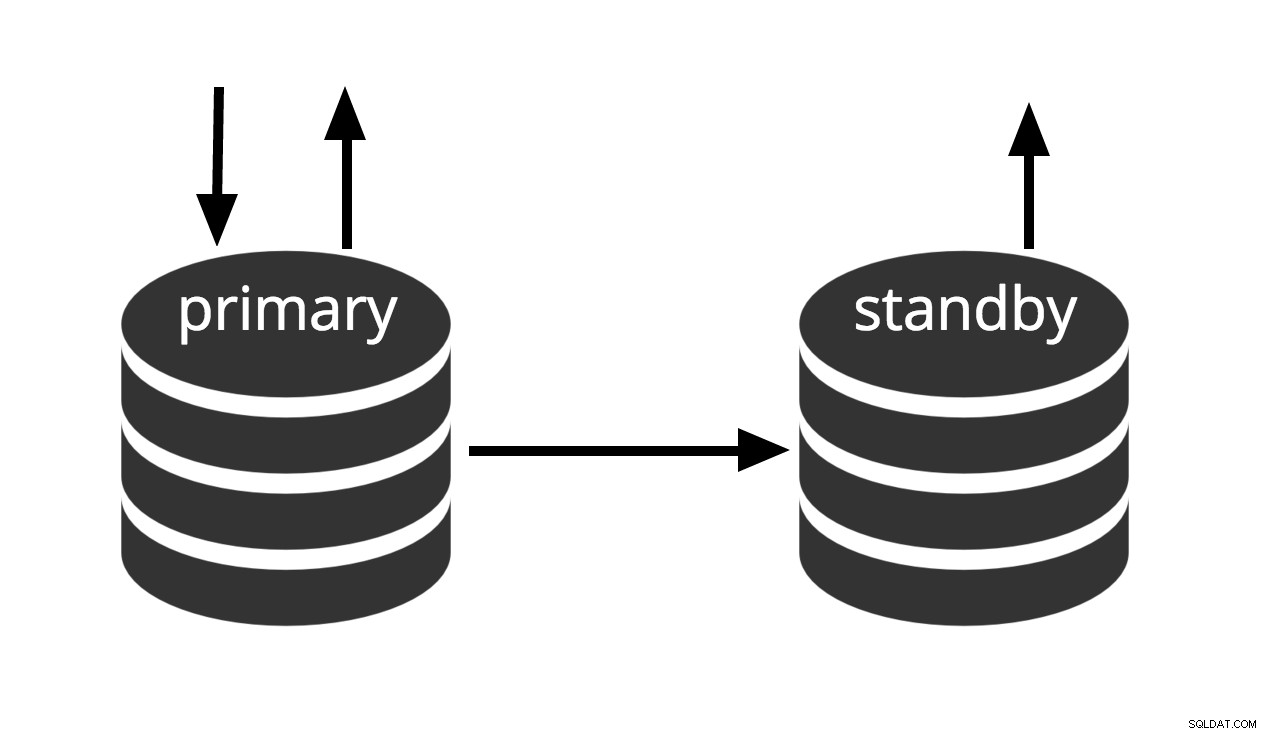 Fig.3 Hot Standby
Fig.3 Hot Standby
O termo hot standby também se refere à capacidade do servidor de passar da recuperação para a operação normal enquanto os usuários continuam executando consultas e/ou mantêm suas conexões abertas. A Fig.3 mostra que o modo de espera permite consultas somente leitura.
Multi-Mestre
Todos os nós podem executar o trabalho de leitura/gravação. (Vamos abordar arquiteturas multi-mestre nas próximas postagens do blog da série.)
Parâmetro de nível WAL
Existe uma relação entre configurar
wal_level parâmetro no arquivo postgresql.conf e para que essa configuração é adequada. Criei uma tabela para mostrar a relação para o PostgreSQL versão 9.6. 
Failover e alternância
Na replicação de mestre único, se o mestre morrer, uma das esperas deve tomar seu lugar (promoção ). Caso contrário, não poderemos aceitar novas transações de gravação. Assim, os termos designações, master e standby, são apenas papéis que qualquer nó pode assumir em algum momento. Para mover a função master para outro nó, realizamos um procedimento chamado Switchover .
Se o mestre morrer e não se recuperar, a mudança de função mais grave é conhecida como Failover . De muitas maneiras, eles podem ser semelhantes, mas ajuda a usar termos diferentes para cada evento. (Conhecer os termos de failover e alternância nos ajudará a entender os problemas da linha do tempo na próxima postagem do blog.)
Conclusão
Nesta postagem do blog, discutimos a replicação do PostgreSQL e sua importância para fornecer tolerância a falhas e confiabilidade. Cobrimos a Replicação de Streaming Físico e falamos sobre Modos de Espera para PostgreSQL. Mencionamos Failover e Switchover. Continuaremos com as linhas do tempo do PostgreSQL na próxima postagem do blog.
Referências
Documentação do PostgreSQL
Replicação lógica no PostgreSQL 5432…Apresentação do MeetUs por Petr Jelinek
Livro de receitas de administração do PostgreSQL 9 – segunda edição