Introdução
Mais cedo ou mais tarde, qualquer sistema de informação obtém um banco de dados, muitas vezes – mais de um. Com o tempo, esse banco de dados reúne muitos dados, de vários GBs a dezenas de TBs. Para entender como os funcionais irão se comportar com o aumento do volume de dados, precisamos gerar os dados para preencher esse banco de dados.

Todos os scripts apresentados e implementados serão executados no JobEmplDB base de dados de um serviço de recrutamento. A realização do banco de dados está disponível aqui.
Abordagens para o preenchimento de dados em bancos de dados para teste e desenvolvimento
O desenvolvimento e teste do banco de dados envolve duas abordagens principais para o preenchimento de dados:
- Para copiar todo o banco de dados do ambiente de produção com dados pessoais e outros dados confidenciais alterados. Dessa forma, você garante os dados e apaga os dados confidenciais.
- Para gerar dados sintéticos. Significa gerar os dados de teste semelhantes aos dados reais em aparência, propriedades e interconexões.
A vantagem da Abordagem 1 é que ela aproxima os dados e sua distribuição por diferentes critérios ao banco de dados de produção. Ele nos permite analisar tudo com precisão e, portanto, tirar conclusões e prognósticos de acordo.
No entanto, essa abordagem não permite aumentar o próprio banco de dados muitas vezes. Torna-se problemático prever mudanças na funcionalidade de todo o sistema de informação no futuro.
Por outro lado, você pode analisar dados limpos impessoais retirados do banco de dados de produção. Com base neles, você pode definir como gerar os dados de teste que seriam como os dados reais por sua aparência, propriedades e inter-relações. Desta forma, a Abordagem 1 produz a Abordagem 2.
Agora, vamos revisar em detalhes ambas as abordagens para o preenchimento de dados em bancos de dados para teste e desenvolvimento.
Cópia e alteração de dados em um banco de dados de produção
Primeiro, vamos definir o algoritmo geral de copiar e alterar os dados do ambiente de produção.
O algoritmo geral
O algoritmo geral é o seguinte:
- Crie um novo banco de dados vazio.
- Crie um esquema nesse banco de dados recém-criado – o mesmo sistema do banco de dados de produção.
- Copie os dados necessários do banco de dados de produção para o banco de dados recém-criado.
- Higienize e altere os dados secretos no novo banco de dados.
- Faça um backup do banco de dados recém-criado.
- Entregue e restaure o backup no ambiente necessário.
No entanto, o algoritmo se torna mais complicado após a etapa 5. Por exemplo, a etapa 6 requer um ambiente específico e protegido para testes preliminares. Esse estágio deve garantir que todos os dados sejam impessoais e que os dados secretos sejam alterados.
Após esse estágio, você pode retornar à etapa 5 novamente para o banco de dados testado no ambiente protegido de não produção. Em seguida, você encaminha o backup testado para os ambientes necessários para restaurá-lo e usá-lo para desenvolvimento e teste.
Apresentamos o algoritmo geral de cópia e alteração de dados do banco de dados de produção. Vamos descrever como implementá-lo.
Realização do algoritmo geral
Uma nova criação de banco de dados vazio
Você pode fazer um banco de dados vazio com a ajuda da construção CREATE DATABASE como aqui.
O banco de dados é denominado JobEmplDB_Test . Possui três grupos de arquivos:
- PRIMÁRIO – é o grupo de arquivos primário por padrão. Ele define dois arquivos:JobEmplDB_Test1(caminho D:\DBData\JobEmplDB_Test1.mdf) e JobEmplDB_Test2 (caminho D:\DBData\JobEmplDB_Test2.ndf) . O tamanho inicial de cada arquivo é de 64 Mb, e a etapa de crescimento é de 8 Mb para cada arquivo.
- DBTableGroup – um grupo de arquivos personalizado que determina dois arquivos:JobEmplDB_TestTableGroup1 (caminho D:\DBData\JobEmplDB_TestTableGroup1.ndf) e JobEmplDB_TestTableGroup2 (caminho D:\DBData\JobEmplDB_TestTableGroup2.ndf) . O tamanho inicial de cada arquivo é de 8 Gb e a etapa de crescimento é de 1 Gb para cada arquivo.
- DBIndexGroup – um grupo de arquivos personalizado que determina dois arquivos:JobEmplDB_TestIndexGroup1 (caminho D:\DBData\JobEmplDB_TestIndexGroup1.ndf) e JobEmplDB_TestIndexGroup2 (caminho D:\DBData\JobEmplDB_TestIndexGroup2.ndf) . O tamanho inicial é de 16 Gb para cada arquivo e a etapa de crescimento é de 1 Gb para cada arquivo.
Além disso, esse banco de dados inclui um diário de transações:JobEmplDB_Testlog , caminho E:\DBLog\JobEmplDB_Testlog.ldf . O tamanho inicial do arquivo é de 8 Gb e a etapa de crescimento é de 1 Gb.
Copiar o esquema e os dados necessários do banco de dados de produção para um banco de dados recém-criado
Para copiar o esquema e os dados necessários do banco de dados de produção para o novo, você pode usar várias ferramentas. Primeiro, é o Visual Studio (SSDT). Ou você pode usar utilitários de terceiros como:
- DbForge Schema Compare e DbForge Data Compare
- ApexSQL Diff e Apex Data Diff
- Ferramenta de comparação de SQL e ferramenta de comparação de dados SQL
Criando scripts para alterações de dados
Requisitos essenciais para os scripts de alterações de dados
1. Deve ser impossível restaurar os dados reais usando esse script.
por exemplo, a inversão das linhas não servirá, pois nos permite restaurar os dados reais. Normalmente, o método é substituir cada caractere ou byte por um caractere ou byte pseudo-aleatório. O mesmo se aplica à data e hora.
2. A alteração dos dados não deve alterar a seletividade de seus valores.
Não funcionará para atribuir NULL ao campo da tabela. Em vez disso, você deve garantir que os mesmos valores nos dados reais permaneçam os mesmos nos dados alterados. Por exemplo, em dados reais, você tem um valor de 103785 encontrado 12 vezes na tabela. Ao alterar esse valor nos dados alterados, o novo valor deve permanecer 12 vezes nos mesmos campos da tabela.
3. O tamanho e comprimento dos valores não devem diferir significativamente nos dados alterados. Por exemplo, você substitui cada byte ou caractere por um byte ou caractere pseudoaleatório. A string inicial permanece a mesma em tamanho e comprimento.
4. As inter-relações nos dados não devem ser quebradas após as alterações. Refere-se às chaves externas e a todos os outros casos em que você se refere aos dados alterados. Os dados alterados devem permanecer nas mesmas relações que os dados reais.
Implementação de scripts de alterações de dados
Agora, vamos revisar o caso particular dos dados mudando para despersonalizar e ocultar as informações secretas. A amostra é o banco de dados de recrutamento.
O banco de dados de exemplo inclui os seguintes dados pessoais que você precisa despersonalizar:
- Sobrenome e nome;
- Data de nascimento;
- A data de emissão da carteira de identidade;
- O certificado de acesso remoto como a sequência de bytes;
- A taxa de serviço para promoção de currículo.
Primeiro, vamos verificar exemplos simples para cada tipo de dado alterado:
- Mudança de data e hora;
- Mudança de valor numérico;
- Alterando as sequências de bytes;
- Mudança de dados de personagem.
Mudança de data e hora
Você pode obter uma data e hora aleatórias usando o seguinte script:
DECLARE @dt DATETIME;
SET @dt = CAST(CAST(@StartDate AS FLOAT) + (CAST(@FinishDate AS FLOAT) - CAST(@StartDate AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME);
Aqui, @StartDate e @FinishDate são os valores inicial e final do intervalo. Eles se correlacionam respectivamente para a geração pseudo-aleatória de data e hora.
Para gerar esses dados, você usa as funções do sistema RAND, CHECKSUM e NEWID.
UPDATE [dbo].[Employee]
SET [DocDate] = CAST(CAST(CAST(CAST([BirthDate] AS DATETIME) AS FLOAT) + (CAST(GETDATE() AS FLOAT) - CAST(CAST([BirthDate] AS DATETIME) AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME) AS DATE);
O campo [DocDate] representa a data de emissão do documento. Substituímos por uma data pseudoaleatória, tendo em conta os intervalos das datas e as suas limitações.
O limite “inferior” é a data de nascimento do candidato. A borda “superior” é a data atual. Não precisamos da hora aqui, então a transformação do formato de hora e data para a data necessária vem no final. Você pode obter valores pseudoaleatórios para qualquer parte da data e hora da mesma maneira.
Alteração do valor numérico
Você pode obter um número inteiro aleatório com a ajuda do seguinte script:
DECLARE @Int INT;
SET @Int = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
@MinVal e @MaxVal são os valores do intervalo inicial e final para a geração de números pseudoaleatórios. Nós o geramos usando as funções do sistema RAND, CHECKSUM e NEWID.
UPDATE [dbo].[Employee]
SET [CountRequest] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
O campo [CountRequest] representa o número de solicitações que as empresas fazem para o currículo desse candidato.
Da mesma forma, você pode obter valores pseudoaleatórios para qualquer valor numérico. Por exemplo, dê uma olhada no número aleatório da geração do tipo decimal (18,2):
DECLARE @Dec DECIMAL(18,2);
SET @Dec=CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Assim, pode atualizar a taxa de serviço de promoção de currículos da seguinte forma:
UPDATE [dbo].[Employee]
SET [PaymentAmount] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Alterando as sequências de bytes
Você pode obter uma sequência de bytes aleatória usando o seguinte script:
DECLARE @res VARBINARY(MAX);
SET @res = CRYPT_GEN_RANDOM(@Length, CAST(NEWID() AS VARBINARY(16)));
@Length representa o comprimento da sequência. Ele define o número de bytes retornados. Aqui, @Length não deve ser maior que 16.
A geração é feita com a ajuda das funções do sistema CRYPT_GEN_RANDOM e NEWID.
Por exemplo, você pode atualizar o certificado de acesso remoto para cada candidato da seguinte maneira:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = CRYPT_GEN_RANDOM(CAST(LEN([RemoteAccessCertificate]) AS INT), CAST(NEWID() AS VARBINARY(16)));
Geramos uma sequência de bytes pseudoaleatória de mesmo comprimento presente no campo [RemoteAccessCertificate] no momento da alteração. Supomos que o comprimento da sequência de bytes não exceda 16.
Da mesma forma, podemos criar nossa função que retornará sequências de bytes pseudoaleatórias de qualquer tamanho. Ele colocará os resultados da função do sistema CRYPT_GEN_RANDOM trabalhando juntos usando o simples operador de adição “+”. Mas 16 bytes geralmente são suficientes na prática.
Vamos fazer uma função de amostra retornando a sequência de bytes pseudoaleatória do comprimento definido, onde será possível definir o comprimento de mais de 16 bytes. Para isso, faça a seguinte apresentação:
CREATE VIEW [test].[GetNewID]
AS
SELECT NEWID() AS [NewID];
GO
Precisamos dele para evitar a limitação que nos proíbe de usar NEWID dentro da função.
Da mesma forma, crie a próxima apresentação com o mesmo propósito:
CREATE VIEW [test].[GetRand]
AS
SELECT RAND(CHECKSUM((SELECT TOP(1) [NewID] FROM [test].[GetNewID]))) AS [Value];
GO
Crie mais uma apresentação:
CREATE VIEW [test].[GetRandVarbinary16]
AS
SELECT CRYPT_GEN_RANDOM(16, CAST((SELECT TOP(1) [NewID] FROM [test].[GetNewID]) AS VARBINARY(16))) AS [Value];
GO
Todas as definições das três funções estão aqui. E aqui está a implementação da função que retorna uma sequência de bytes pseudoaleatória de comprimento definido.
Primeiro, definimos se a função necessária está presente. Se não – criamos um garanhão primeiro. De qualquer forma, o código envolve alterar a definição da função apropriadamente. No final, adicionamos a descrição da função por meio das propriedades estendidas. Mais detalhes sobre a documentação do banco de dados estão neste artigo.
Para atualizar o certificado de acesso remoto para cada candidato, você pode fazer o seguinte:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = [test].[GetRandVarbinary](CAST(LEN([RemoteAccessCertificate]) AS INT));
Como você vê, não há limitações para o comprimento da sequência de bytes aqui.
Mudança de dados – Alteração de dados de caracteres
Aqui, pegamos um exemplo para os alfabetos inglês e russo, mas você pode fazer isso para qualquer outro alfabeto. A única condição é que seus caracteres estejam presentes nos tipos NCHAR.
Precisamos criar uma função que aceite a linha, substitua cada caractere por um caractere pseudo-aleatório e, em seguida, junte o resultado e o retorne.
No entanto, precisamos primeiro entender quais caracteres precisamos. Para isso, podemos executar o seguinte script:
DECLARE @tbl TABLE ([ValueInt] INT, [ValueNChar] NCHAR(1), [ValueChar] CHAR(1));
DECLARE @ind int=0;
DECLARE @count INT=65535;
WHILE(@count>=0)
BEGIN
INSERT INTO @tbl ([ValueInt], [ValueNChar], [ValueChar])
SELECT @ind, NCHAR(@ind), CHAR(@ind)
SET @ind+=1;
SET @count-=1;
END
SELECT *
INTO [test].[TblCharactersCode]
FROM @tbl;
Estamos fazendo a tabela [test].[TblCharacterCode] que inclui os seguintes campos:
- ValueInt – o valor numérico do caractere;
- ValueNChar – o caractere do tipo NCHAR;
- ValueChar – o caractere do tipo CHAR.
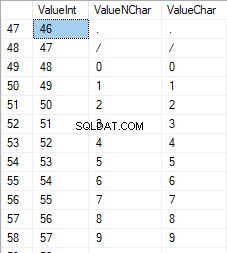
Vamos rever o conteúdo desta tabela. Precisamos do seguinte pedido:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
FROM [test].[TblCharactersCode];
Os números estão na faixa de 48 a 57:
Os caracteres latinos em maiúsculas estão no intervalo de 65 a 90:
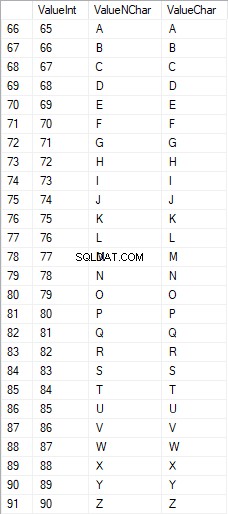
Caracteres latinos no cuidado inferior estão no intervalo de 97 a 122:
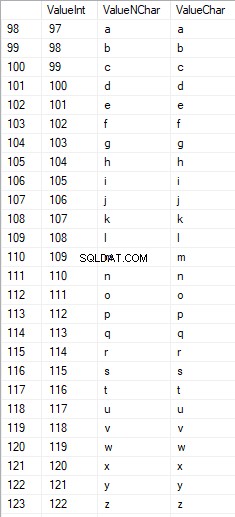
Caracteres russos em maiúsculas estão no intervalo de 1040 a 1071:

Os caracteres russos em letras minúsculas estão no intervalo de 1072 a 1103:


E, caracteres no intervalo de 58 a 64:

Selecionamos os caracteres necessários e os colocamos na tabela [test].[SelectCharactersCode] da seguinte maneira:
SELECT
[ValueInt]
,[ValueNChar]
,[ValueChar]
,CASE
WHEN ([ValueInt] BETWEEN 48 AND 57) THEN 1
ELSE 0
END AS [IsNumeral]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 1040 AND 1071)) THEN 1
ELSE 0
END AS [IsUpperCase]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 97 AND 122)) THEN 1
ELSE 0
END AS [IsLatin]
,CASE
WHEN (([ValueInt] BETWEEN 1040 AND 1071) OR
([ValueInt] BETWEEN 1072 AND 1103)) THEN 1
ELSE 0
END AS [IsRus]
,CASE
WHEN (([ValueInt] BETWEEN 33 AND 47) OR
([ValueInt] BETWEEN 58 AND 64)) THEN 1
ELSE 0
END AS [IsExtra]
INTO [test].[SelectCharactersCode]
FROM [test].[TblCharactersCode]
WHERE ([ValueInt] BETWEEN 48 AND 57)
OR ([ValueInt] BETWEEN 65 AND 90)
OR ([ValueInt] BETWEEN 97 AND 122)
OR ([ValueInt] BETWEEN 1040 AND 1071)
OR ([ValueInt] BETWEEN 1072 AND 1103)
OR ([ValueInt] BETWEEN 33 AND 47)
OR ([ValueInt] BETWEEN 58 AND 64);
Agora, vamos examinar o conteúdo desta tabela usando o seguinte script:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
,[IsNumeral]
,[IsUpperCase]
,[IsLatin]
,[IsRus]
,[IsExtra]
FROM [test].[SelectCharactersCode];
Recebemos o seguinte resultado:

Dessa forma, temos o [test].[SelectCharactersCode] mesa, onde:
- ValueInt – o valor numérico do caractere
- ValueNChar – o caractere do tipo NCHAR
- ValueChar – o caractere do tipo CHAR
- IsNumeral – o critério de um caractere ser um dígito
- IsUpperCase – o critério de um caractere em maiúscula
- IsLatim – o critério de um caractere ser um caractere latino;
- IsRus – o critério de um caractere ser um caractere russo
- ÉExtra – o critério de um caractere ser um caractere adicional
Agora, podemos obter o código para a inserção dos caracteres necessários. Por exemplo, veja como fazer isso para os caracteres latinos em letras minúsculas:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsLatin]=1;
Recebemos o seguinte resultado:

É o mesmo para os caracteres russos em letras minúsculas:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+COALESCE(''''+[ValueChar]+'''', 'NULL')+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsRus]=1;
Obtemos o seguinte resultado:

É o mesmo para os personagens:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsNumeral]=1;
O resultado é o seguinte:

Assim, temos códigos para inserir os seguintes dados separadamente:
- Os caracteres latinos em letras minúsculas.
- Os caracteres russos em letras minúsculas.
- Os dígitos.
Funciona para os tipos NCHAR e CHAR.
Da mesma forma, podemos preparar um script de inserção para qualquer conjunto de caracteres. Além disso, cada conjunto terá sua própria função de tabulação.
Para ser simples, implementamos a função de tabulação comum que retornará o conjunto de dados necessário para os dados selecionados anteriormente da seguinte maneira:
SELECT
'SELECT ' + CAST([ValueInt] AS NVARCHAR(255)) + ' AS [ValueInt], '
+ '''' + [ValueNChar] + '''' + ' AS [ValueNChar], '
+ COALESCE('''' + [ValueChar] + '''', ‘NULL’) + ' AS [ValueChar], '
+ CAST([IsNumeral] AS NCHAR(1)) + ' AS [IsNumeral], ' +
+CAST([IsUpperCase] AS NCHAR(1)) + ' AS [IsUpperCase], ' +
+CAST([IsLatin] AS NCHAR(1)) + ' AS [IsLatin], ' +
+CAST([IsRus] AS NCHAR(1)) + ' AS [IsRus], ' +
+CAST([IsExtra] AS NCHAR(1)) + ' AS [IsExtra]' +
+' UNION ALL'
FROM [test].[SelectCharactersCode];
O resultado final é o seguinte:

O script pronto é empacotado na função de tabulação [teste].[GetSelectCharacters].
É importante remover um UNION ALL extra no final do script gerado, e no [ValueInt]=39, precisamos alterar ”’ para ””:
SELECT 39 AS [ValueInt], '''' AS [ValueNChar], '''' AS [ValueChar], 0 AS [IsNumeral], 0 AS [IsUpperCase], 0 AS [IsLatin], 0 AS [IsRus], 1 AS [IsExtra] UNION ALLEsta função de tabulação retorna o seguinte conjunto de campos:
- Número – o número da linha no conjunto de dados retornado;
- ValueInt – o valor numérico do caractere;
- ValueNChar – o caractere do tipo NCHAR;
- ValueChar – o caractere do tipo CHAR;
- IsNumeral – o critério do caractere ser um dígito;
- IsUpperCase – o critério que define que o caractere está em maiúsculas;
- IsLatim – o critério que define que o caractere é um caractere latino;
- IsRus – o critério que define que o caractere é um caractere russo;
- ÉExtra – o critério que define que o personagem é um extra.
Para a entrada, você tem os seguintes parâmetros:
- @IsNumeral – se deve retornar os números;
- @IsUpperCase :
- 0 – deve retornar apenas as letras minúsculas;
- 1 – deve retornar apenas as letras maiúsculas;
- NULL – deve retornar letras em todos os casos.
- @IsLatin – deve retornar os caracteres latinos
- @IsRus – deve retornar os caracteres russos
- @IsExtra – deve retornar caracteres adicionais.
Todos os sinalizadores são usados de acordo com o OR lógico. Por exemplo, se você precisar ter dígitos e caracteres latinos em letras minúsculas retornados, chame a função de tabulação da seguinte maneira:
Obtemos o seguinte resultado:
declare
@IsNumeral BIT=1
,@IsUpperCase BIT=0
,@IsLatin BIT=1
,@IsRus BIT=0
,@IsExtra BIT=0;
SELECT *
FROM [test].[GetSelectCharacters](@IsNumeral, @IsUpperCase, @IsLatin, @IsRus, @IsExtra);
Obtemos o seguinte resultado:

Implementamos a função [test].[GetRandString] que substituirá a linha por caracteres pseudoaleatórios, mantendo o comprimento inicial da string. Esta função deve incluir a possibilidade de operar apenas os caracteres que são dígitos. Por exemplo, pode ser útil quando você altera a série e o número da carteira de identidade.
Quando implementamos a função [test].[GetRandString], primeiro obtemos o conjunto de caracteres necessários para gerar uma linha pseudo-aleatória de comprimento especificado no parâmetro de entrada @Length. Os demais parâmetros funcionam como descrito acima.
Em seguida, colocamos o conjunto de dados recebido na variável de tabulação @tbl . Esta tabela salva os campos [ID] – o número do pedido na tabela de caracteres resultante, e [Value] – a apresentação do caractere no tipo NCHAR.
Depois disso, em um ciclo, ele gera um número pseudoaleatório no intervalo de 1 à cardinalidade dos caracteres @tbl recebidos anteriormente. Colocamos esse número no [ID] da variável de tabulação @tbl para pesquisa. Quando a busca retorna a linha, pegamos o caractere [Value] e “colamos” na linha resultante @res.
Quando o trabalho do ciclo termina, a linha recebida é retornada através da variável @res.
Você pode alterar o nome e o sobrenome do candidato da seguinte maneira:
UPDATE [dbo].[Employee]
SET [FirstName] = [test].[GetRandString](LEN([FirstName])),
[LastName] = [test].[GetRandString](LEN([LastName]));
Assim, examinamos a implementação da função e seu uso para os tipos NCHAR e NVARCHAR. Podemos fazer o mesmo facilmente para os tipos CHAR e VARCHAR.
Às vezes, porém, precisamos gerar uma linha de acordo com o conjunto de caracteres, não com os caracteres alfabéticos ou números. Dessa forma, primeiro precisamos usar a seguinte função multi-operador [teste].[GetListCharacters].
A função [test].[GetListCharacters] obtém os dois parâmetros a seguir para a entrada:
- @str – a própria linha de caracteres;
- @IsGroupÚnico – define se precisa agrupar caracteres únicos na linha.
Com o CTE recursivo, a linha de entrada @str é transformada na tabela de caracteres – @ListCharacters. Essa tabela contém os seguintes campos:
- ID – o número do pedido da linha na tabela de caracteres resultante;
- Personagem – a apresentação do personagem em NCHAR(1)
- Contagem – o número de repetições do caractere na linha (é sempre 1 se o parâmetro @IsGroupUnique=0)
Vejamos dois exemplos de uso dessa função para entender melhor seu trabalho:
- Transformação da linha na lista de caracteres não exclusivos:
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 0);
Obtemos o resultado:

Este exemplo mostra que a linha é transformada na lista de caracteres “como está”, sem agrupá-la pela exclusividade dos caracteres (o campo [Count] sempre contém 1).
- A transformação da linha na lista de caracteres únicos
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 1);
O resultado é o seguinte:
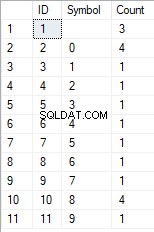
Este exemplo mostra que a linha é transformada na lista de caracteres agrupados por sua exclusividade. O campo [Contagem] exibe o número de descobertas de cada caractere na linha de entrada.
Com base na função multi-operador [teste].[GetListCharacters], criamos uma função escalar [teste].[GetRandString2].
A definição da nova função escalar mostra sua semelhança com a função escalar [test].[GetRandString]. A única diferença é que ele usa a função multioperador [teste].[GetListCharacters] em vez da função de tabulação [teste].[GetSelectCharacters].
Aqui, vamos analisar dois exemplos do uso de função escalar implementado :
Geramos uma linha pseudoaleatória de 12 caracteres a partir da linha de entrada de caracteres não agrupados por exclusividade:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', DEFAULT);O resultado é:
64017!!5!!!7
A palavra-chave é DEFAULT. Ele afirma que o valor padrão define o parâmetro. Aqui, é zero (0).
Ou
Geramos uma linha pseudo-aleatória com 12 caracteres de comprimento a partir da linha de entrada de caracteres agrupados por exclusividade:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', 1);O resultado é:
35792!428273
Implementação do script geral para sanitização de dados e alterações de dados secretos
Examinamos exemplos simples para cada tipo de dados alterados:
- Alterar a data e a hora;
- Alterar o valor numérico;
- Alterando a sequência de bytes;
- Alterando os dados dos personagens.
No entanto, esses exemplos não atendem aos critérios 2 e 3 para os scripts de alteração de dados:
- Critério 2 :a seletividade dos valores não mudará significativamente nos dados alterados. Você não pode usar NULL para o campo da tabela. Em vez disso, você deve garantir que os mesmos valores de dados reais permaneçam os mesmos nos dados alterados. Por exemplo, se os dados reais contiverem o valor 103785 12 vezes no campo de uma tabela sujeito a alterações, os dados modificados deverão incluir um valor diferente (alterado) encontrado 12 vezes no mesmo campo da tabela.
- Critério 3 :o comprimento e o tamanho dos valores não devem ser alterados significativamente nos dados alterados. Por exemplo, você substitui cada caractere/byte por um caractere/byte pseudoaleatório.
Assim, precisamos criar um script levando em consideração a seletividade dos valores nos campos da tabela.
Vamos dar uma olhada em nosso banco de dados para o serviço de recrutamento. Como vemos, os dados pessoais estão presentes apenas na tabela dos candidatos [dbo].[Employee].
Suponha que a tabela inclua os seguintes campos:
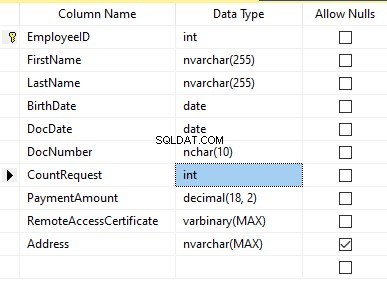
Descrições:
- Nome – nome, linha NVARCHAR(255)
- Sobrenome – sobrenome, linha NVARCHAR(255)
- Data de nascimento – data de nascimento, DATA
- DocNumber – o número do bilhete de identidade com dois dígitos no início para a série do passaporte, e os próximos sete dígitos são o número do documento. Entre eles, temos um hífen como a linha NCHAR(10).
- DocDate – a data de emissão do bilhete de identidade, DATA
- Solicitação de contagem – o número de solicitações para aquele candidato durante a busca por currículo, o inteiro INT
- Valor do pagamento – a taxa de serviço de promoção de currículo recebida, o número decimal (18,2)
- RemoteAccessCertificate – o certificado de acesso remoto, sequência de bytes VARBINARY
- Endereço – o endereço residencial ou o endereço de registro, linha NVARCHAR(MAX)
Então, para manter a seletividade inicial, precisamos implementar o seguinte algoritmo:
- Extraia todos os valores exclusivos de cada campo e mantenha os resultados em tabelas temporárias ou variáveis de tabulação;
- Gere um valor pseudoaleatório para cada valor único. Este valor pseudoaleatório não deve diferir significativamente em comprimento e tamanho do valor original. Salve o resultado no mesmo local onde salvamos os resultados do ponto 1. Cada valor recém-gerado deve ter um valor atual exclusivo correlacionado.
- Substitua todos os valores na tabela pelos novos valores do ponto 2.
No início, despersonalizamos o nome e sobrenome dos candidatos. Supomos que o sobrenome e o nome estejam sempre presentes e não tenham menos de dois caracteres em cada campo.
Primeiro, selecionamos nomes exclusivos. Em seguida, ele gera uma linha pseudoaleatória para cada nome. O comprimento do nome permanece o mesmo; o primeiro caractere está em maiúsculas e os outros caracteres estão em minúsculas. Usamos a função escalar [test].[GetRandString] criada anteriormente para gerar uma linha pseudo-aleatória de comprimento específico de acordo com os critérios de caracteres definidos.
Em seguida, atualizamos os nomes na tabela dos candidatos de acordo com seus valores exclusivos. É o mesmo para os sobrenomes.
Despersonalizamos o campo DocNumber. É o número do cartão de identificação (passaporte). Os dois primeiros caracteres representam a série do documento e os últimos sete dígitos são o número do documento. O hífen está entre eles. Em seguida, realizamos a operação de higienização.
Coletamos os números de todos os documentos exclusivos e geramos uma linha pseudoaleatória para cada um. O formato da linha é 'XX-XXXXXXX', onde X é o dígito no intervalo de 0 a 9. Aqui, usamos a função escalar [test].[GetRandString] criada anteriormente para gerar uma linha pseudo-aleatória de comprimento especificado de acordo com o conjunto de parâmetros dos personagens.
Depois disso, o campo [DocNumber] é atualizado na tabela de candidatos [dbo].[Employee].
Despersonalizamos o campo DocDate (data de emissão da carteira de identidade) e o campo BirthDate (data de nascimento do candidato).
Primeiro, selecionamos todos os pares únicos feitos de “data de nascimento e data de emissão da carteira de identidade”. Para cada um desses pares, criamos uma data pseudoaleatória para a data de nascimento. A data pseudoaleatória de emissão do BI é feita de acordo com essa “data de nascimento” – a data de emissão do documento não deve ser anterior à data de nascimento.
After that, these data are updated in the respective fields of the candidates’ table [dbo].[Employee].
And, we update the remaining fields of the table.
The CountRequest value stands for the number of requests made for that candidate by companies during the resume search.
The PaymentAmount is the final amount of the resume promotion service fee paid. We calculate these numbers similarly to the previous fields.
Note that it generates a pseudorandom integer for the first case and a pseudorandom decimal for the second case. In both cases, the pseudorandom number generation occurs in the range of “two times less than original” to “two times more than original.” The selectivity of values in the fields is not changed too much.
After that, it writes the values into the fields of the candidates’ table [dbo].[Employee].
Further, we collect unique values of the RemoteAccessCertificate field for the remote access certificate. We generate a pseudorandom byte sequence for each such value. The length of the sequence must be the same as the original. Here, we use the previously created [test].[GetRandVarbinary] scalar function to generate the pseudorandom byte sequence of the specified length.
Then recording into the respective field [RemoteAccessCertificate] of the [dbo].[Employee] candidates’ table takes place.
The last step is the collection of the unique addresses from the [Address] field. For each value, we generate a pseudorandom line of the same length as the original. Note that if it was NULL originally, it must be NULL in the generated field. It allows you to keep NULL and don’t replace it with an empty line. It minimizes the selectivity values’ mismatch in this field between the production database and the altered data.
We use the previously created [test].[GetRandString] scalar function to generate the pseudorandom line of the specified length according to the characters’ parameters defined.
It then records the data into the respective [Address] field of the candidates’ table [dbo].[Employee].
This way, we get the full script for depersonalization and altering of the confidential data.
Finally, we get the database with altered personal and confidential data. The algorithms we used make it impossible to restore the original data from the altered data. Also, the values’ selectivity, length, and size aren’t changed significantly. So, the three criteria for the personal and secret data altering scripts are ensured.
We won’t review the criterion 4 separately here. Our database contains all the data subject to change in one candidates’ table [dbo].[Employee]. The data conformity is needed within this table only. Thus, criterion 4 is also here. However, we need to remember this criterion 4 claiming that all interrelations must remain the same in the altered data.
We often see other conditions for personal and confidential data altering algorithms, but we won’t review them here. Besides, the four criteria described above are always present. In many cases, it is enough to estimate the functionality of the algorithm suitable to use it.
Now, we need to make a backup of the created database, check it by restoring on another instance, and transfer that copy into the necessary environment for development and testing. For this, we examine the full database backup creation.
Full database backup creation
We can make a database backup with construction BACKUP DATABASE as in our example.
Make a compressed full backup of the database JobEmplDB_Test. The checksum calculation takes place in the file E:\Backup\JobEmplDB_Test.bak. Further, we check the backup created.
Then, we check the backup created by restoring the database for it. Let’s examine the database restoring.
Restoring the database
You can restore the database with the help of RESTORE DATABASE construction in the following way:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the JobEmplDB_Test database of the E:\Backup\JobEmplDB_Test.bak backup. The files will be overwritten, and the data file will be transferred into the file E:\DBData\JobEmplDB.mdf , while the transactions log file will be moved into F:\DBLog\JobEmplDB_log.ldf .
After we successfully check how the database is restored from the backup, we forward the backup to the development and testing environments. It will be restored again with the same method as described above.
We’ve examined the first approach to the data populating into the database for testing and development. This approach implies copying and altering the data from the production database. Now, we’ll examine the second approach – the synthetic data generation.
Synthetic data generation
The General algorithm for the synthetic data generation is following:
- Make a new empty database or clear a previously created database by purging all data.
- Create or renew a scheme in the newly created database – the same as that of the production databases.
- Copy of renew guidelines and regulations from the production database and transfer them into the new database.
- Generate synthetic data into the necessary tables of the new database.
- Make a backup of a new database.
- Deliver and restore the new backup in the necessary environment.
We already have the JobEmplDB_Test database to practice, and we have reviewed the means of creating a schema in the new database. Let’s focus on the tasks that are specific to this approach.
Clean up the database with the data purge
To clear the database off all its data, we need to do the following:
- Keep the definitions of all external keys.
- Disable all limitations and triggers.
- Delete all external keys.
- Clear the tables using the TRUNCATE construction.
- Restore all the external keys deleted in point 3.
- Enable all the limitations disabled in point 2.
You can save the definitions of all external keys with the following script:
1. The external keys’ definitions are saved in the tabulation variable @tbl_create_FK
2. You can disable the limitations and triggers with the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? DISABLE TRIGGER ALL";
To enable the limitations and triggers, you can use the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? ENABLE TRIGGER ALL";
Here, we use the saved procedure sp_MSforeachtable that applies the construction to all the database’s tables.
3. To delete external keys, use the special script. Here, we receive the information about the external keys through the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system presentation. We delete external keys through the cursor, one by one, using the formed dynamic script T-SQL, transferring the request into the system saved procedure sp_executesql .
4. To clear the tables with the TRUNCATE construction, use the dedicated script. The script works in the same way as above, but it receives the data for tables, and then it clears the tables one by one through the cursor, using the TRUNCATE construction.
5. Restoring the external keys is possible with the below script (earlier, we saved the external keys’ definitions in the tabulation variable @tbl_create_FK):
DECLARE @tsql NVARCHAR(4000);
DECLARE FK_Create CURSOR LOCAL FOR SELECT
[Script]
FROM @tbl_create_FK;
OPEN FK_Create;
FETCH NEXT FROM FK_Create INTO @tsql;
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
FETCH NEXT FROM FK_Create INTO @tsql;
END
CLOSE FK_Create;
DEALLOCATE FK_Create;
The script works in the same way as the two other scripts we mentioned above. But it restores the external keys’ definitions through the cursor, one for each iteration.
A particular case of data purging in the database is the current script. To get this output, we need the below construction in the scripts:
EXEC sp_executesql @tsql = @tsql;Before this construction, or instead of it, we need to write the generated construction output. It is necessary to call it manually or via the dynamic T-SQL query. We do it via the system saved procedure sp_executesql.
Instead of the below code fragment in all cases:
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
...
We write:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
EXEC sp_executesql @tsql = @tsql;
...
Or:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
...
The first case implies both the output of constructions and their execution. The second case if for the output only – it is helpful for the scripts’ debugging.
Thus, we get the general database cleaning script.
Copy guidelines and references from the production database to the new one
Here you can use the T-SQL scripts. Our example database of the recruitment service includes 5 guidelines:
- [dbo].[Company] – companies
- [dbo].[Skill] – skills
- [dbo].[Position] – positions (occupation)
- [dbo].[Project] – projects
- [dbo].[ProjectSkill] – project and skills’ correlations
The “skills” table [dbo].[Skill] serves to show how to make a script for the data insertion from the production database into the test database.
We form the following script:
SELECT 'SELECT '+CAST([SkillID] AS NVARCHAR(255))+' AS [SkillID], '+''''+[SkillName]+''''+' AS [SkillName] UNION ALL'
FROM [dbo].[Skill]
ORDER BY [SkillID];
We execute it in a copy of the production database that is usually available in read-only mode. It is a replica of the production database.
The result is:
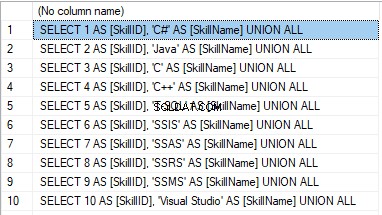
Now, wrap the result up into the script for the data adding as here. We have a script for the skills’ guideline compilation. The scripts for other guidelines are made in the same way.
However, it is much easier to copy the guidelines’ data through the data export and import in SSMS. Or, you can use the data import and export wizard.
Generate synthetic data
We’ve determined the pseudorandom values’ generation for lines, numbers, and byte sequences. It took place when we examined the implementation of the data sanitization and the confidential data altering algorithms for approach 1. Those implemented functions and scripts are also used for the synthetic data generation.
The recruitment service database requires us to fill the synthetic data in two tables only:
- [dbo].[Employee] – candidates
- [dbo].[JobHistory] – a candidate’s work history (experience), the resume itself
We can fill the candidates’ table [dbo].[Employee] with synthetic data using this script.
At the beginning of the script, we set the following parameters:
- @count – the number of lines to be generated
- @LengthFirstName – the name’s length
- @LengthLastName – the last name’s length
- @StartBirthDate – the lower limit of the date for the date of birth
- @FinishBirthDate – the upper limit of the date for the date of birth
- @StartCountRequest – the lower limit for the field [CountRequest]
- @FinishCountRequest – the upper limit for the field [CountRequest]
- @StartPaymentAmount – the lower limit for the field [PaymentAmount]
- @FinishPaymentAmount – the upper limit for the field [PaymentAmount]
- @LengthRemoteAccessCertificate – the byte sequence’s length for the certificate
- @LengthAddress – the length for the field [Address]
- @count_get_unique_DocNumber – the number of attempts to generate the unique document’s number [DocNumber]
The script complies with the uniqueness of the [DocNumber] field’s value.
Now, let’s fill the [dbo].[JobHistory] table with synthetic data as follows.
The start date of work [StartDate] is later than the issuing date of the candidate’s document [DocDate]. The end date of work [FinishDate] is later than the start date of work [StartDate].
It is important to note that the current script is simplified, as it does not deal with parameters of the generated data selectivity configuration.
Make a full database backup
We can make a database backup with the construction BACKUP DATABASE, using our script.
We create a full compressed backup of the database JobEmplDB_Test. The checksum is calculated into the file E:\Backup\JobEmplDB_Test.bak. It also ensures further testing of the backup.
Let’s check the backup by restoring the database from it. We need to examine the database restoring then.
Restore the database
You can restore the database with the help of the RESTORE DATABASE construction, as shown below:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the database JobEmplDB_Test from the backup E:\Backup\JobEmplDB_Test.bak. The files are overwritten, and the data file is transferred to the file E:\DBData\JobEmplDB.mdf. The transaction log file is transferred to file F:\DBLog\JobEmplDB_log.ldf.
After checking the database restoring from the backup successfully, we transfer the backup to the necessary environments. It will be used for testing and development, and further deployment through the database restoring, as described above.
This way, we’ve examined the second approach to filling the database in with data for testing and development purposes. It is the synthetic data generation approach.
Data generation tools (for external resources)
When we have a job to fill in the database with data for testing and development purposes, it can be much faster and easier with the help of specialized tools. Let’s review the most popular and powerful data generation tools and explore their practical usage.
Full list of tools
DATPROF
IRI RowGen
Data Generator for SQL Server
Redgate SQL Data Generator
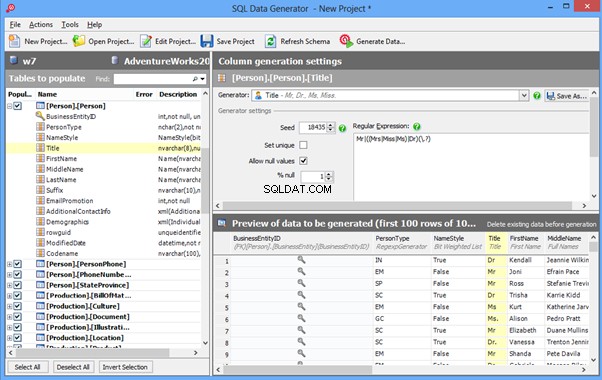
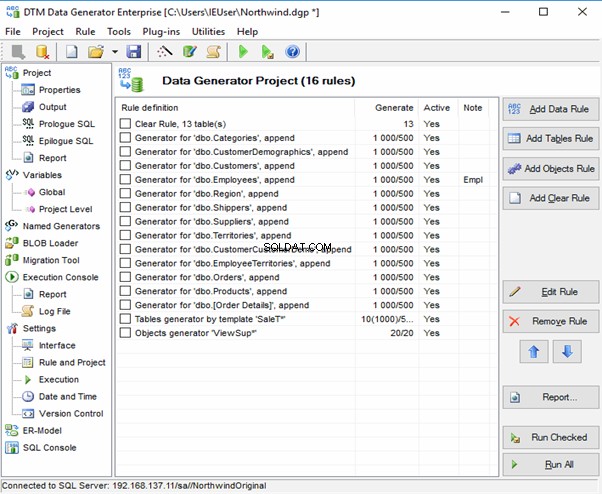
DTM Data Generator
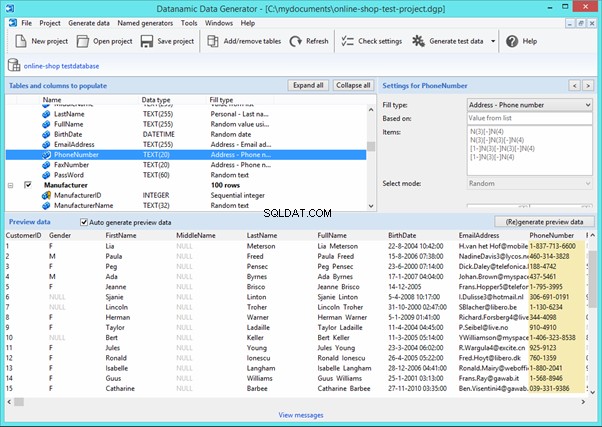
Datanamic Data Generator MultiDB
Now, let’s examine one of these tools more precisely.
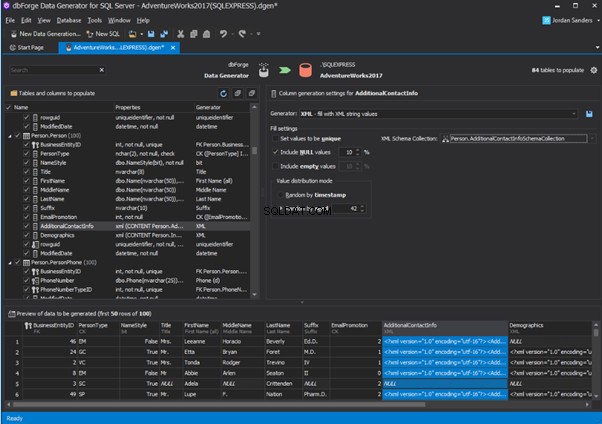
An overview of the employees’ generation by the Data Generator for SQL Server
The Data Generator for SQL Server utility is embedded in SSMS, and also it is a part of dbForge Studio. We reviewed this utility here. Let’s now examine how it works for synthetic data generation. As examples, we use the [dbo].[Employee] and the [dbo].[JobHistory] tables.
This generator can quickly generate first and last names of candidates for the [FirstName] and [LastName] fields respectively:
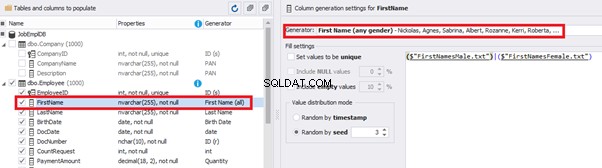
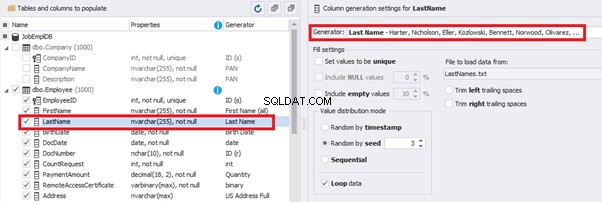
Note that FirstName requires choosing the “First Name” value in the “Generator” section. For LastName, you need to select the “Last Name” value from the “Generator” section.
It is important to note that the generator automatically determines which generation type it needs to apply to every field. The settings above were set by the generator itself, without manual correction.
You can configure distribution of values for the date of birth [BirthDate]:
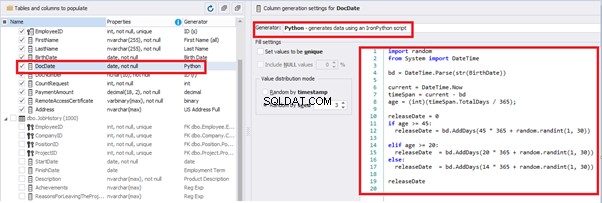
Set the distribution for the document’s date of issue [DocDate] through the Phyton generator using the below script:
import random
from System import DateTime
# receive the value from the Birthday field
bd = DateTime.Parse(str(BirthDate))
# receive the current date
current = DateTime.Now
# calculate the age in years
timeSpan = current - bd
age = (int)(timeSpan.TotalDays / 365);
# passport’s date of issue
releaseDate = 0
if age >= 45:
releaseDate = bd.AddDays(45 * 365 + random.randint(1, 30))
# randomize the issue during the month
elif age >= 20:
releaseDate = bd.AddDays(20 * 365 + random.randint(1, 30))
# randomize the issue during the month
else:
releaseDate = bd.AddDays(14 * 365 + random.randint(1, 30))
# randomize the issue during the month
releaseDateThis way, the [DocDate] configuration will look as follows:
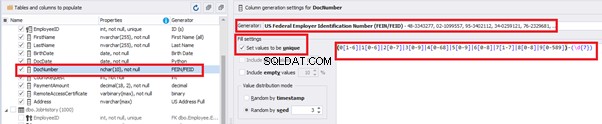
For the document’s number [DocNumber], we can select the necessary type of unique data generation, and edit the generated data format, if needed:
E.g., instead of the format
(0[1-6]|1[0-6]|2[0-7]|3[0-9]|4[0-68]|5[0-9]|6[0-8]|7[1-7]|8[0-8]|9[0-589])-(\d{7})We can set the following format:
(\d{2})-(\d{7})This format means that the line will be generated in format XX-XXXXXXX (X – is a digit in the range of 0 to 9).
We set up the generator for [CountRequest] and [PaymentAmount] fields in the same way, according to the generated data type:
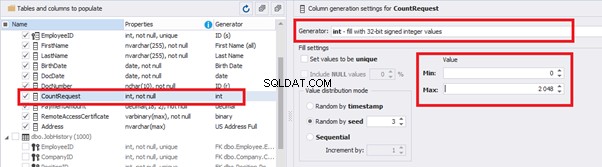
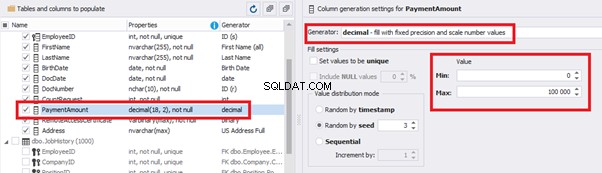
In the first case, we set the values’ range of 0 to 2048 for [CountRequest]. In the second case, it is the range of 0 to 100000 for [PaymentAmount].
We configure generation for [RemoteAccessCertificate] and [Address] fields in the same way:
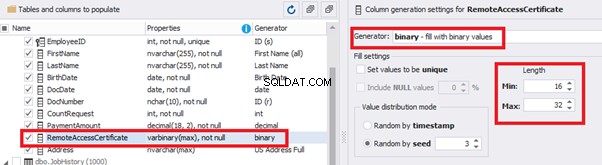
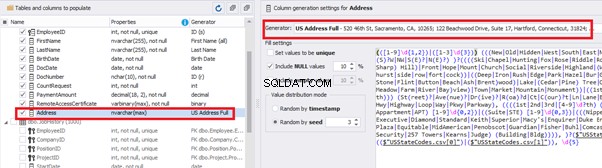
In the first case, we limit the byte sequence [RemoteAccessCertificate] with the range of lengths of 16 to 32. In the second case, we select values for [Address] as real addresses. It makes the generated values looking like the real ones.
This way, we’ve configured the synthetic data generation settings for the candidates’ table [dbo].[Employee]. Let’s now set up the synthetic data generation for the [dbo].[JobHistory] table.
We set it to take the data for the [EmployeeID] field from the candidates’ table [dbo].[Employee] in the following way:
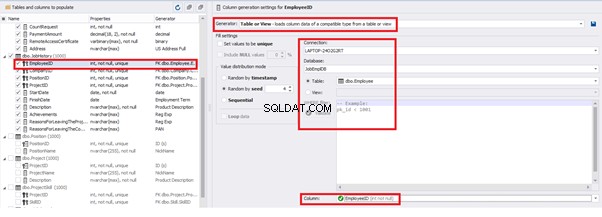
We select the generator’s type from the table or presentation. We then define the sample of MS SQL Server, the database, and the table to take the data from. We can also configure filters in the “WHERE filter” section, and select the [EmployeeID] field.
Here we suppose that we generate the “employees” first, and then we generate the data for the [dbo].[JobHistory] table, basing on the filled [dbo].[Employee] reference.
However, if we need to generate the data for both [dbo].[Employee] and [dbo].[JobHistory] at the same time, we need to select “Foreign Key (manually assigned) – references a column from the parent table,” referring to the [dbo].[Employee].[EmployeeID] column:
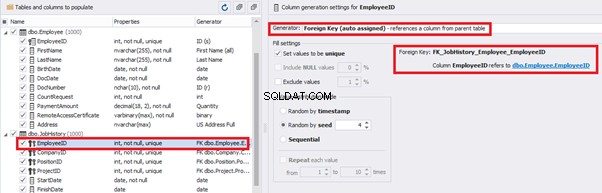
Similarly, we set up the data generation for the following fields.
[CompanyID] – from [dbo].[Company], the “companies” table:
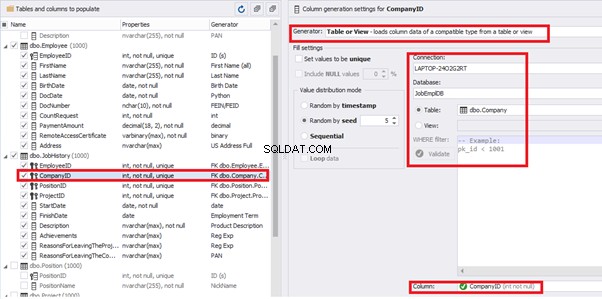
[PositionID] – from the table of positions [dbo].[Position]:
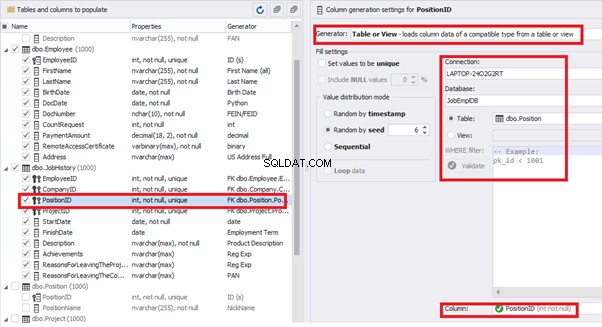
[ProjectID] – from the table of projects [dbo].[Project]:
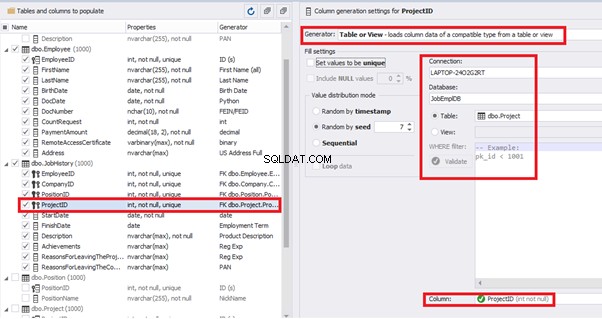
The tool cannot link the columns from different tables and shift them in some way. However, the generator can shift the date within one table – the “date” generator – fill with date values with Range – Offset from the column. Also, it can use data from a different table, but without any transformation (Table or View, SQL query, Foreign key generators).
That’s why we resolve the dates’ problem (BirthDate
E.g., we limit the BirthDate with the 40-50 years’ interval. Then, we restrict the DocDate with 20-40 years’ interval. The StartDate is, respectively, limited with 25-35 years’ interval, and we set up the FinishDate with the offset from StartDate.
We set up the date of birth:
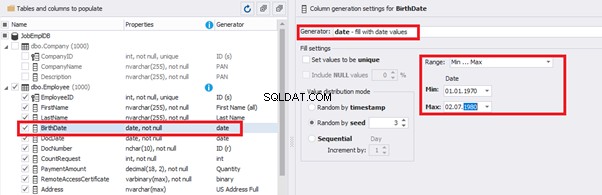
Set up the date of the document’s issue
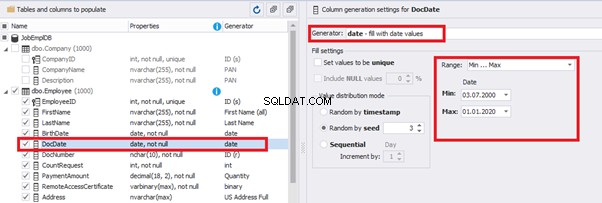
Then, the StartDate will match the age from 35 to 45:
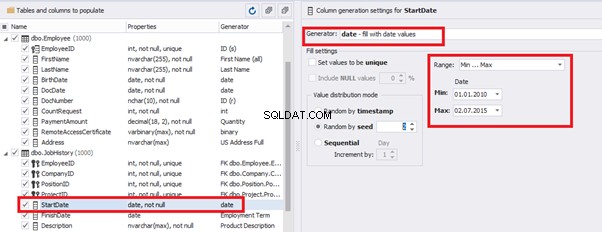
The simple offset generator sets FinishDate:
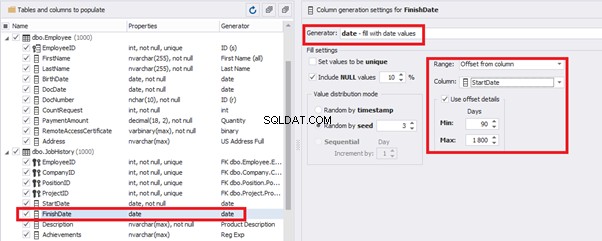
The result is, a person has worked for three months till the current date.
Also, to configure the date of the working end, we can use a small Python script:
import random
from System import DateTime
bd = DateTime.Parse(str(StartDate))
releaseDate = bd.AddDays(random.randint(1, 30))
releaseDateThis way, we receive the below configuration for the dates of work end [FinishDate] data generation:
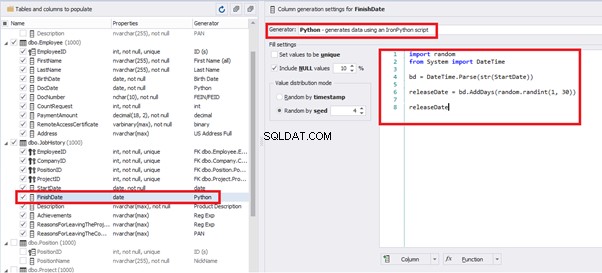
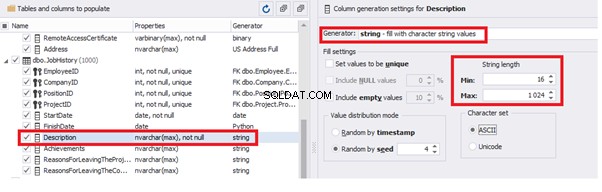
Similarly, we fill in the rest of fields. We set the generator type – string, and set the range for generated lines’ lengths:
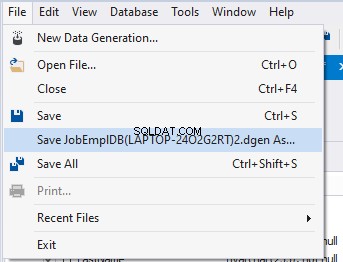
Also, you can save the data generation project as dgen-file consisting of:
- Connection;
- The database name;
- All settings for bases, tables, and columns;
- All settings of generators by columns, etc.
We can save all these settings:it is enough to keep the project’s file and work with the database further, using that file:
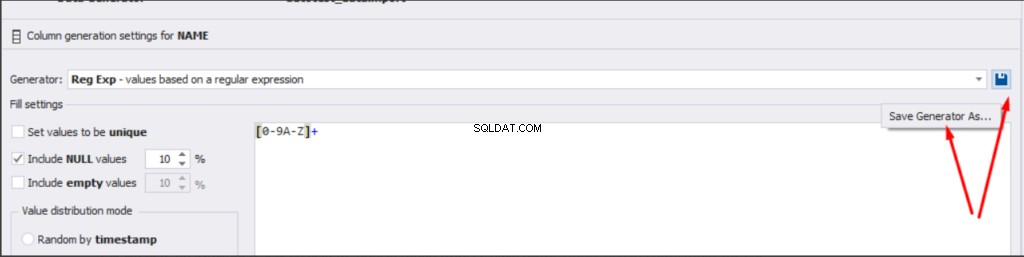
There is also the possibility to both save the new generators from scratch and save the custom settings in a new generator:
Thus, we’ve configured the synthetic data generation settings used for the jobs’ history table [dbo].[JobHistory].
Conclusion
We have examined two approaches to filling the data in the database for testing and development:
- Copying and changing the data from the production database
- Synthetic data generation
We’ve defied the objects for each approach and each script implementation. These objects are here. We’ve also provided scripts for changing the data from the production database and synthetic data generation. An example is the database of recruitment services. In the end, we’ve examined popular data generation tools and explored one of these tools in detail.
References
SQL SERVER – How to Disable and Enable All Constraint for Table and Database
Microsoft TechNet Wiki
Top 10 Best Test Data Generation Tools In 2020
SQL Server Documentation