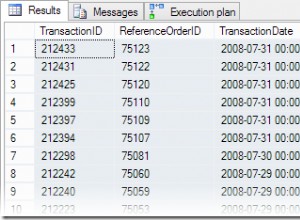
300k linhas não é uma tabela enorme. Frequentemente vemos 300 milhões de tabelas de linhas.
O maior problema com sua consulta é que você está usando uma subconsulta correlacionada, então ela precisa executar novamente a subconsulta para cada linha na consulta externa.
Muitas vezes, você não precisa fazer tudo seu trabalho em uma instrução SQL. Há vantagens em dividi-lo em várias instruções SQL mais simples:
- Mais fácil de codificar.
- Mais fácil de otimizar.
- Mais fácil de depurar.
- Mais fácil de ler.
- Mais fácil de manter se/quando você precisar implementar novos requisitos.
Número de compras
SELECT customer, COUNT(sale) AS number_of_purchases
FROM sales
GROUP BY customer;
Um índice de vendas (cliente, venda) seria melhor para essa consulta.
Valor da última compra
Este é o maior-n-per-group problema que aparece com frequência.
SELECT a.customer, a.sale as max_sale
FROM sales a
LEFT OUTER JOIN sales b
ON a.customer=b.customer AND a.dates < b.dates
WHERE b.customer IS NULL;
Em outras palavras, tente corresponder à linha
a para uma linha hipotética b que tem o mesmo cliente e uma data maior. Se nenhuma linha for encontrada, então a deve ter a maior data para esse cliente. Um índice de vendas (cliente, datas, venda) seria melhor para essa consulta.
Se você tiver mais de uma venda para um cliente nessa data máxima, essa consulta retornará mais de uma linha por cliente. Você precisaria encontrar outra coluna para desempate. Se você usar uma chave primária de incremento automático, ela é adequada como desempate porque é garantida como exclusiva e tende a aumentar cronologicamente.
SELECT a.customer, a.sale as max_sale
FROM sales a
LEFT OUTER JOIN sales b
ON a.customer=b.customer AND (a.dates < b.dates OR a.dates = b.dates and a.id < b.id)
WHERE b.customer IS NULL;
Valor total de compras, quando tem valor positivo
SELECT customer, SUM(sale) AS total_purchases
FROM sales
WHERE sale > 0
GROUP BY customer;
Um índice de vendas (cliente, venda) seria melhor para essa consulta.
Você deve considerar usar NULL para significar um valor de venda ausente em vez de -1. Funções agregadas como SUM() e COUNT() ignoram NULLs, então você não precisa usar uma cláusula WHERE para excluir linhas com venda <0.
Re:seu comentário
Cinco principais clientes do quarto trimestre de 2012
SELECT customer, SUM(sale) AS total_purchases
FROM sales
WHERE (year, quarter) = (2012, 4) AND sale > 0
GROUP BY customer
ORDER BY total_purchases DESC
LIMIT 5;
Eu gostaria de testá-lo em relação a dados reais, mas acredito que um índice de vendas (ano, trimestre, cliente, venda) seria melhor para essa consulta.
Última compra para clientes com total de compras> 5
SELECT a.customer, a.sale as max_sale
FROM sales a
INNER JOIN sales c ON a.customer=c.customer
LEFT OUTER JOIN sales b
ON a.customer=b.customer AND (a.dates < b.dates OR a.dates = b.dates and a.id < b.id)
WHERE b.customer IS NULL
GROUP BY a.id
HAVING COUNT(*) > 5;
Como na outra consulta de maior n por grupo acima, um índice de vendas (cliente, datas, venda) seria melhor para essa consulta. Provavelmente, ele não pode otimizar tanto a junção quanto o grupo, portanto, isso incorrerá em uma tabela temporária. Mas pelo menos fará apenas uma tabela temporária em vez de muitas.
Essas consultas são complexas o suficiente. Você não deve tentar escrever uma única consulta SQL que possa fornecer todos desses resultados. Lembre-se da citação clássica de Brian Kernighan: