Você pergunta sobre Como eu calculo quais são as cidades mais próximas? Por exemplo. Se eu estivesse olhando para a cidade 1 (Paris), os resultados seriam:Londres (2), Nova York (3) e com base no conjunto de dados fornecido, há apenas uma coisa a relacionar que são as tags comuns entre as cidades, portanto, as cidades que compartilham as tags comuns seriam a mais próxima abaixo é a subconsulta que encontra as cidades (além da que é fornecida para encontrar suas cidades mais próximas) que compartilha as tags comuns
SELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Trabalhando
Suponho que você inserirá um dos id ou nome da cidade para encontrar o mais próximo no meu caso "Paris" tem o id
SELECT tag_id FROM `cities_tags` WHERE city_id=1
Ele encontrará todos os IDs de tags que Paris tem então
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Ele irá buscar todas as cidades exceto paris que tem as mesmas tags que paris também tem
Aqui está o seu Fiddle
Ao ler sobre a semelhança/índice de Jaccard encontrei algumas coisas para entender sobre o que realmente são os termos, vamos dar este exemplo, temos dois conjuntos A e B
Agora vá em direção ao seu cenário
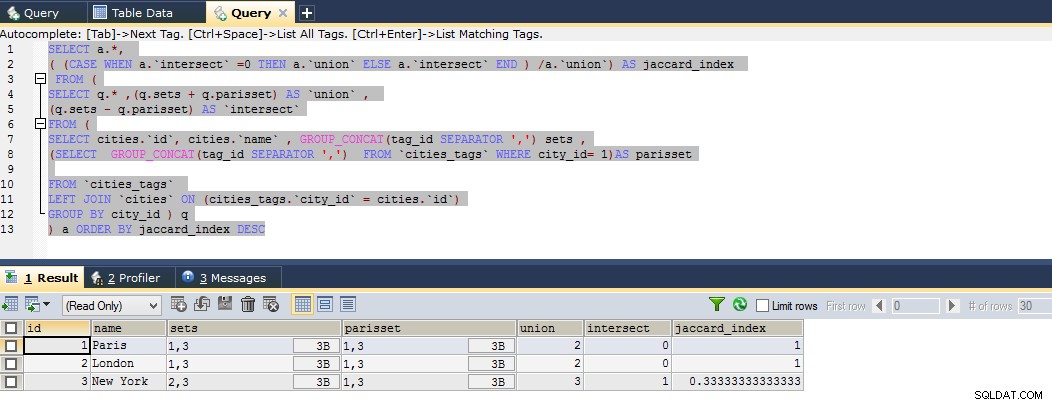
Aqui está a consulta até agora que calcula o índice jaccard perfeito, você pode ver o exemplo de violino abaixo
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Na consulta acima, tenho derivado o resultado definido para duas subseleções para obter meus aliases calculados personalizados
Você pode adicionar o filtro na consulta acima para não calcular a semelhança com ele mesmo
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Portanto, o resultado mostra que Paris está intimamente relacionada a Londres e depois relacionada a Nova York
Jaccard Similarity Fiddle