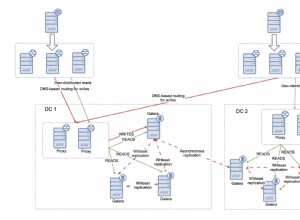
Esses dados são normalizados
TABLE { FIELDS }
-----------------------------------------------------------------------
building { id, data }
floor { id, building_id, data }
room {id, floor_id, data }
bed {id, room_id, data }
Esta mesa não é (má ideia)
TABLE { FIELDS }
-----------------------------------------------------------------------
building { id, data }
floor { id, building_id, data }
room {id, building_id, floor_id, data }
bed {id, building_id, floor_id, room_id, data }
- Na primeira (boa) tabela você não tem dados duplicados desnecessários.
- As inserções na primeira tabela serão muito mais rápidas.
- As primeiras tabelas caberão mais facilmente na memória, agilizando suas consultas.
- O InnoDB é otimizado com o modelo A em mente, não com o modelo B.
- A última tabela (ruim) tem dados duplicados, se que fica fora de sincronia, você terá uma bagunça. DB A não é muito mais difícil de sair de sincronia, porque os dados são listados apenas uma vez.
- Se eu quiser combinar dados do prédio, andar, quarto e cama vou precisar combinar todas as quatro mesas no modelo A assim como no modelo B, como você está economizando tempo aqui.
- O InnoDB armazena dados indexados em seu próprio arquivo, se você
selectapenas índices , as próprias tabelas nunca ser acessado. Então, por que você está duplicando os índices? O MySQL nunca precisará ler a tabela principal de qualquer maneira. - O InnoDB armazena o PK em cada índice secundário , com um PK composto e, portanto, longo, você está diminuindo a velocidade de cada seleção que usa um índice e aumentando o tamanho do arquivo; para nenhum ganho que assim nunca.
- Você tem sério problema de velocidade? Se não, você está desnormalizando suas tabelas?
- Nem pense em usar o MyISAM, que sofre menos com esses problemas, ele não é otimizado para bancos de dados de junção múltipla e não suporta integridade referencial ou transações e é uma combinação ruim para essa carga de trabalho.
- Ao usar uma chave composta, você só pode usar a parte mais à direita da chave, ou seja, não pode usar
floor_idna tabelabedalém de usarid+building_id+floor_id, Isso significa que você pode ter que usar muito mais espaço de chave do que o necessário no Modelo A. Ou isso ou você precisa adicionar um índice extra (que arrastará uma cópia completa do PK).
Resumindo
Eu vejo absolutamente zero benefício e muitas desvantagens no Modelo B, nunca use!