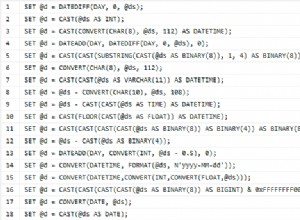
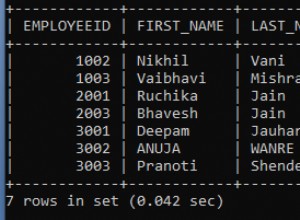
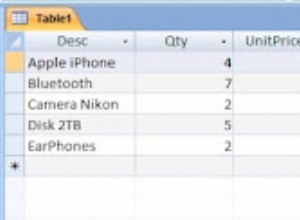
Uma abordagem é observar a Distância Levenshtein entre o termo de pesquisa e a lista de palavras-chave. Existem alguns poucos exemplos de como implementar isso no MySQL, por exemplo. AQUI
Como você tem um catálogo tão grande, precisará primeiro analisar a implementação de um filtro (talvez com base em uma pesquisa 'LIKE') para não medir a distância para todas as linhas de 1 milhão.
Se você classificar os resultados por distância, poderá classificar os resultados por relevância para a pesquisa.