Introdução
Agora suas condições de correspondência podem ser muito amplas. No entanto, você pode usar a distância levenshtein para verificar suas palavras. Pode não ser muito fácil cumprir todos os objetivos desejados com ele, como semelhança de som. Assim, estou sugerindo dividir seu problema em alguns outros problemas.
Por exemplo, você pode criar algum verificador personalizado que usará a entrada passível de chamada que recebe duas strings e, em seguida, responde a perguntas sobre se elas são iguais (para
levenshtein que será a distância menor que algum valor, para similar_text - algum percentual de similaridade e t.c. - cabe a você definir regras). Semelhança, baseada em palavras
Bem, todas as funções internas falharão se estivermos falando de case quando você estiver procurando por correspondência parcial - especialmente se for sobre correspondência não ordenada. Assim, você precisará criar uma ferramenta de comparação mais complexa. Você tem:
- String de dados (que estará no banco de dados, por exemplo). Parece D =D0 D1 D2 ... Dn
- String de pesquisa (que será a entrada do usuário). Parece S =S0 S1 ... Sm
Aqui, símbolos de espaço significam qualquer espaço (presumo que símbolos de espaço não afetarão a similaridade). Também
n > m . Com esta definição, seu problema é - encontrar o conjunto de m palavras em D que será semelhante a S . Por set Refiro-me a qualquer sequência não ordenada. Portanto, se encontrarmos qualquer sequência em D , então S é semelhante a D . Obviamente, se
n < m então a entrada contém mais palavras do que a string de dados. Nesse caso, você pode pensar que eles não são semelhantes ou agir como acima, mas alternar dados e entrada (que, no entanto, parece um pouco estranho, mas é aplicável em algum sentido) Implementação
Para fazer as coisas, você precisará criar um conjunto de strings que são partes de
m palavras de D . Com base na minha esta pergunta
você pode fazer isso com:protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-so para qualquer array,
getAssoc() retornará um array de seleções não ordenadas consistindo de m itens cada. O próximo passo é sobre a ordem na seleção produzida. Devemos pesquisar tanto
Niels Andersen e Andersen Niels em nosso D corda. Portanto, você precisará ser capaz de criar permutações para array. É um problema muito comum, mas vou colocar minha versão aqui também:protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Depois disso, você poderá criar seleções de
m palavras e, em seguida, permutando cada uma delas, obtenha todas as variantes para comparar com a string de pesquisa S . Essa comparação sempre será feita por meio de algum retorno de chamada, como levenshtein . Aqui está amostra:public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Isso verificará a semelhança, com base no retorno de chamada do usuário, que deve aceitar pelo menos dois parâmetros (ou seja, strings comparadas). Além disso, você pode querer retornar a string que acionou o retorno positivo de callback. Por favor, note que este código não diferirá em maiúsculas e minúsculas - mas pode ser que você não queira tal comportamento (então apenas substitua
strtolower() ). A amostra do código completo está disponível esta listagem (Eu não usei o sandbox, pois não tenho certeza de quanto tempo a listagem de códigos estará disponível lá). Com este exemplo de uso:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
você obterá resultados como:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-aqui é demo para este código, apenas no caso.
Complexidade
Como você está se preocupando não apenas com qualquer método, mas também com - quão bom é, você pode notar, que esse código produzirá operações bastante excessivas. Quero dizer, pelo menos, geração de partes de cordas. A complexidade aqui consiste em duas partes:
- Parte de geração de partes de strings. Se você quiser gerar todas as partes da string - você terá que fazer isso como descrevi acima. Possível ponto a melhorar - geração de conjuntos de strings não ordenados (que vem antes da permutação). Mas ainda duvido que isso possa ser feito porque o método no código fornecido os gerará não com "força bruta", mas como são calculados matematicamente (com cardinalidade de
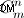 )
) - Parte de verificação de similaridade. Aqui sua complexidade depende do verificador de similaridade fornecido. Por exemplo,
similar_text()tem complexidade O(N), portanto, com grandes conjuntos de comparação, será extremamente lento.
Mas você ainda pode melhorar a solução atual com a verificação em tempo real. Agora este código irá primeiro gerar todas as subsequências de strings e então começar a verificá-las uma a uma. Em casos comuns você não precisa fazer isso, então você pode querer substituir isso por comportamento, quando depois de gerar a próxima sequência ela será verificada imediatamente. Então você aumentará o desempenho para strings que têm resposta positiva (mas não para aquelas que não têm correspondência).