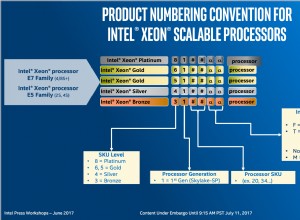
Sua consulta é sintaxe perfeitamente legal, você pode ordenar por colunas que não estão presentes no select.
- Demonstração de trabalho com MySQL
- Demonstração de trabalho com SQL Server
- Demonstração de trabalho com Postgresql
- Demonstração de trabalho com SQLite
- Demonstração de trabalho com Oracle
Se você precisar das especificações completas sobre ordenação legal, no SQL Standard 2003 há uma longa lista de declarações sobre o que a ordem deve e não deve conter (02-Foundation, página 415, seção 7.13
Acho que sua confusão pode estar surgindo ao selecionar e/ou ordenar por colunas não presentes no grupo por, ou ordenar por colunas que não estão no select ao usar distinct.
Ambos têm o mesmo problema fundamental, e o MySQL é o único que eu saiba que permite ambos.
O problema é que, ao usar group by ou distinct, quaisquer colunas não contidas em nenhum dos dois não são necessárias, portanto, não importa se eles têm vários valores diferentes nas linhas porque nunca são necessários. Imagine este conjunto de dados simples:
ID | Column1 | Column2 |
----|---------+----------|
1 | A | X |
2 | A | Z |
3 | B | Y |
Se você escrever:
SELECT DISTINCT Column1
FROM T;
Você iria conseguir
Column1
---------
A
B
Se você adicionar
ORDER BY Column2 , qual das duas colunas2 você usaria para ordenar A por, X ou Z? Não é determinístico como escolher um valor para a coluna2. O mesmo se aplica à seleção de colunas que não estão no grupo por. Para simplificar as coisas, imagine as duas primeiras linhas da tabela anterior:
ID | Column1 | Column2 |
----|---------+----------|
1 | A | X |
2 | A | Z |
No MySQL você pode escrever
SELECT ID, Column1, Column2
FROM T
GROUP BY Column1;
Isso realmente quebra o padrão SQL, mas funciona no MySQL, no entanto, o problema é que não é determinístico, o resultado:
ID | Column1 | Column2 |
----|---------+----------|
1 | A | X |
Não é mais ou menos correto do que
ID | Column1 | Column2 |
----|---------+----------|
2 | A | Y |
Então, o que você está dizendo é me dar uma linha para cada valor distinto de
Column1 , que ambos os conjuntos de resultados satisfazem, então como você sabe qual deles você obterá? Bem, você não sabe, parece ser um equívoco bastante popular que você pode adicionar e ORDER BY cláusula para influenciar os resultados, por exemplo, a seguinte consulta:SELECT ID, Column1, Column2
FROM T
GROUP BY Column1
ORDER BY ID DESC;
Certifique-se de obter o seguinte resultado:
ID | Column1 | Column2 |
----|---------+----------|
2 | A | Y |
por causa do
ORDER BY ID DESC , mas isso não é verdade (como demonstrado aqui
). Os documentos MySQL Estado:
Portanto, mesmo que você tenha uma ordem, isso não se aplica até que uma linha por grupo tenha sido selecionada, e essa linha não é determística.
O SQL-Standard não permite colunas na lista de seleção não contidas no GROUP BY ou em uma função de agregação, no entanto, essas colunas devem ser funcionalmente dependentes de uma coluna no GROUP BY. Do SQL-2003-Standard (5WD-02-Foundation-2003-09 - página 346) - http ://www.wiscorp.com/sql_2003_standard.zip
Por exemplo, o ID na tabela de amostra é a PRIMARY KEY, então sabemos que é único na tabela, então a consulta a seguir está em conformidade com o padrão SQL e seria executada no MySQL e falharia em muitos DBMS atualmente (no momento da escrita do Postgresql é o DBMS mais próximo que conheço para implementar corretamente o padrão - Exemplo aqui ):
SELECT ID, Column1, Column2
FROM T
GROUP BY ID;
Como o ID é exclusivo para cada linha, só pode haver um valor de
Column1 para cada ID, um valor de Column2 não há ambiguidade sobre o que retornar para cada linha.