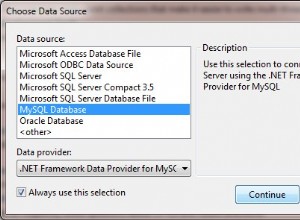
SELECT COUNT(*)
FROM tbl
WHERE HEX(col) REGEXP '^(..)*(E[2-9F]|F0A)'
irá contar o número de registros com caracteres chineses na coluna
col . Problemas:
- Não tenho certeza de quais intervalos hexadecimais representam o chinês.
- O teste pode incluem coreano e japonês. ("CJK")
- No MySQL, os caracteres chineses de 4 bytes precisam de
utf8mb4em vez deutf8.
Elaboração
Estou assumindo que a coluna na tabela é
CHARACTER SET utf8 . Na codificação utf8, os caracteres chineses começam com um byte entre hexadecimal E2 e E9, ou EF ou F0. Aqueles que começam com hex E terão 3 bytes de comprimento, mas não estou verificando o comprimento; os F0 serão de 4 bytes. O regexp começa com
^(..)* , significando "desde o início da string (^ ), localize 0 ou mais (* ) 2 caracteres (.. ) valores. Depois disso deve ser E -algo ou F0A . Depois disso, tudo pode acontecer. O E-algo é, mais especificamente, E seguido por qualquer um de 2,3,4,5,6,7,8,9 ou F. Selecionado aleatoriamente, vejo que
草 codifica como os 3 bytes hexadecimais E88D89 e 𠜎 codifica como os 4 bytes hexadecimais F0A09C8E . Não conheço uma maneira melhor de verificar uma string para um idioma específico.
Como você descobriu, o REGEXP pode ser bastante lento.
Esse regexp pode ser exagerado, pois alguns caracteres não chineses podem ser capturados.