Esta é uma grande pergunta. O InnoDB é um mecanismo de bloqueio em nível de linha, mas precisa definir bloqueios adicionais para garantir a segurança com o log binário (usado para replicação; recuperação pontual). Para começar a explicá-lo, considere o seguinte exemplo (ingênuo):
session1> START TRANSACTION;
session1> DELETE FROM users WHERE is_deleted = 1; # 1 row matches (user_id 10), deleted.
session2> START TRANSACTION;
session2> UPDATE users SET is_deleted = 1 WHERE user_id = 5; # 1 row matches.
session2> COMMIT;
session1> COMMIT;
Como as instruções são gravadas no log binário apenas uma vez confirmadas, na sessão escrava #2 seria aplicada primeiro e produziria um resultado diferente, levando à corrupção de dados .
Então, o que o InnoDB faz é definir bloqueios adicionais. Se
is_deleted é indexado, então antes de session1 confirmar ninguém mais poderá modificar ou inserir no intervalo de registros onde is_deleted=1 . Se não houver índices em is_deleted , o InnoDB precisa bloquear todas as linhas da tabela inteira para garantir que a reprodução esteja na mesma ordem. Você pode pensar nisso como bloqueando a lacuna , que é um conceito diferente para entender diretamente do bloqueio em nível de linha . No seu caso com esse
ORDER BY position ASC , o InnoDB precisa garantir que nenhuma nova linha possa ser modificada entre o valor de chave mais baixo e um valor mais baixo possível "especial". Se você fez algo como ORDER BY position DESC .. bem, então ninguém poderia inserir neste intervalo. Aqui vem a solução:
-
O log binário baseado em declaração é uma merda. Estou realmente ansioso por um futuro em que todos mudemos para a linha registro binário baseado (disponível no MySQL 5.1, mas não ativado por padrão).
-
Com a replicação baseada em linha, se você alterar o nível de isolamento para confirmação de leitura, somente a linha correspondente precisará ser bloqueada.
-
Se você quer ser masoquista, também pode ativar innodb_locks_unsafe_for_binlog com replicação baseada em instrução.
Atualização em 22 de abril :Para copiar + colar minha versão aprimorada do seu caso de teste (não estava pesquisando 'na lacuna'):
session1> CREATE TABLE test (id int not null primary key auto_increment, data1 int, data2 int, INDEX(data1)) engine=innodb;
Query OK, 0 rows affected (0.00 sec)
session1> INSERT INTO test VALUES (NULL, 1, 2), (NULL, 2, 1), (5, 2, 2), (6, 3, 3), (3, 3, 4), (4, 4, 3);
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
session1> start transaction;
Query OK, 0 rows affected (0.00 sec)
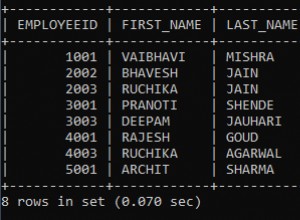
session1> SELECT id FROM test ORDER BY data1 LIMIT 1 FOR UPDATE;
+----+
| id |
+----+
| 1 |
+----+
1 row in set (0.00 sec)
session2> INSERT INTO test values (NULL, 0, 99); # blocks - 0 is in the gap between the lowest value found (1) and the "special" lowest value.
# At the same time, from information_schema:
localhost information_schema> select * from innodb_locks\G
*************************** 1. row ***************************
lock_id: 151A1C:1735:4:2
lock_trx_id: 151A1C
lock_mode: X,GAP
lock_type: RECORD
lock_table: `so5694658`.`test`
lock_index: `data1`
lock_space: 1735
lock_page: 4
lock_rec: 2
lock_data: 1, 1
*************************** 2. row ***************************
lock_id: 151A1A:1735:4:2
lock_trx_id: 151A1A
lock_mode: X
lock_type: RECORD
lock_table: `so5694658`.`test`
lock_index: `data1`
lock_space: 1735
lock_page: 4
lock_rec: 2
lock_data: 1, 1
2 rows in set (0.00 sec)
# Another example:
select * from test where id < 1 for update; # blocks